 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Personalize Recommendation based on Customers' Shopping Intents
May 10, 2023



Understanding the customers' high level shopping intent, such as their desire to go camping or hold a birthday party, is critically important for an E-commerce platform; it can help boost the quality of shopping experience by enabling provision of more relevant, explainable, and diversified recommendations. However, such high level shopping intent has been overlooked in the industry due to practical challenges. In this work, we introduce Amazon's new system that explicitly identifies and utilizes each customer's high level shopping intents for personalizing recommendations. We develop a novel technique that automatically identifies various high level goals being pursued by the Amazon customers, such as "go camping", and "preparing for a beach party". Our solution is in a scalable fashion (in 14 languages across 21 countries). Then a deep learning model maps each customer's online behavior, e.g. product search and individual item engagements, into a subset of high level shopping intents. Finally, a realtime ranker considers both the identified intents as well as the granular engagements to present personalized intent-aware recommendations. Extensive offline analysis ensures accuracy and relevance of the new recommendations and we further observe an 10% improvement in the business metrics. This system is currently serving online traffic at amazon.com, powering several production features, driving significant business impacts
Learning Personalized Page Content Ranking Using Customer Representation
May 09, 2023On E-commerce stores (Amazon, eBay etc.) there are rich recommendation content to help shoppers shopping more efficiently. However given numerous products, it's crucial to select most relevant content to reduce the burden of information overload. We introduced a content ranking service powered by a linear causal bandit algorithm to rank and select content for each shopper under each context. The algorithm mainly leverages aggregated customer behavior features, and ignores single shopper level past activities. We study the problem of inferring shoppers interest from historical activities. We propose a deep learning based bandit algorithm that incorporates historical shopping behavior, customer latent shopping goals, and the correlation between customers and content categories. This model produces more personalized content ranking measured by 12.08% nDCG lift. In the online A/B test setting, the model improved 0.02% annualized commercial impact measured by our business metric, validating its effectiveness.
FishRecGAN: An End to End GAN Based Network for Fisheye Rectification and Calibration
May 09, 2023



We propose an end-to-end deep learning approach to rectify fisheye images and simultaneously calibrate camera intrinsic and distortion parameters. Our method consists of two parts: a Quick Image Rectification Module developed with a Pix2Pix GAN and Wasserstein GAN (W-Pix2PixGAN), and a Calibration Module with a CNN architecture. Our Quick Rectification Network performs robust rectification with good resolution, making it suitable for constant calibration in camera-based surveillance equipment. To achieve high-quality calibration, we use the straightened output from the Quick Rectification Module as a guidance-like semantic feature map for the Calibration Module to learn the geometric relationship between the straightened feature and the distorted feature. We train and validate our method with a large synthesized dataset labeled with well-simulated parameters applied to a perspective image dataset. Our solution has achieved robust performance in high-resolution with a significant PSNR value of 22.343.
MNER-QG: An End-to-End MRC framework for Multimodal Named Entity Recognition with Query Grounding
Nov 27, 2022Multimodal named entity recognition (MNER) is a critical step in information extraction, which aims to detect entity spans and classify them to corresponding entity types given a sentence-image pair. Existing methods either (1) obtain named entities with coarse-grained visual clues from attention mechanisms, or (2) first detect fine-grained visual regions with toolkits and then recognize named entities. However, they suffer from improper alignment between entity types and visual regions or error propagation in the two-stage manner, which finally imports irrelevant visual information into texts. In this paper, we propose a novel end-to-end framework named MNER-QG that can simultaneously perform MRC-based multimodal named entity recognition and query grounding. Specifically, with the assistance of queries, MNER-QG can provide prior knowledge of entity types and visual regions, and further enhance representations of both texts and images. To conduct the query grounding task, we provide manual annotations and weak supervisions that are obtained via training a highly flexible visual grounding model with transfer learning. We conduct extensive experiments on two public MNER datasets, Twitter2015 and Twitter2017. Experimental results show that MNER-QG outperforms the current state-of-the-art models on the MNER task, and also improves the query grounding performance.
Information fusion approach for biomass estimation in a plateau mountainous forest using a synergistic system comprising UAS-based digital camera and LiDAR
Apr 14, 2022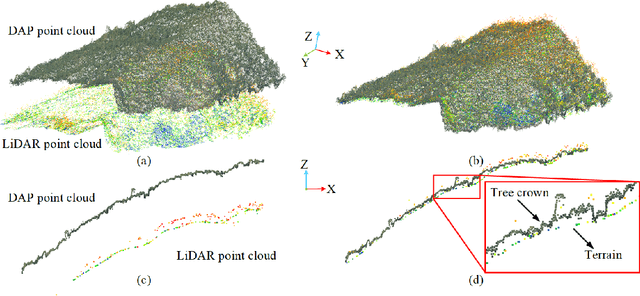
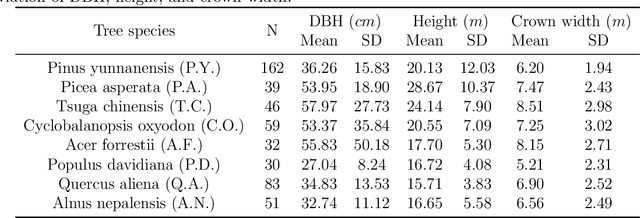
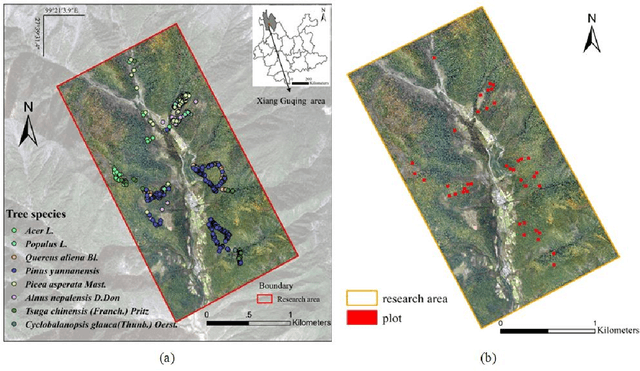

Forest land plays a vital role in global climate, ecosystems, farming and human living environments. Therefore, forest biomass estimation methods are necessary to monitor changes in the forest structure and function, which are key data in natural resources research. Although accurate forest biomass measurements are important in forest inventory and assessments, high-density measurements that involve airborne light detection and ranging (LiDAR) at a low flight height in large mountainous areas are highly expensive. The objective of this study was to quantify the aboveground biomass (AGB) of a plateau mountainous forest reserve using a system that synergistically combines an unmanned aircraft system (UAS)-based digital aerial camera and LiDAR to leverage their complementary advantages. In this study, we utilized digital aerial photogrammetry (DAP), which has the unique advantages of speed, high spatial resolution, and low cost, to compensate for the deficiency of forestry inventory using UAS-based LiDAR that requires terrain-following flight for high-resolution data acquisition. Combined with the sparse LiDAR points acquired by using a high-altitude and high-speed UAS for terrain extraction, dense normalized DAP point clouds can be obtained to produce an accurate and high-resolution canopy height model (CHM). Based on the CHM and spectral attributes obtained from multispectral images, we estimated and mapped the AGB of the region of interest with considerable cost efficiency. Our study supports the development of predictive models for large-scale wall-to-wall AGB mapping by leveraging the complementarity between DAP and LiDAR measurements. This work also reveals the potential of utilizing a UAS-based digital camera and LiDAR synergistically in a plateau mountainous forest area.
Text is NOT Enough: Integrating Visual Impressions into Open-domain Dialogue Generation
Sep 18, 2021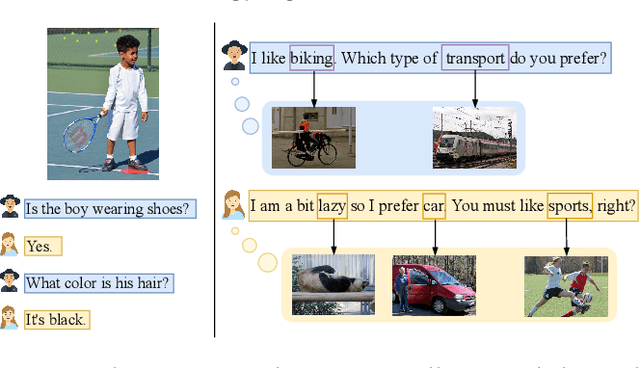
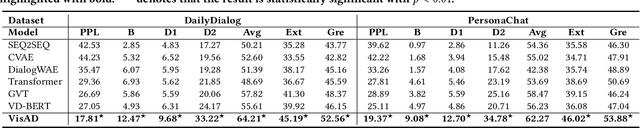
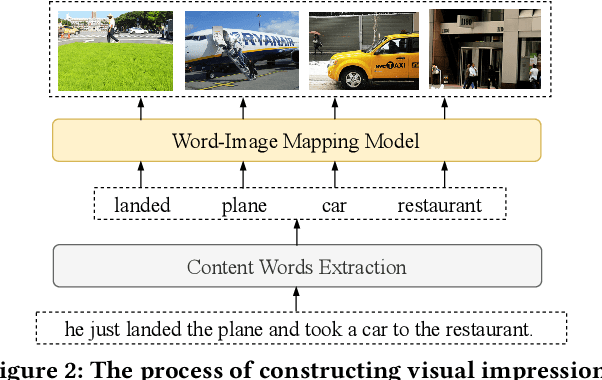
Open-domain dialogue generation in natural language processing (NLP) is by default a pure-language task, which aims to satisfy human need for daily communication on open-ended topics by producing related and informative responses. In this paper, we point out that hidden images, named as visual impressions (VIs), can be explored from the text-only data to enhance dialogue understanding and help generate better responses. Besides, the semantic dependency between an dialogue post and its response is complicated, e.g., few word alignments and some topic transitions. Therefore, the visual impressions of them are not shared, and it is more reasonable to integrate the response visual impressions (RVIs) into the decoder, rather than the post visual impressions (PVIs). However, both the response and its RVIs are not given directly in the test process. To handle the above issues, we propose a framework to explicitly construct VIs based on pure-language dialogue datasets and utilize them for better dialogue understanding and generation. Specifically, we obtain a group of images (PVIs) for each post based on a pre-trained word-image mapping model. These PVIs are used in a co-attention encoder to get a post representation with both visual and textual information. Since the RVIs are not provided directly during testing, we design a cascade decoder that consists of two sub-decoders. The first sub-decoder predicts the content words in response, and applies the word-image mapping model to get those RVIs. Then, the second sub-decoder generates the response based on the post and RVIs. Experimental results on two open-domain dialogue datasets show that our proposed approach achieves superior performance over competitive baselines.
Identifying Untrustworthy Samples: Data Filtering for Open-domain Dialogues with Bayesian Optimization
Sep 14, 2021
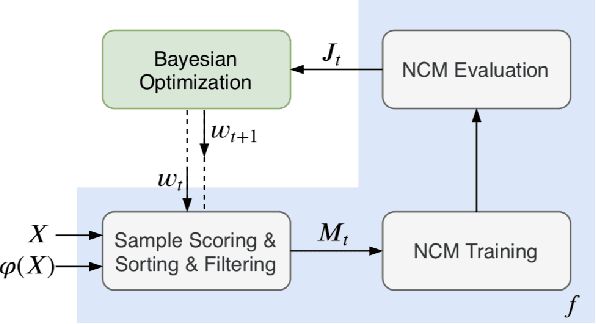
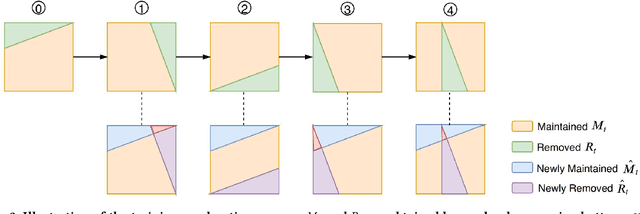
Being able to reply with a related, fluent, and informative response is an indispensable requirement for building high-quality conversational agents. In order to generate better responses, some approaches have been proposed, such as feeding extra information by collecting large-scale datasets with human annotations, designing neural conversational models (NCMs) with complex architecture and loss functions, or filtering out untrustworthy samples based on a dialogue attribute, e.g., Relatedness or Genericness. In this paper, we follow the third research branch and present a data filtering method for open-domain dialogues, which identifies untrustworthy samples from training data with a quality measure that linearly combines seven dialogue attributes. The attribute weights are obtained via Bayesian Optimization (BayesOpt) that aims to optimize an objective function for dialogue generation iteratively on the validation set. Then we score training samples with the quality measure, sort them in descending order, and filter out those at the bottom. Furthermore, to accelerate the "filter-train-evaluate" iterations involved in BayesOpt on large-scale datasets, we propose a training framework that integrates maximum likelihood estimation (MLE) and negative training method (NEG). The training method updates parameters of a trained NCMs on two small sets with newly maintained and removed samples, respectively. Specifically, MLE is applied to maximize the log-likelihood of newly maintained samples, while NEG is used to minimize the log-likelihood of newly removed ones. Experimental results on two datasets show that our method can effectively identify untrustworthy samples, and NCMs trained on the filtered datasets achieve better performance.
Efficient Medical Image Segmentation Based on Knowledge Distillation
Aug 23, 2021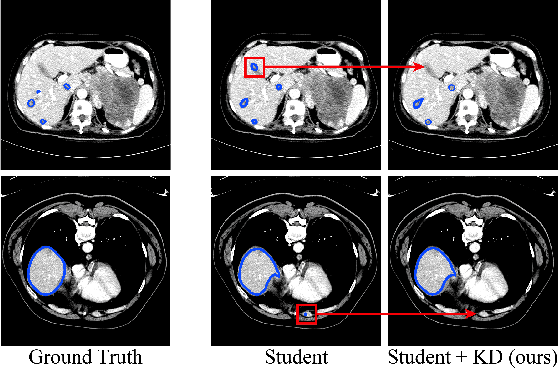
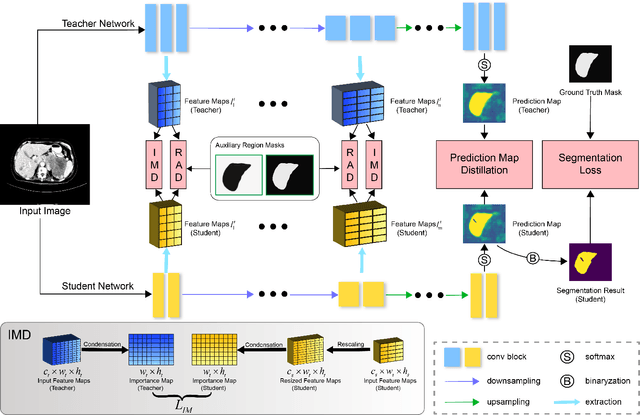
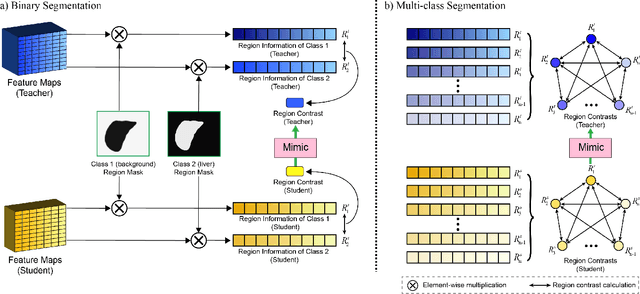
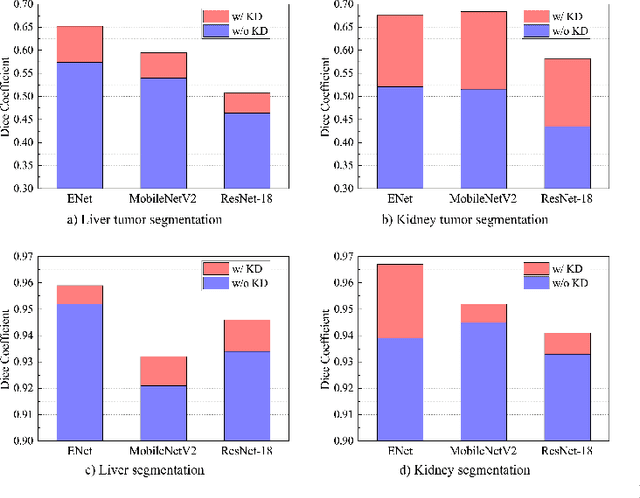
Recent advances have been made in applying convolutional neural networks to achieve more precise prediction results for medical image segmentation problems. However, the success of existing methods has highly relied on huge computational complexity and massive storage, which is impractical in the real-world scenario. To deal with this problem, we propose an efficient architecture by distilling knowledge from well-trained medical image segmentation networks to train another lightweight network. This architecture empowers the lightweight network to get a significant improvement on segmentation capability while retaining its runtime efficiency. We further devise a novel distillation module tailored for medical image segmentation to transfer semantic region information from teacher to student network. It forces the student network to mimic the extent of difference of representations calculated from different tissue regions. This module avoids the ambiguous boundary problem encountered when dealing with medical imaging but instead encodes the internal information of each semantic region for transferring. Benefited from our module, the lightweight network could receive an improvement of up to 32.6% in our experiment while maintaining its portability in the inference phase. The entire structure has been verified on two widely accepted public CT datasets LiTS17 and KiTS19. We demonstrate that a lightweight network distilled by our method has non-negligible value in the scenario which requires relatively high operating speed and low storage usage.
Two-stage Training for Learning from Label Proportions
May 22, 2021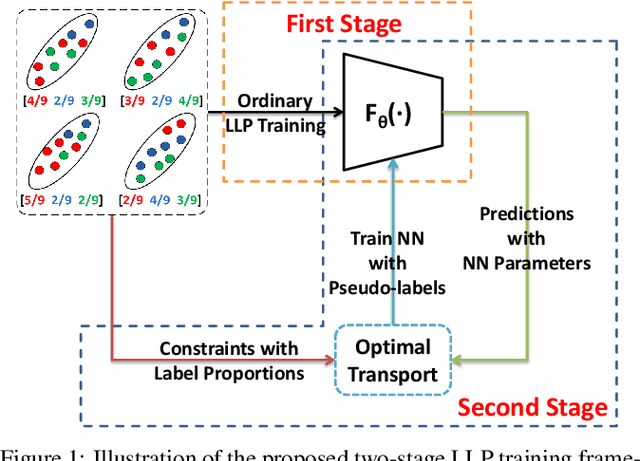
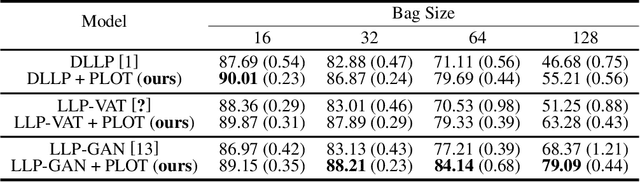
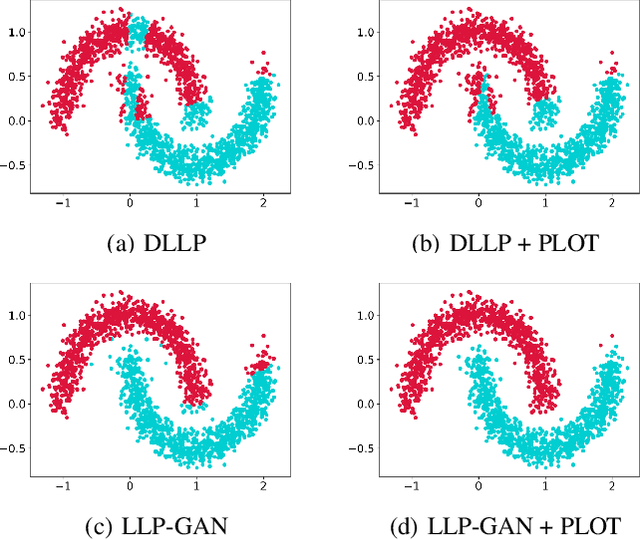
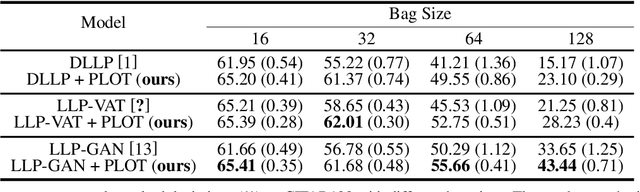
Learning from label proportions (LLP) aims at learning an instance-level classifier with label proportions in grouped training data. Existing deep learning based LLP methods utilize end-to-end pipelines to obtain the proportional loss with Kullback-Leibler divergence between the bag-level prior and posterior class distributions. However, the unconstrained optimization on this objective can hardly reach a solution in accordance with the given proportions. Besides, concerning the probabilistic classifier, this strategy unavoidably results in high-entropy conditional class distributions at the instance level. These issues further degrade the performance of the instance-level classification. In this paper, we regard these problems as noisy pseudo labeling, and instead impose the strict proportion consistency on the classifier with a constrained optimization as a continuous training stage for existing LLP classifiers. In addition, we introduce the mixup strategy and symmetric crossentropy to further reduce the label noise. Our framework is model-agnostic, and demonstrates compelling performance improvement in extensive experiments, when incorporated into other deep LLP models as a post-hoc phase.
Learning to Select Context in a Hierarchical and Global Perspective for Open-domain Dialogue Generation
Feb 18, 2021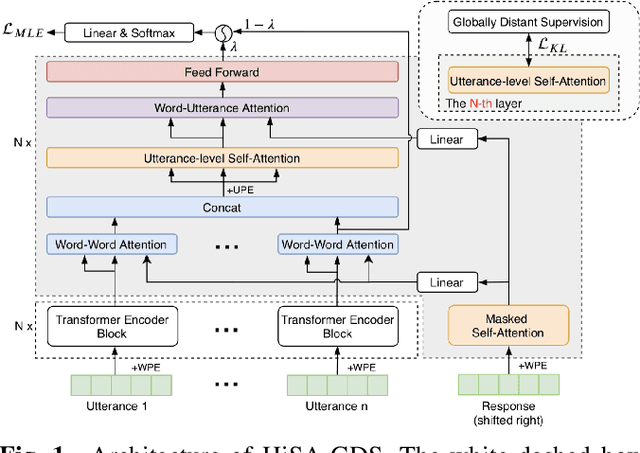
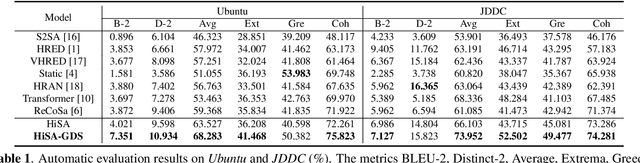
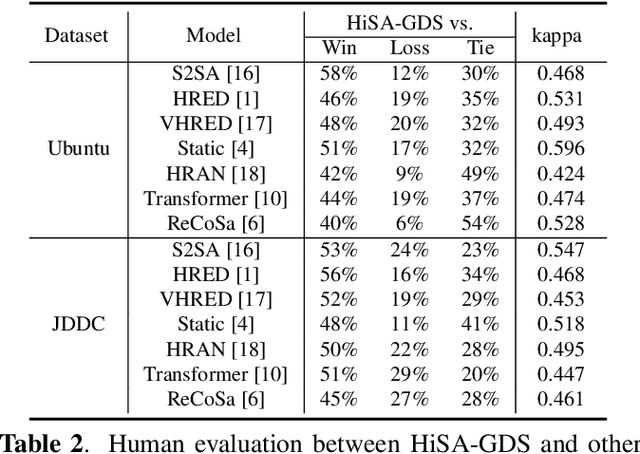
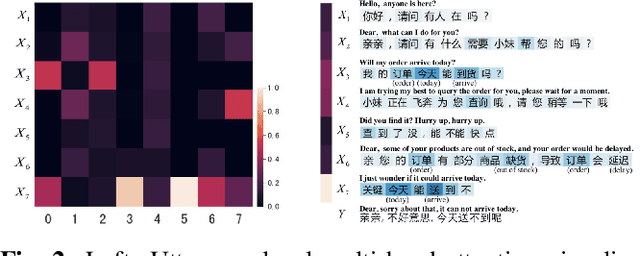
Open-domain multi-turn conversations mainly have three features, which are hierarchical semantic structure, redundant information, and long-term dependency. Grounded on these, selecting relevant context becomes a challenge step for multi-turn dialogue generation. However, existing methods cannot differentiate both useful words and utterances in long distances from a response. Besides, previous work just performs context selection based on a state in the decoder, which lacks a global guidance and could lead some focuses on irrelevant or unnecessary information. In this paper, we propose a novel model with hierarchical self-attention mechanism and distant supervision to not only detect relevant words and utterances in short and long distances, but also discern related information globally when decoding. Experimental results on two public datasets of both automatic and human evaluations show that our model significantly outperforms other baselines in terms of fluency, coherence, and informativeness.