 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating self-supervised front ends for speech spoofing countermeasures
Paper and Code
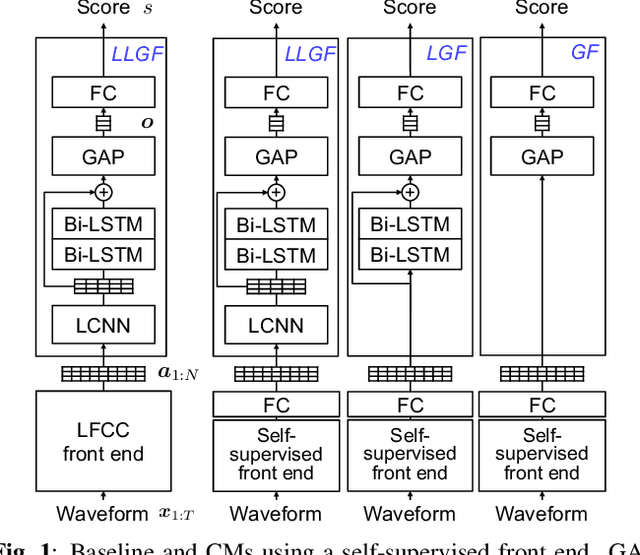
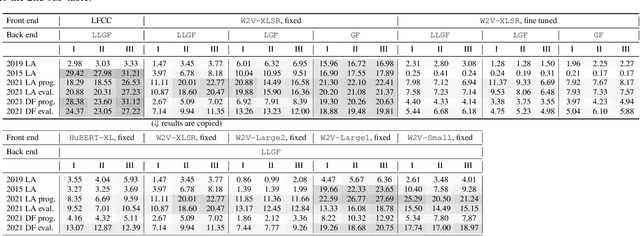
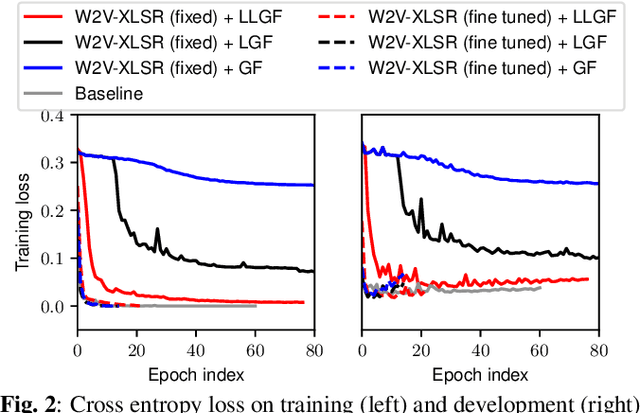
Self-supervised speech model is a rapid progressing research topic, and many pre-trained models have been released and used in various down stream tasks. For speech anti-spoofing, most countermeasures (CMs) use signal processing algorithms to extract acoustic features for classification. In this study, we use pre-trained self-supervised speech models as the front end of spoofing CMs. We investigated different back end architectures to be combined with the self-supervised front end, the effectiveness of fine-tuning the front end, and the performance of using different pre-trained self-supervised models. Our findings showed that, when a good pre-trained front end was fine-tuned with either a shallow or a deep neural network-based back end on the ASVspoof 2019 logical access (LA) training set, the resulting CM not only achieved a low EER score on the 2019 LA test set but also significantly outperformed the baseline on the ASVspoof 2015, 2021 LA, and 2021 deepfake test sets.