 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSettling the Bias and Variance of Meta-Gradient Estimation for Meta-Reinforcement Learning
Dec 31, 2021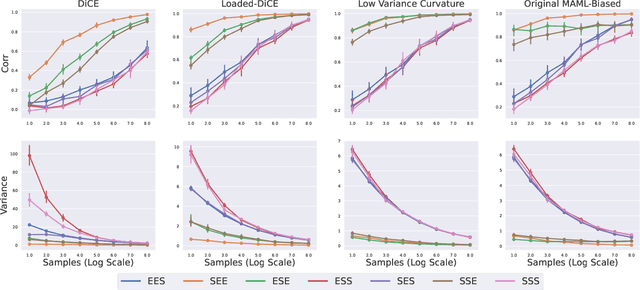
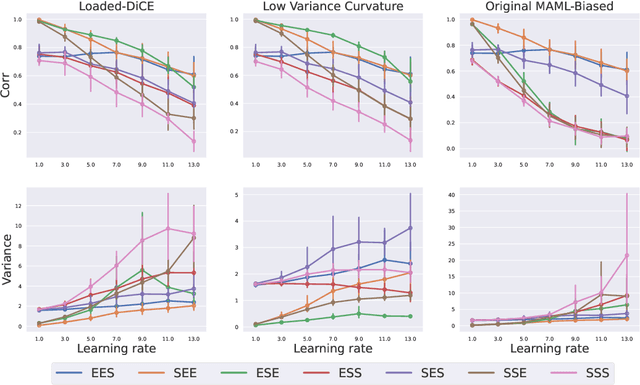
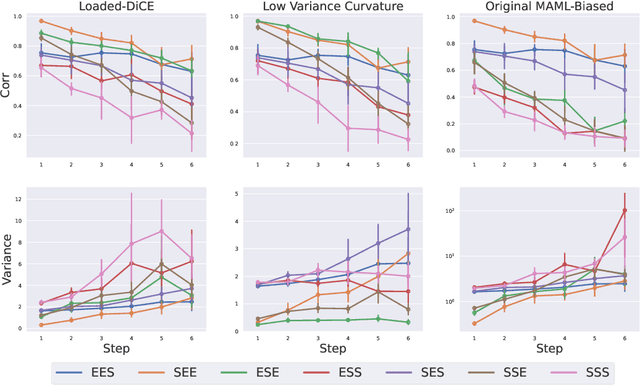
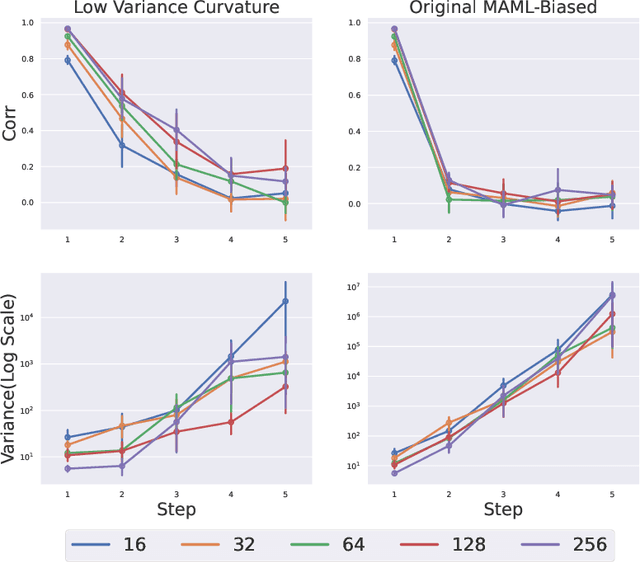
In recent years, gradient based Meta-RL (GMRL) methods have achieved remarkable successes in either discovering effective online hyperparameter for one single task (Xu et al., 2018) or learning good initialisation for multi-task transfer learning (Finn et al., 2017). Despite the empirical successes, it is often neglected that computing meta gradients via vanilla backpropagation is ill-defined. In this paper, we argue that the stochastic meta-gradient estimation adopted by many existing MGRL methods are in fact biased; the bias comes from two sources: 1) the compositional bias that is inborn in the structure of compositional optimisation problems and 2) the bias of multi-step Hessian estimation caused by direct automatic differentiation. To better understand the meta gradient biases, we perform the first of its kind study to quantify the amount for each of them. We start by providing a unifying derivation for existing GMRL algorithms, and then theoretically analyse both the bias and the variance of existing gradient estimation methods. On understanding the underlying principles of bias, we propose two mitigation solutions based on off-policy correction and multi-step Hessian estimation techniques. Comprehensive ablation studies have been conducted and results reveals: (1) The existence of these two biases and how they influence the meta-gradient estimation when combined with different estimator/sample size/step and learning rate. (2) The effectiveness of these mitigation approaches for meta-gradient estimation and thereby the final return on two practical Meta-RL algorithms: LOLA-DiCE and Meta-gradient Reinforcement Learning.
CMML: Contextual Modulation Meta Learning for Cold-Start Recommendation
Sep 08, 2021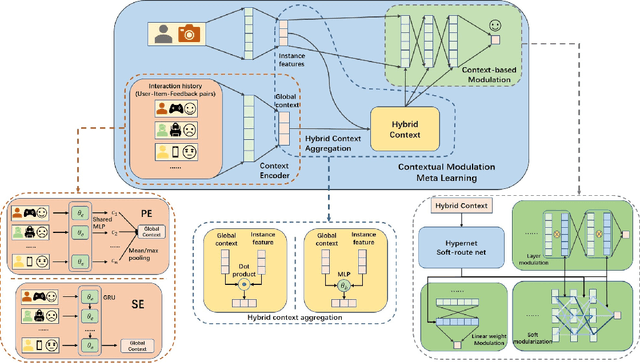

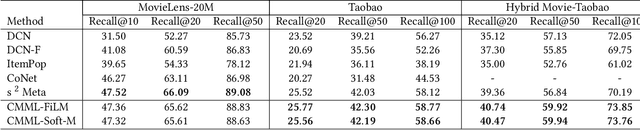
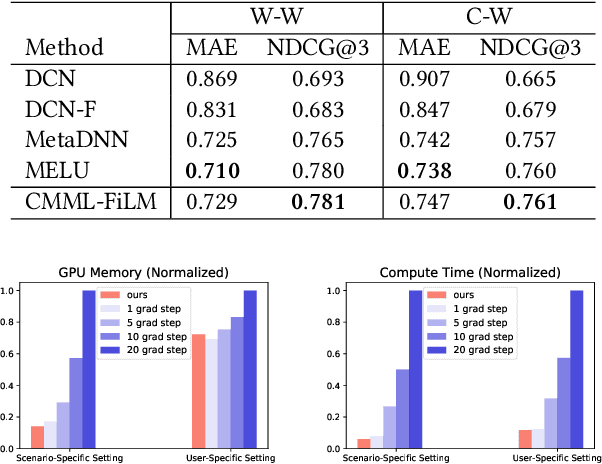
Practical recommender systems experience a cold-start problem when observed user-item interactions in the history are insufficient. Meta learning, especially gradient based one, can be adopted to tackle this problem by learning initial parameters of the model and thus allowing fast adaptation to a specific task from limited data examples. Though with significant performance improvement, it commonly suffers from two critical issues: the non-compatibility with mainstream industrial deployment and the heavy computational burdens, both due to the inner-loop gradient operation. These two issues make them hard to be applied in practical recommender systems. To enjoy the benefits of meta learning framework and mitigate these problems, we propose a recommendation framework called Contextual Modulation Meta Learning (CMML). CMML is composed of fully feed-forward operations so it is computationally efficient and completely compatible with the mainstream industrial deployment. CMML consists of three components, including a context encoder that can generate context embedding to represent a specific task, a hybrid context generator that aggregates specific user-item features with task-level context, and a contextual modulation network, which can modulate the recommendation model to adapt effectively. We validate our approach on both scenario-specific and user-specific cold-start setting on various real-world datasets, showing CMML can achieve comparable or even better performance with gradient based methods yet with much higher computational efficiency and better interpretability.
Discovering Multi-Agent Auto-Curricula in Two-Player Zero-Sum Games
Jun 04, 2021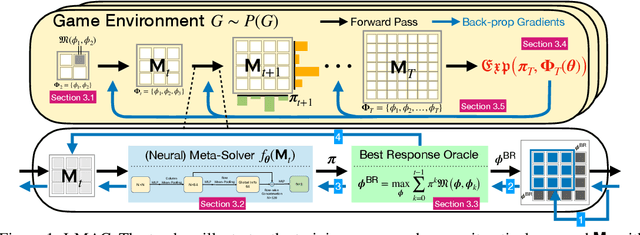
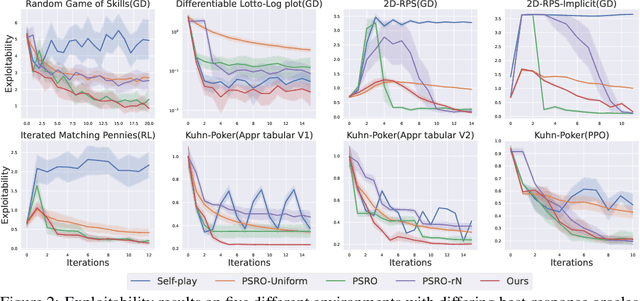

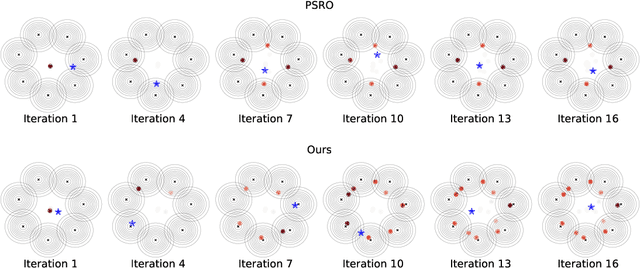
When solving two-player zero-sum games, multi-agent reinforcement learning (MARL) algorithms often create populations of agents where, at each iteration, a new agent is discovered as the best response to a mixture over the opponent population. Within such a process, the update rules of "who to compete with" (i.e., the opponent mixture) and "how to beat them" (i.e., finding best responses) are underpinned by manually developed game theoretical principles such as fictitious play and Double Oracle. In this paper we introduce a framework, LMAC, based on meta-gradient descent that automates the discovery of the update rule without explicit human design. Specifically, we parameterise the opponent selection module by neural networks and the best-response module by optimisation subroutines, and update their parameters solely via interaction with the game engine, where both players aim to minimise their exploitability. Surprisingly, even without human design, the discovered MARL algorithms achieve competitive or even better performance with the state-of-the-art population-based game solvers (e.g., PSRO) on Games of Skill, differentiable Lotto, non-transitive Mixture Games, Iterated Matching Pennies, and Kuhn Poker. Additionally, we show that LMAC is able to generalise from small games to large games, for example training on Kuhn Poker and outperforming PSRO on Leduc Poker. Our work inspires a promising future direction to discover general MARL algorithms solely from data.
Towards Effective Context for Meta-Reinforcement Learning: an Approach based on Contrastive Learning
Oct 07, 2020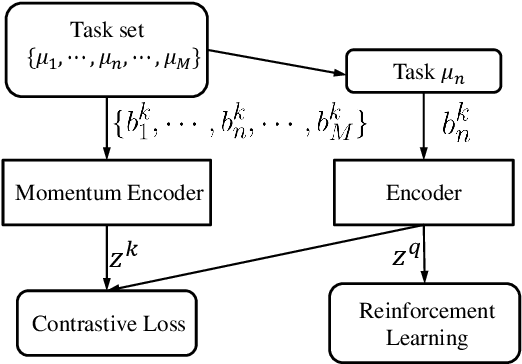

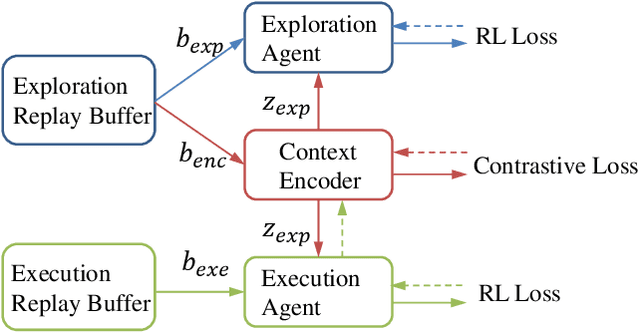
Context, the embedding of previous collected trajectories, is a powerful construct for Meta-Reinforcement Learning (Meta-RL) algorithms. By conditioning on an effective context, Meta-RL policies can easily generalize to new tasks within a few adaptation steps. We argue that improving the quality of context involves answering two questions: 1. How to train a compact and sufficient encoder that can embed the task-specific information contained in prior trajectories? 2. How to collect informative trajectories of which the corresponding context reflects the specification of tasks? To this end, we propose a novel Meta-RL framework called CCM (Contrastive learning augmented Context-based Meta-RL). We first focus on the contrastive nature behind different tasks and leverage it to train a compact and sufficient context encoder. Further, we train a separate exploration policy and theoretically derive a new information-gain-based objective which aims to collect informative trajectories in a few steps. Empirically, we evaluate our approaches on common benchmarks as well as several complex sparse-reward environments. The experimental results show that CCM outperforms state-of-the-art algorithms by addressing previously mentioned problems respectively.