 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining multiple post-training techniques to achieve most efficient quantized LLMs
May 12, 2024Large Language Models (LLMs) have distinguished themselves with outstanding performance in complex language modeling tasks, yet they come with significant computational and storage challenges. This paper explores the potential of quantization to mitigate these challenges. We systematically study the combined application of two well-known post-training techniques, SmoothQuant and GPTQ, and provide a comprehensive analysis of their interactions and implications for advancing LLM quantization. We enhance the versatility of both techniques by enabling quantization to microscaling (MX) formats, expanding their applicability beyond their initial fixed-point format targets. We show that by applying GPTQ and SmoothQuant, and employing MX formats for quantizing models, we can achieve a significant reduction in the size of OPT models by up to 4x and LLaMA models by up to 3x with a negligible perplexity increase of 1-3%.
PrivSGP-VR: Differentially Private Variance-Reduced Stochastic Gradient Push with Tight Utility Bounds
May 04, 2024



In this paper, we propose a differentially private decentralized learning method (termed PrivSGP-VR) which employs stochastic gradient push with variance reduction and guarantees $(\epsilon, \delta)$-differential privacy (DP) for each node. Our theoretical analysis shows that, under DP Gaussian noise with constant variance, PrivSGP-VR achieves a sub-linear convergence rate of $\mathcal{O}(1/\sqrt{nK})$, where $n$ and $K$ are the number of nodes and iterations, respectively, which is independent of stochastic gradient variance, and achieves a linear speedup with respect to $n$. Leveraging the moments accountant method, we further derive an optimal $K$ to maximize the model utility under certain privacy budget in decentralized settings. With this optimized $K$, PrivSGP-VR achieves a tight utility bound of $\mathcal{O}\left( \sqrt{d\log \left( \frac{1}{\delta} \right)}/(\sqrt{n}J\epsilon) \right)$, where $J$ and $d$ are the number of local samples and the dimension of decision variable, respectively, which matches that of the server-client distributed counterparts, and exhibits an extra factor of $1/\sqrt{n}$ improvement compared to that of the existing decentralized counterparts, such as A(DP)$^2$SGD. Extensive experiments corroborate our theoretical findings, especially in terms of the maximized utility with optimized $K$, in fully decentralized settings.
Tele-FLM Technical Report
Apr 25, 2024



Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
Optimizing OOD Detection in Molecular Graphs: A Novel Approach with Diffusion Models
Apr 24, 2024



The open-world test dataset is often mixed with out-of-distribution (OOD) samples, where the deployed models will struggle to make accurate predictions. Traditional detection methods need to trade off OOD detection and in-distribution (ID) classification performance since they share the same representation learning model. In this work, we propose to detect OOD molecules by adopting an auxiliary diffusion model-based framework, which compares similarities between input molecules and reconstructed graphs. Due to the generative bias towards reconstructing ID training samples, the similarity scores of OOD molecules will be much lower to facilitate detection. Although it is conceptually simple, extending this vanilla framework to practical detection applications is still limited by two significant challenges. First, the popular similarity metrics based on Euclidian distance fail to consider the complex graph structure. Second, the generative model involving iterative denoising steps is time-consuming especially when it runs on the enormous pool of drugs. To address these challenges, our research pioneers an approach of Prototypical Graph Reconstruction for Molecular OOD Detection, dubbed as PGR-MOOD and hinges on three innovations: i) An effective metric to comprehensively quantify the matching degree of input and reconstructed molecules; ii) A creative graph generator to construct prototypical graphs that are in line with ID but away from OOD; iii) An efficient and scalable OOD detector to compare the similarity between test samples and pre-constructed prototypical graphs and omit the generative process on every new molecule. Extensive experiments on ten benchmark datasets and six baselines are conducted to demonstrate our superiority.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
LLM-Enhanced Causal Discovery in Temporal Domain from Interventional Data
Apr 23, 2024



In the field of Artificial Intelligence for Information Technology Operations, causal discovery is pivotal for operation and maintenance of graph construction, facilitating downstream industrial tasks such as root cause analysis. Temporal causal discovery, as an emerging method, aims to identify temporal causal relationships between variables directly from observations by utilizing interventional data. However, existing methods mainly focus on synthetic datasets with heavy reliance on intervention targets and ignore the textual information hidden in real-world systems, failing to conduct causal discovery for real industrial scenarios. To tackle this problem, in this paper we propose to investigate temporal causal discovery in industrial scenarios, which faces two critical challenges: 1) how to discover causal relationships without the interventional targets that are costly to obtain in practice, and 2) how to discover causal relations via leveraging the textual information in systems which can be complex yet abundant in industrial contexts. To address these challenges, we propose the RealTCD framework, which is able to leverage domain knowledge to discover temporal causal relationships without interventional targets. Specifically, we first develop a score-based temporal causal discovery method capable of discovering causal relations for root cause analysis without relying on interventional targets through strategic masking and regularization. Furthermore, by employing Large Language Models (LLMs) to handle texts and integrate domain knowledge, we introduce LLM-guided meta-initialization to extract the meta-knowledge from textual information hidden in systems to boost the quality of discovery. We conduct extensive experiments on simulation and real-world datasets to show the superiority of our proposed RealTCD framework over existing baselines in discovering temporal causal structures.
FedGreen: Carbon-aware Federated Learning with Model Size Adaptation
Apr 23, 2024



Federated learning (FL) provides a promising collaborative framework to build a model from distributed clients, and this work investigates the carbon emission of the FL process. Cloud and edge servers hosting FL clients may exhibit diverse carbon footprints influenced by their geographical locations with varying power sources, offering opportunities to reduce carbon emissions by training local models with adaptive computations and communications. In this paper, we propose FedGreen, a carbon-aware FL approach to efficiently train models by adopting adaptive model sizes shared with clients based on their carbon profiles and locations using ordered dropout as a model compression technique. We theoretically analyze the trade-offs between the produced carbon emissions and the convergence accuracy, considering the carbon intensity discrepancy across countries to choose the parameters optimally. Empirical studies show that FedGreen can substantially reduce the carbon footprints of FL compared to the state-of-the-art while maintaining competitive model accuracy.
FLARE: A New Federated Learning Framework with Adjustable Learning Rates over Resource-Constrained Wireless Networks
Apr 23, 2024Wireless federated learning (WFL) suffers from heterogeneity prevailing in the data distributions, computing powers, and channel conditions of participating devices. This paper presents a new Federated Learning with Adjusted leaRning ratE (FLARE) framework to mitigate the impact of the heterogeneity. The key idea is to allow the participating devices to adjust their individual learning rates and local training iterations, adapting to their instantaneous computing powers. The convergence upper bound of FLARE is established rigorously under a general setting with non-convex models in the presence of non-i.i.d. datasets and imbalanced computing powers. By minimizing the upper bound, we further optimize the scheduling of FLARE to exploit the channel heterogeneity. A nested problem structure is revealed to facilitate iteratively allocating the bandwidth with binary search and selecting devices with a new greedy method. A linear problem structure is also identified and a low-complexity linear programming scheduling policy is designed when training models have large Lipschitz constants. Experiments demonstrate that FLARE consistently outperforms the baselines in test accuracy, and converges much faster with the proposed scheduling policy.
ID-Animator: Zero-Shot Identity-Preserving Human Video Generation
Apr 23, 2024
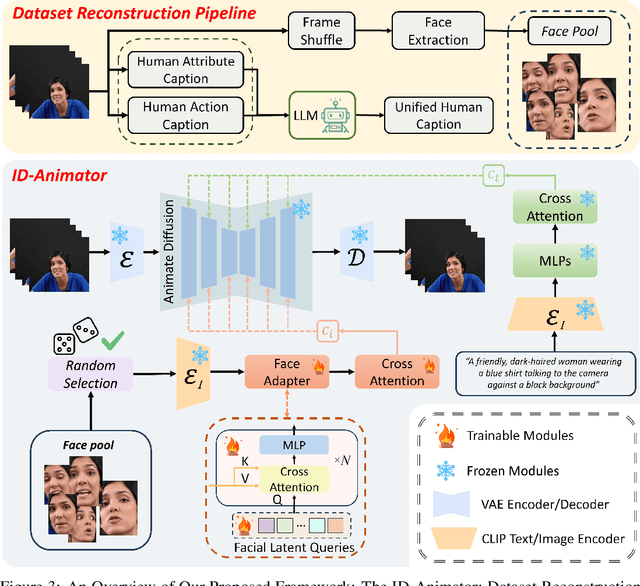


Generating high fidelity human video with specified identities has attracted significant attention in the content generation community. However, existing techniques struggle to strike a balance between training efficiency and identity preservation, either requiring tedious case-by-case finetuning or usually missing the identity details in video generation process. In this study, we present ID-Animator, a zero-shot human-video generation approach that can perform personalized video generation given single reference facial image without further training. ID-Animator inherits existing diffusion-based video generation backbones with a face adapter to encode the ID-relevant embeddings from learnable facial latent queries. To facilitate the extraction of identity information in video generation, we introduce an ID-oriented dataset construction pipeline, which incorporates decoupled human attribute and action captioning technique from a constructed facial image pool. Based on this pipeline, a random face reference training method is further devised to precisely capture the ID-relevant embeddings from reference images, thus improving the fidelity and generalization capacity of our model for ID-specific video generation. Extensive experiments demonstrate the superiority of ID-Animator to generate personalized human videos over previous models. Moreover, our method is highly compatible with popular pre-trained T2V models like animatediff and various community backbone models, showing high extendability in real-world applications for video generation where identity preservation is highly desired. Our codes and checkpoints will be released at https://github.com/ID-Animator/ID-Animator.
Texture-aware and Shape-guided Transformer for Sequential DeepFake Detection
Apr 22, 2024



Sequential DeepFake detection is an emerging task that aims to predict the manipulation sequence in order. Existing methods typically formulate it as an image-to-sequence problem, employing conventional Transformer architectures for detection. However, these methods lack dedicated design and consequently result in limited performance. In this paper, we propose a novel Texture-aware and Shape-guided Transformer to enhance detection performance. Our method features four major improvements. Firstly, we describe a texture-aware branch that effectively captures subtle manipulation traces with the Diversiform Pixel Difference Attention module. Then we introduce a Bidirectional Interaction Cross-attention module that seeks deep correlations among spatial and sequential features, enabling effective modeling of complex manipulation traces. To further enhance the cross-attention, we describe a Shape-guided Gaussian mapping strategy, providing initial priors of the manipulation shape. Finally, observing that the latter manipulation in a sequence may influence traces left in the earlier one, we intriguingly invert the prediction order from forward to backward, leading to notable gains as expected. Extensive experimental results demonstrate that our method outperforms others by a large margin, highlighting the superiority of our method.