 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Enhanced Collaborative Filtering
Mar 26, 2024



Recent advancements in Large Language Models (LLMs) have attracted considerable interest among researchers to leverage these models to enhance Recommender Systems (RSs). Existing work predominantly utilizes LLMs to generate knowledge-rich texts or utilizes LLM-derived embeddings as features to improve RSs. Although the extensive world knowledge embedded in LLMs generally benefits RSs, the application can only take limited number of users and items as inputs, without adequately exploiting collaborative filtering information. Considering its crucial role in RSs, one key challenge in enhancing RSs with LLMs lies in providing better collaborative filtering information through LLMs. In this paper, drawing inspiration from the in-context learning and chain of thought reasoning in LLMs, we propose the Large Language Models enhanced Collaborative Filtering (LLM-CF) framework, which distils the world knowledge and reasoning capabilities of LLMs into collaborative filtering. We also explored a concise and efficient instruction-tuning method, which improves the recommendation capabilities of LLMs while preserving their general functionalities (e.g., not decreasing on the LLM benchmark). Comprehensive experiments on three real-world datasets demonstrate that LLM-CF significantly enhances several backbone recommendation models and consistently outperforms competitive baselines, showcasing its effectiveness in distilling the world knowledge and reasoning capabilities of LLM into collaborative filtering.
LabelCraft: Empowering Short Video Recommendations with Automated Label Crafting
Dec 18, 2023Short video recommendations often face limitations due to the quality of user feedback, which may not accurately depict user interests. To tackle this challenge, a new task has emerged: generating more dependable labels from original feedback. Existing label generation methods rely on manual rules, demanding substantial human effort and potentially misaligning with the desired objectives of the platform. To transcend these constraints, we introduce LabelCraft, a novel automated label generation method explicitly optimizing pivotal operational metrics for platform success. By formulating label generation as a higher-level optimization problem above recommender model optimization, LabelCraft introduces a trainable labeling model for automatic label mechanism modeling. Through meta-learning techniques, LabelCraft effectively addresses the bi-level optimization hurdle posed by the recommender and labeling models, enabling the automatic acquisition of intricate label generation mechanisms.Extensive experiments on real-world datasets corroborate LabelCraft's excellence across varied operational metrics, encompassing usage time, user engagement, and retention. Codes are available at https://github.com/baiyimeng/LabelCraft.
Generative Retrieval with Semantic Tree-Structured Item Identifiers via Contrastive Learning
Sep 23, 2023



The retrieval phase is a vital component in recommendation systems, requiring the model to be effective and efficient. Recently, generative retrieval has become an emerging paradigm for document retrieval, showing notable performance. These methods enjoy merits like being end-to-end differentiable, suggesting their viability in recommendation. However, these methods fall short in efficiency and effectiveness for large-scale recommendations. To obtain efficiency and effectiveness, this paper introduces a generative retrieval framework, namely SEATER, which learns SEmAntic Tree-structured item identifiERs via contrastive learning. Specifically, we employ an encoder-decoder model to extract user interests from historical behaviors and retrieve candidates via tree-structured item identifiers. SEATER devises a balanced k-ary tree structure of item identifiers, allocating semantic space to each token individually. This strategy maintains semantic consistency within the same level, while distinct levels correlate to varying semantic granularities. This structure also maintains consistent and fast inference speed for all items. Considering the tree structure, SEATER learns identifier tokens' semantics, hierarchical relationships, and inter-token dependencies. To achieve this, we incorporate two contrastive learning tasks with the generation task to optimize both the model and identifiers. The infoNCE loss aligns the token embeddings based on their hierarchical positions. The triplet loss ranks similar identifiers in desired orders. In this way, SEATER achieves both efficiency and effectiveness. Extensive experiments on three public datasets and an industrial dataset have demonstrated that SEATER outperforms state-of-the-art models significantly.
Leveraging Watch-time Feedback for Short-Video Recommendations: A Causal Labeling Framework
Jun 30, 2023



With the proliferation of short video applications, the significance of short video recommendations has vastly increased. Unlike other recommendation scenarios, short video recommendation systems heavily rely on feedback from watch time. Existing approaches simply treat watch time as a direct label, failing to effectively harness its extensive semantics and introduce bias, thereby limiting the potential for modeling user interests based on watch time. To overcome this challenge, we propose a framework named Debiasied Multiple-semantics-extracting Labeling (DML). DML constructs labels that encompass various semantics by utilizing quantiles derived from the distribution of watch time, prioritizing relative order rather than absolute label values. This approach facilitates easier model learning while aligning with the ranking objective of recommendations. Furthermore, we introduce a method inspired by causal adjustment to refine label definitions, thereby reducing the impact of bias on the label and directly mitigating bias at the label level. We substantiate the effectiveness of our DML framework through both online and offline experiments. Extensive results demonstrate that our DML could effectively leverage watch time to discover users' real interests, enhancing their engagement in our application.
KuaiSAR: A Unified Search And Recommendation Dataset
Jun 18, 2023The confluence of Search and Recommendation (S&R) services is vital to online services, including e-commerce and video platforms. The integration of S&R modeling is a highly intuitive approach adopted by industry practitioners. However, there is a noticeable lack of research conducted in this area within academia, primarily due to the absence of publicly available datasets. Consequently, a substantial gap has emerged between academia and industry regarding research endeavors in joint optimization using user behavior data from both S&R services. To bridge this gap, we introduce the first large-scale, real-world dataset KuaiSAR of integrated Search And Recommendation behaviors collected from Kuaishou, a leading short-video app in China with over 350 million daily active users. Previous research in this field has predominantly employed publicly available semi-synthetic datasets and simulated, with artificially fabricated search behaviors. Distinct from previous datasets, KuaiSAR contains genuine user behaviors, including the occurrence of each interaction within either search or recommendation service, and the users' transitions between the two services. This work aids in joint modeling of S&R, and utilizing search data for recommender systems (and recommendation data for search engines). Furthermore, due to the various feedback labels associated with user-video interactions, KuaiSAR also supports a broad range of tasks, including intent recommendation, multi-task learning, and modeling of long sequential multi-behavioral patterns. We believe this dataset will serve as a catalyst for innovative research and bridge the gap between academia and industry in understanding the S&R services in practical, real-world applications.
When Search Meets Recommendation: Learning Disentangled Search Representation for Recommendation
May 18, 2023



Modern online service providers such as online shopping platforms often provide both search and recommendation (S&R) services to meet different user needs. Rarely has there been any effective means of incorporating user behavior data from both S&R services. Most existing approaches either simply treat S&R behaviors separately, or jointly optimize them by aggregating data from both services, ignoring the fact that user intents in S&R can be distinctively different. In our paper, we propose a Search-Enhanced framework for the Sequential Recommendation (SESRec) that leverages users' search interests for recommendation, by disentangling similar and dissimilar representations within S&R behaviors. Specifically, SESRec first aligns query and item embeddings based on users' query-item interactions for the computations of their similarities. Two transformer encoders are used to learn the contextual representations of S&R behaviors independently. Then a contrastive learning task is designed to supervise the disentanglement of similar and dissimilar representations from behavior sequences of S&R. Finally, we extract user interests by the attention mechanism from three perspectives, i.e., the contextual representations, the two separated behaviors containing similar and dissimilar interests. Extensive experiments on both industrial and public datasets demonstrate that SESRec consistently outperforms state-of-the-art models. Empirical studies further validate that SESRec successfully disentangle similar and dissimilar user interests from their S&R behaviors.
TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou
Feb 05, 2023Life-long user behavior modeling, i.e., extracting a user's hidden interests from rich historical behaviors in months or even years, plays a central role in modern CTR prediction systems. Conventional algorithms mostly follow two cascading stages: a simple General Search Unit (GSU) for fast and coarse search over tens of thousands of long-term behaviors and an Exact Search Unit (ESU) for effective Target Attention (TA) over the small number of finalists from GSU. Although efficient, existing algorithms mostly suffer from a crucial limitation: the \textit{inconsistent} target-behavior relevance metrics between GSU and ESU. As a result, their GSU usually misses highly relevant behaviors but retrieves ones considered irrelevant by ESU. In such case, the TA in ESU, no matter how attention is allocated, mostly deviates from the real user interests and thus degrades the overall CTR prediction accuracy. To address such inconsistency, we propose \textbf{TWo-stage Interest Network (TWIN)}, where our Consistency-Preserved GSU (CP-GSU) adopts the identical target-behavior relevance metric as the TA in ESU, making the two stages twins. Specifically, to break TA's computational bottleneck and extend it from ESU to GSU, or namely from behavior length $10^2$ to length $10^4-10^5$, we build a novel attention mechanism by behavior feature splitting. For the video inherent features of a behavior, we calculate their linear projection by efficient pre-computing \& caching strategies. And for the user-item cross features, we compress each into a one-dimentional bias term in the attention score calculation to save the computational cost. The consistency between two stages, together with the effective TA-based relevance metric in CP-GSU, contributes to significant performance gain in CTR prediction.
DETR++: Taming Your Multi-Scale Detection Transformer
Jun 07, 2022
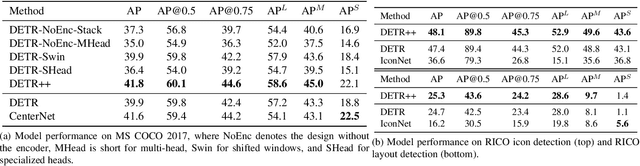
Convolutional Neural Networks (CNN) have dominated the field of detection ever since the success of AlexNet in ImageNet classification [12]. With the sweeping reform of Transformers [27] in natural language processing, Carion et al. [2] introduce the Transformer-based detection method, i.e., DETR. However, due to the quadratic complexity in the self-attention mechanism in the Transformer, DETR is never able to incorporate multi-scale features as performed in existing CNN-based detectors, leading to inferior results in small object detection. To mitigate this issue and further improve performance of DETR, in this work, we investigate different methods to incorporate multi-scale features and find that a Bi-directional Feature Pyramid (BiFPN) works best with DETR in further raising the detection precision. With this discovery, we propose DETR++, a new architecture that improves detection results by 1.9% AP on MS COCO 2017, 11.5% AP on RICO icon detection, and 9.1% AP on RICO layout extraction over existing baselines.
UIBert: Learning Generic Multimodal Representations for UI Understanding
Aug 10, 2021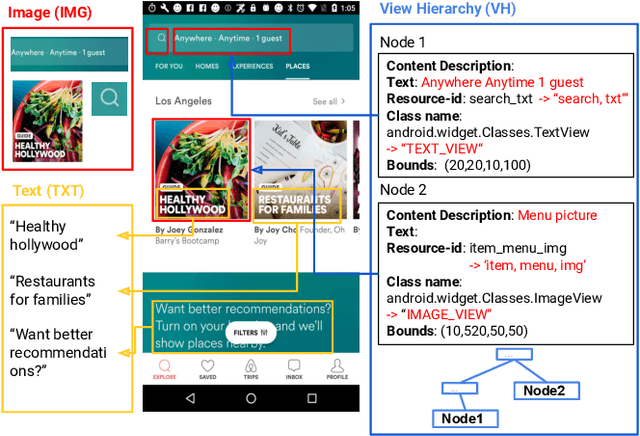
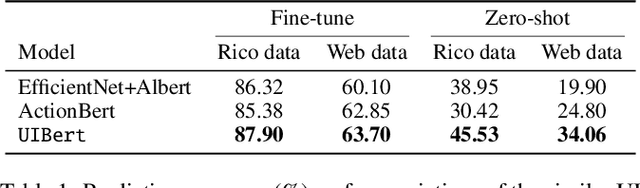
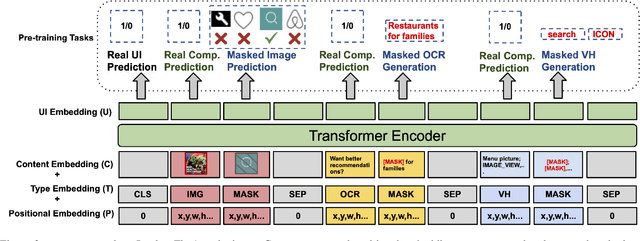
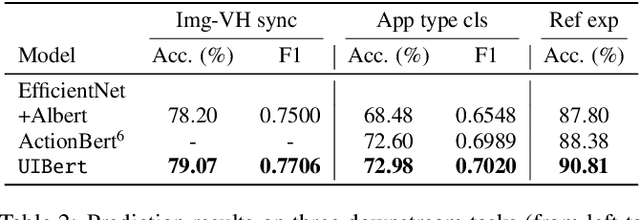
To improve the accessibility of smart devices and to simplify their usage, building models which understand user interfaces (UIs) and assist users to complete their tasks is critical. However, unique challenges are proposed by UI-specific characteristics, such as how to effectively leverage multimodal UI features that involve image, text, and structural metadata and how to achieve good performance when high-quality labeled data is unavailable. To address such challenges we introduce UIBert, a transformer-based joint image-text model trained through novel pre-training tasks on large-scale unlabeled UI data to learn generic feature representations for a UI and its components. Our key intuition is that the heterogeneous features in a UI are self-aligned, i.e., the image and text features of UI components, are predictive of each other. We propose five pretraining tasks utilizing this self-alignment among different features of a UI component and across various components in the same UI. We evaluate our method on nine real-world downstream UI tasks where UIBert outperforms strong multimodal baselines by up to 9.26% accuracy.
Multimodal Icon Annotation For Mobile Applications
Jul 09, 2021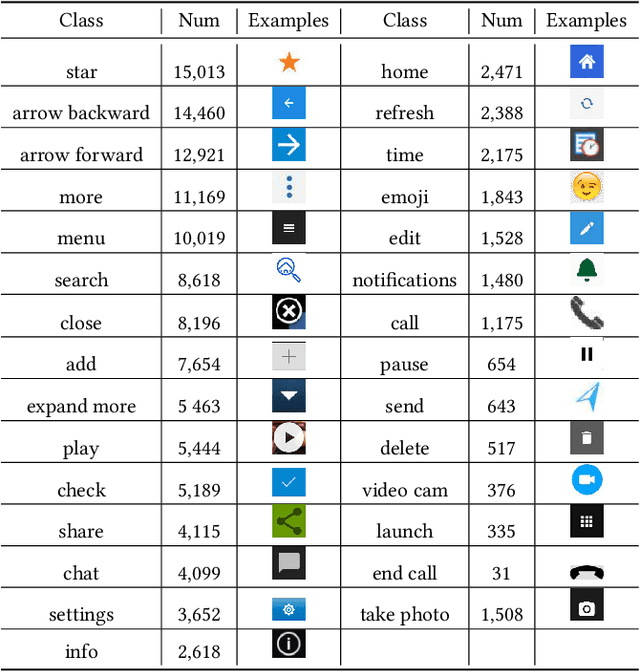
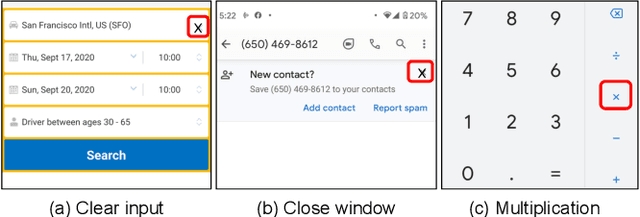
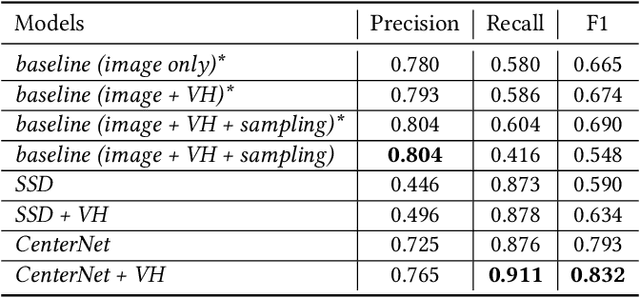
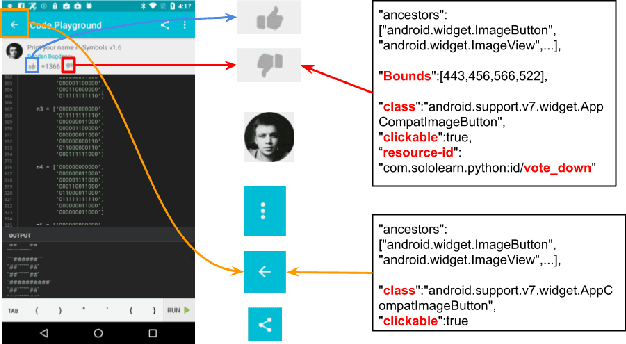
Annotating user interfaces (UIs) that involves localization and classification of meaningful UI elements on a screen is a critical step for many mobile applications such as screen readers and voice control of devices. Annotating object icons, such as menu, search, and arrow backward, is especially challenging due to the lack of explicit labels on screens, their similarity to pictures, and their diverse shapes. Existing studies either use view hierarchy or pixel based methods to tackle the task. Pixel based approaches are more popular as view hierarchy features on mobile platforms are often incomplete or inaccurate, however it leaves out instructional information in the view hierarchy such as resource-ids or content descriptions. We propose a novel deep learning based multi-modal approach that combines the benefits of both pixel and view hierarchy features as well as leverages the state-of-the-art object detection techniques. In order to demonstrate the utility provided, we create a high quality UI dataset by manually annotating the most commonly used 29 icons in Rico, a large scale mobile design dataset consisting of 72k UI screenshots. The experimental results indicate the effectiveness of our multi-modal approach. Our model not only outperforms a widely used object classification baseline but also pixel based object detection models. Our study sheds light on how to combine view hierarchy with pixel features for annotating UI elements.