 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend To Count: Crowd Counting with Adaptive Capacity Multi-scale CNNs
Aug 26, 2019
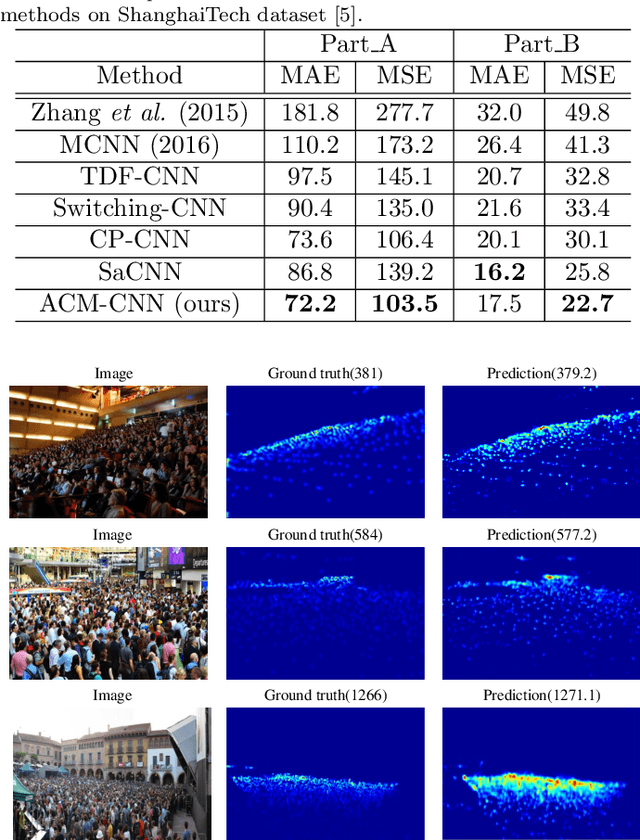
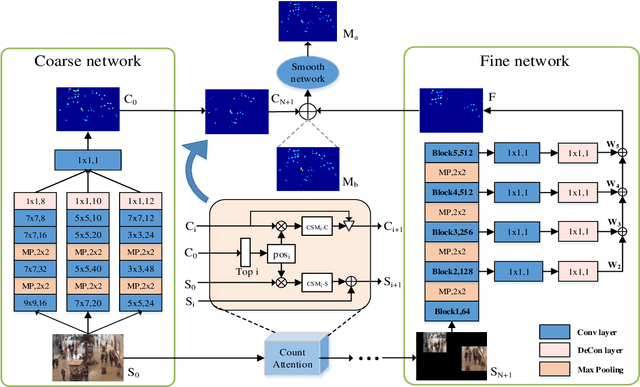
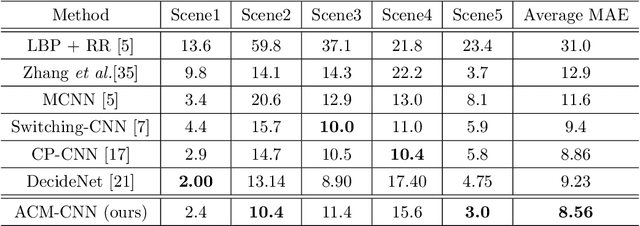
Crowd counting is a challenging task due to the large variations in crowd distributions. Previous methods tend to tackle the whole image with a single fixed structure, which is unable to handle diverse complicated scenes with different crowd densities. Hence, we propose the Adaptive Capacity Multi-scale convolutional neural networks (ACM-CNN), a novel crowd counting approach which can assign different capacities to different portions of the input. The intuition is that the model should focus on important regions of the input image and optimize its capacity allocation conditioning on the crowd intensive degree. ACM-CNN consists of three types of modules: a coarse network, a fine network, and a smooth network. The coarse network is used to explore the areas that need to be focused via count attention mechanism, and generate a rough feature map. Then the fine network processes the areas of interest into a fine feature map. To alleviate the sense of division caused by fusion, the smooth network is designed to combine two feature maps organically to produce high-quality density maps. Extensive experiments are conducted on five mainstream datasets. The results demonstrate the effectiveness of the proposed model for both density estimation and crowd counting tasks.
Meta Reasoning over Knowledge Graphs
Aug 13, 2019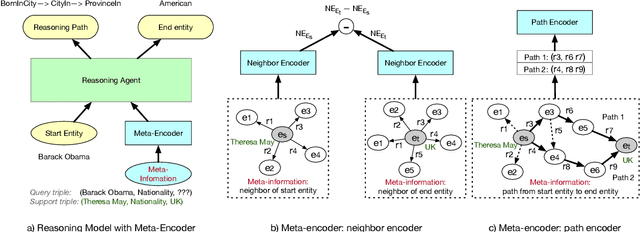
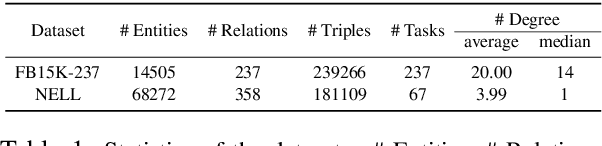
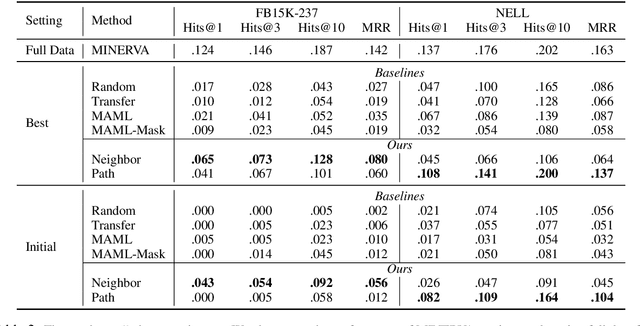
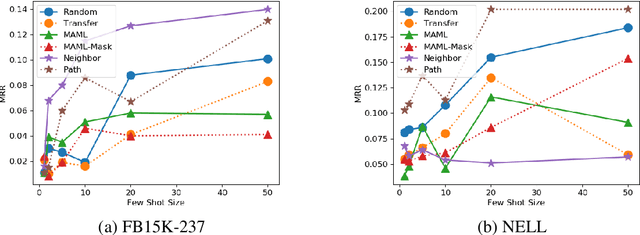
The ability to reason over learned knowledge is an innate ability for humans and humans can easily master new reasoning rules with only a few demonstrations. While most existing studies on knowledge graph (KG) reasoning assume enough training examples, we study the challenging and practical problem of few-shot knowledge graph reasoning under the paradigm of meta-learning. We propose a new meta learning framework that effectively utilizes the task-specific meta information such as local graph neighbors and reasoning paths in KGs. Specifically, we design a meta-encoder that encodes the meta information into task-specific initialization parameters for different tasks. This allows our reasoning module to have diverse starting points when learning to reason over different relations, which is expected to better fit the target task. On two few-shot knowledge base completion benchmarks, we show that the augmented task-specific meta-encoder yields much better initial point than MAML and outperforms several few-shot learning baselines.
TWEETQA: A Social Media Focused Question Answering Dataset
Jul 14, 2019
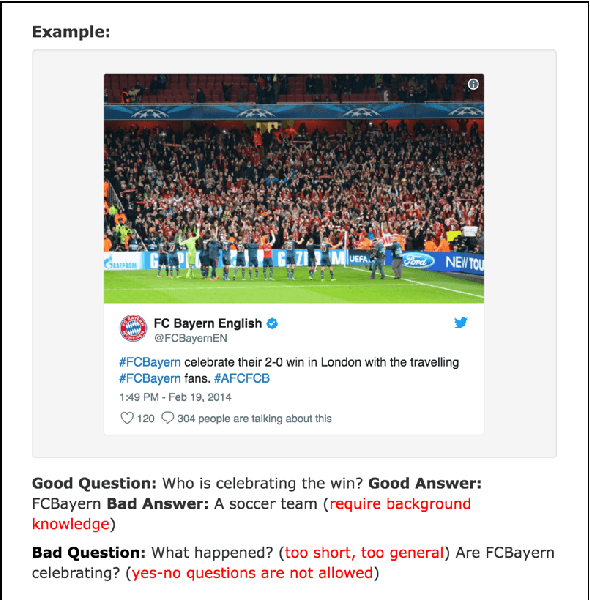
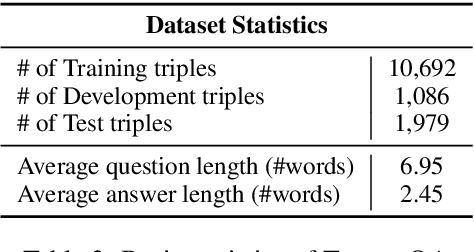

With social media becoming increasingly pop-ular on which lots of news and real-time eventsare reported, developing automated questionanswering systems is critical to the effective-ness of many applications that rely on real-time knowledge. While previous datasets haveconcentrated on question answering (QA) forformal text like news and Wikipedia, wepresent the first large-scale dataset for QA oversocial media data. To ensure that the tweetswe collected are useful, we only gather tweetsused by journalists to write news articles. Wethen ask human annotators to write questionsand answers upon these tweets. Unlike otherQA datasets like SQuAD in which the answersare extractive, we allow the answers to be ab-stractive. We show that two recently proposedneural models that perform well on formaltexts are limited in their performance when ap-plied to our dataset. In addition, even the fine-tuned BERT model is still lagging behind hu-man performance with a large margin. Our re-sults thus point to the need of improved QAsystems targeting social media text.
Self-Supervised Learning for Contextualized Extractive Summarization
Jun 11, 2019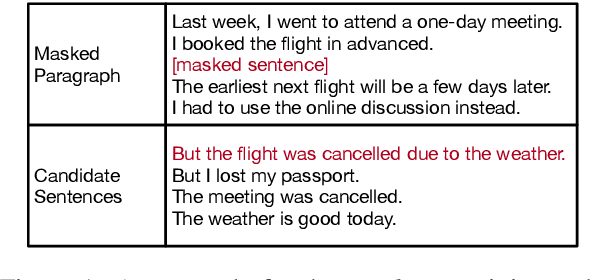
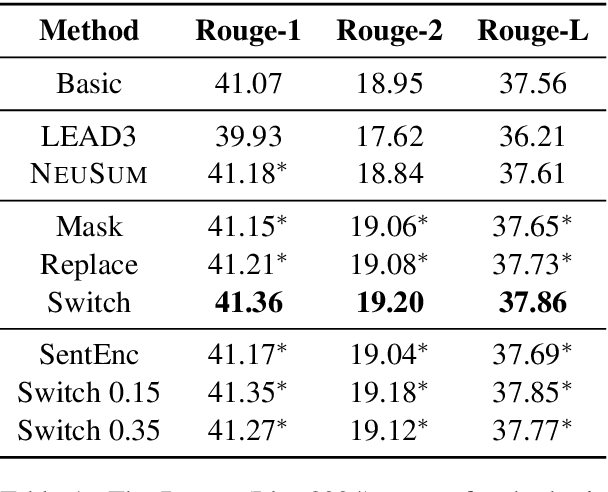
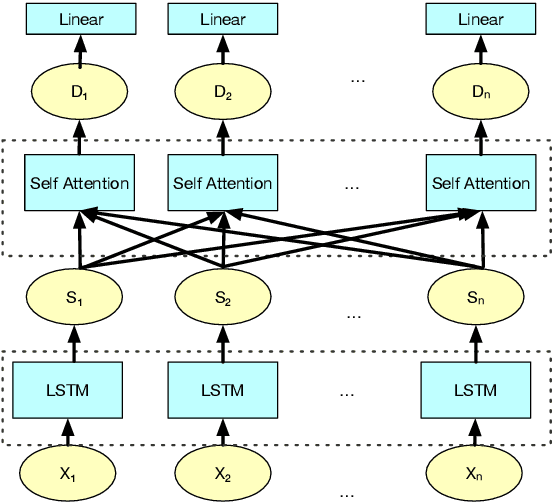
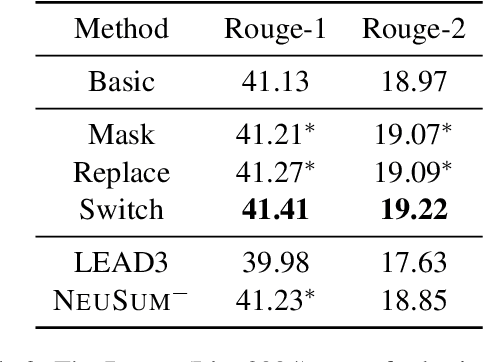
Existing models for extractive summarization are usually trained from scratch with a cross-entropy loss, which does not explicitly capture the global context at the document level. In this paper, we aim to improve this task by introducing three auxiliary pre-training tasks that learn to capture the document-level context in a self-supervised fashion. Experiments on the widely-used CNN/DM dataset validate the effectiveness of the proposed auxiliary tasks. Furthermore, we show that after pre-training, a clean model with simple building blocks is able to outperform previous state-of-the-art that are carefully designed.
Improving Question Answering over Incomplete KBs with Knowledge-Aware Reader
May 31, 2019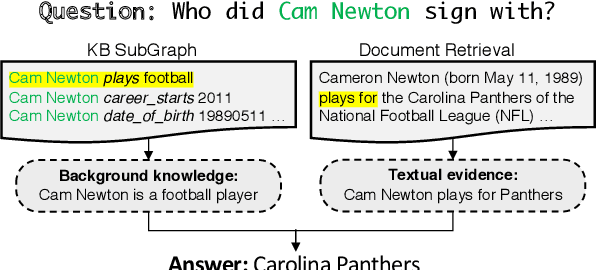
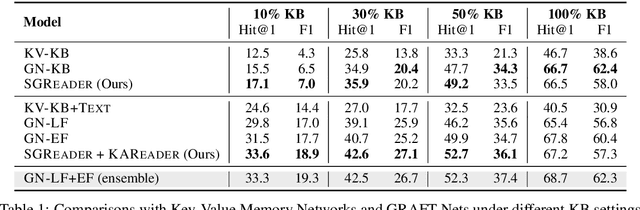
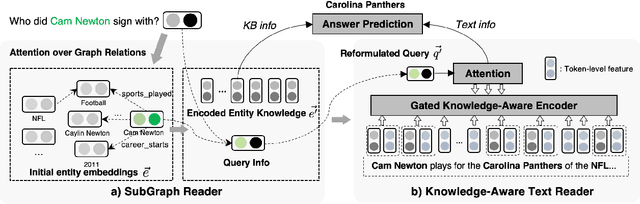

We propose a new end-to-end question answering model, which learns to aggregate answer evidence from an incomplete knowledge base (KB) and a set of retrieved text snippets. Under the assumptions that the structured KB is easier to query and the acquired knowledge can help the understanding of unstructured text, our model first accumulates knowledge of entities from a question-related KB subgraph; then reformulates the question in the latent space and reads the texts with the accumulated entity knowledge at hand. The evidence from KB and texts are finally aggregated to predict answers. On the widely-used KBQA benchmark WebQSP, our model achieves consistent improvements across settings with different extents of KB incompleteness.
The Fashion IQ Dataset: Retrieving Images by Combining Side Information and Relative Natural Language Feedback
May 30, 2019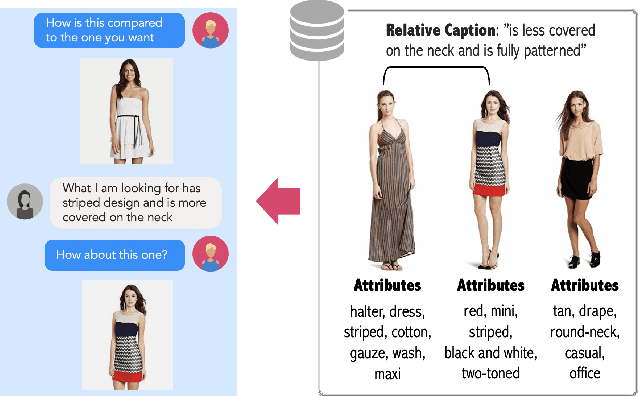
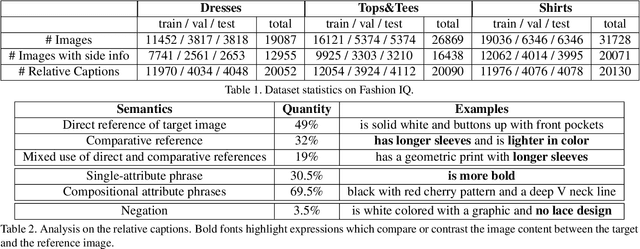
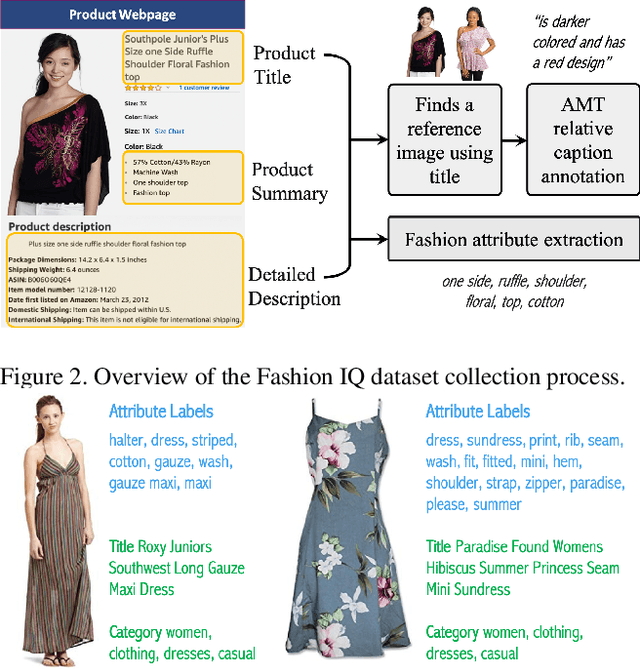
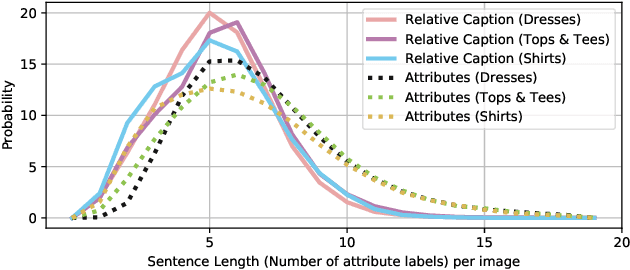
We contribute a new dataset and a novel method for natural language based fashion image retrieval. Unlike previous fashion datasets, we provide natural language annotations to facilitate the training of interactive image retrieval systems, as well as the commonly used attribute based labels. We propose a novel approach and empirically demonstrate that combining natural language feedback with visual attribute information results in superior user feedback modeling and retrieval performance relative to using either of these modalities. We believe that our dataset can encourage further work on developing more natural and real-world applicable conversational shopping assistants.
A Hybrid Approach with Optimization and Metric-based Meta-Learner for Few-Shot Learning
Apr 04, 2019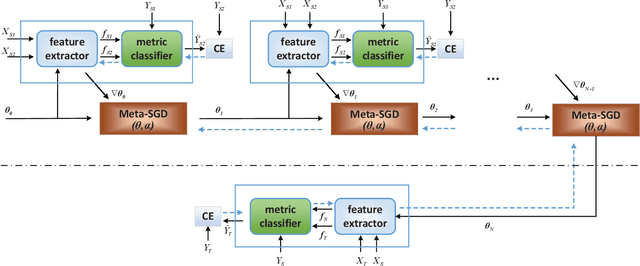
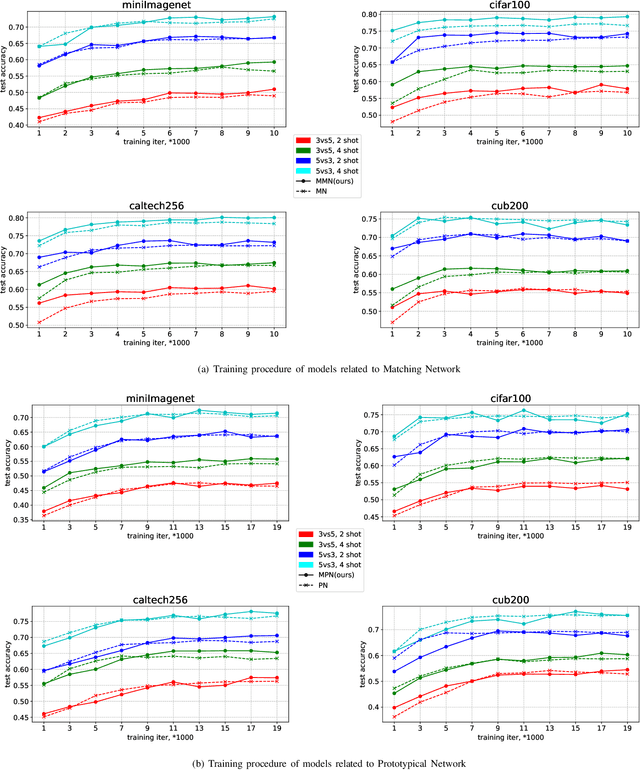
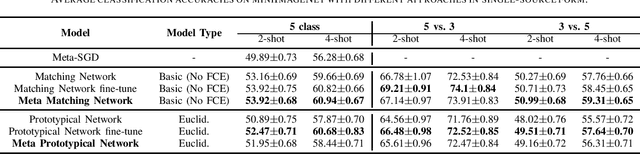
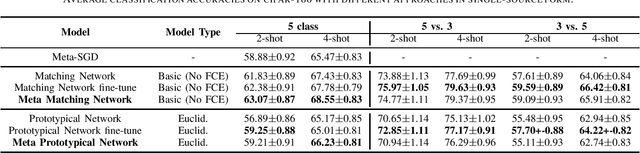
Few-shot learning aims to learn classifiers for new classes with only a few training examples per class. Most existing few-shot learning approaches belong to either metric-based meta-learning or optimization-based meta-learning category, both of which have achieved successes in the simplified "$k$-shot $N$-way" image classification settings. Specifically, the optimization-based approaches train a meta-learner to predict the parameters of the task-specific classifiers. The task-specific classifiers are required to be homogeneous-structured to ease the parameter prediction, so the meta-learning approaches could only handle few-shot learning problems where the tasks share a uniform number of classes. The metric-based approaches learn one task-invariant metric for all the tasks. Even though the metric-learning approaches allow different numbers of classes, they require the tasks all coming from a similar domain such that there exists a uniform metric that could work across tasks. In this work, we propose a hybrid meta-learning model called Meta-Metric-Learner which combines the merits of both optimization- and metric-based approaches. Our meta-metric-learning approach consists of two components, a task-specific metric-based learner as a base model, and a meta-learner that learns and specifies the base model. Thus our model is able to handle flexible numbers of classes as well as generate more generalized metrics for classification across tasks. We test our approach in the standard "$k$-shot $N$-way" few-shot learning setting following previous works and a new realistic few-shot setting with flexible class numbers in both single-source form and multi-source forms. Experiments show that our approach can obtain superior performance in all settings.
Sentence Embedding Alignment for Lifelong Relation Extraction
Mar 26, 2019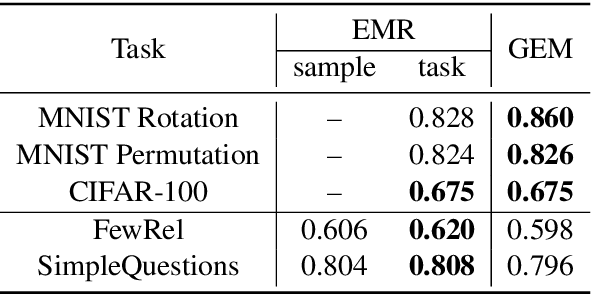
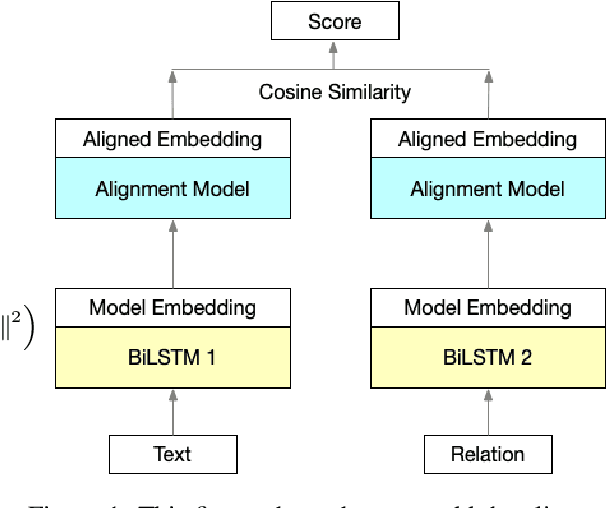
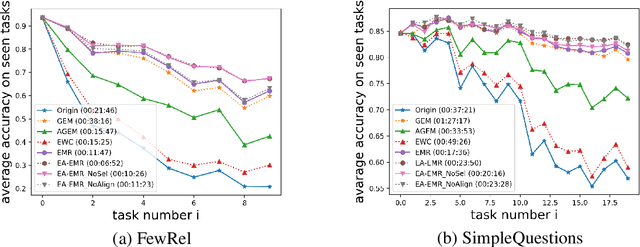
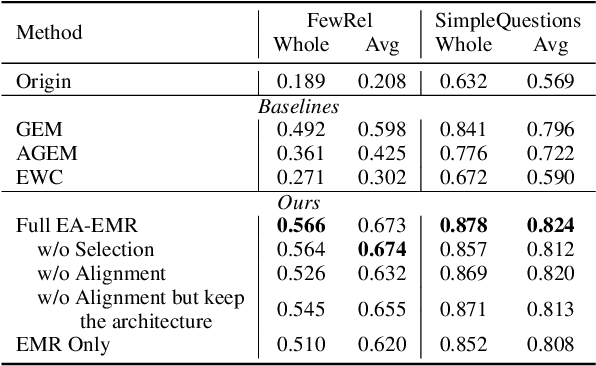
Conventional approaches to relation extraction usually require a fixed set of pre-defined relations. Such requirement is hard to meet in many real applications, especially when new data and relations are emerging incessantly and it is computationally expensive to store all data and re-train the whole model every time new data and relations come in. We formulate such a challenging problem as lifelong relation extraction and investigate memory-efficient incremental learning methods without catastrophically forgetting knowledge learned from previous tasks. We first investigate a modified version of the stochastic gradient methods with a replay memory, which surprisingly outperforms recent state-of-the-art lifelong learning methods. We further propose to improve this approach to alleviate the forgetting problem by anchoring the sentence embedding space. Specifically, we utilize an explicit alignment model to mitigate the sentence embedding distortion of the learned model when training on new data and new relations. Experiment results on multiple benchmarks show that our proposed method significantly outperforms the state-of-the-art lifelong learning approaches.
Hybrid Reinforcement Learning with Expert State Sequences
Mar 11, 2019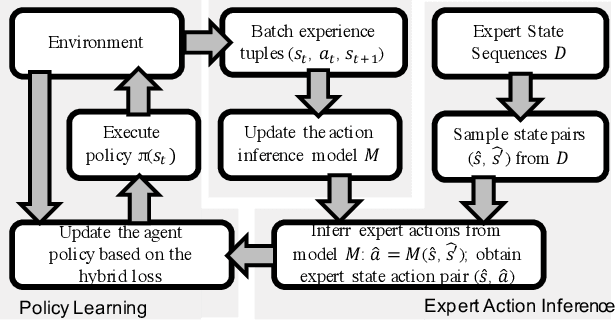
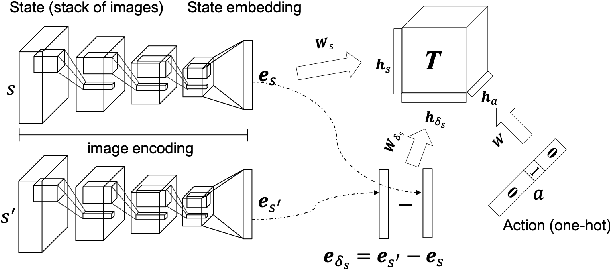
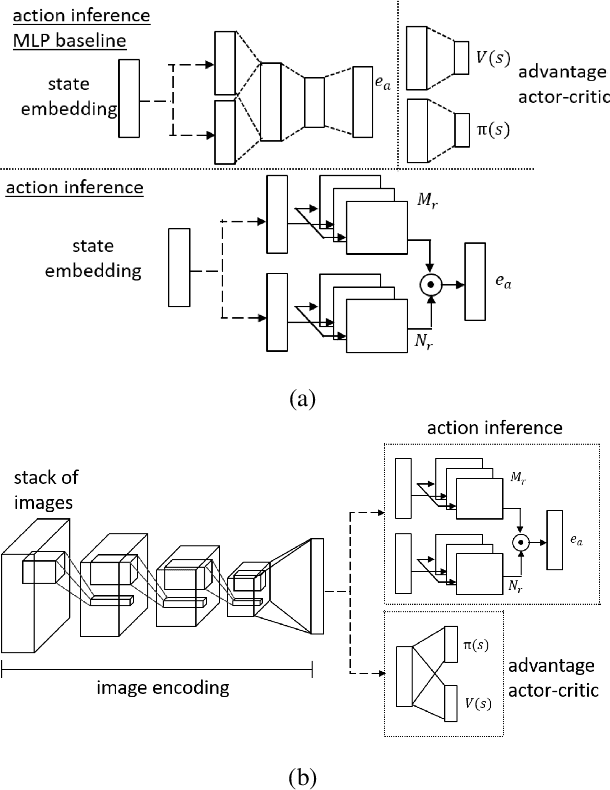
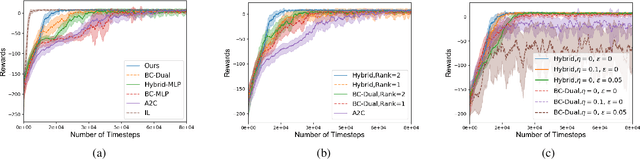
Existing imitation learning approaches often require that the complete demonstration data, including sequences of actions and states, are available. In this paper, we consider a more realistic and difficult scenario where a reinforcement learning agent only has access to the state sequences of an expert, while the expert actions are unobserved. We propose a novel tensor-based model to infer the unobserved actions of the expert state sequences. The policy of the agent is then optimized via a hybrid objective combining reinforcement learning and imitation learning. We evaluated our hybrid approach on an illustrative domain and Atari games. The empirical results show that (1) the agents are able to leverage state expert sequences to learn faster than pure reinforcement learning baselines, (2) our tensor-based action inference model is advantageous compared to standard deep neural networks in inferring expert actions, and (3) the hybrid policy optimization objective is robust against noise in expert state sequences.
Imposing Label-Relational Inductive Bias for Extremely Fine-Grained Entity Typing
Mar 06, 2019
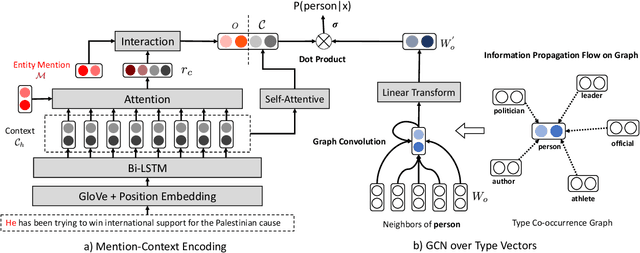
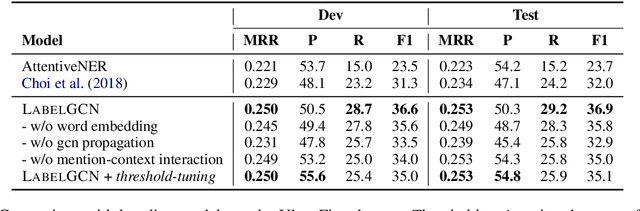
Existing entity typing systems usually exploit the type hierarchy provided by knowledge base (KB) schema to model label correlations and thus improve the overall performance. Such techniques, however, are not directly applicable to more open and practical scenarios where the type set is not restricted by KB schema and includes a vast number of free-form types. To model the underly-ing label correlations without access to manually annotated label structures, we introduce a novel label-relational inductive bias, represented by a graph propagation layer that effectively encodes both global label co-occurrence statistics and word-level similarities.On a large dataset with over 10,000 free-form types, the graph-enhanced model equipped with an attention-based matching module is able to achieve a much higher recall score while maintaining a high-level precision. Specifically, it achieves a 15.3% relative F1 improvement and also less inconsistency in the outputs. We further show that a simple modification of our proposed graph layer can also improve the performance on a conventional and widely-tested dataset that only includes KB-schema types.