 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdd-One-In: Incremental Sample Selection for Large Language Models via a Choice-Based Greedy Paradigm
Mar 04, 2025Selecting high-quality and diverse training samples from extensive datasets plays a crucial role in reducing training overhead and enhancing the performance of Large Language Models (LLMs). However, existing studies fall short in assessing the overall value of selected data, focusing primarily on individual quality, and struggle to strike an effective balance between ensuring diversity and minimizing data point traversals. Therefore, this paper introduces a novel choice-based sample selection framework that shifts the focus from evaluating individual sample quality to comparing the contribution value of different samples when incorporated into the subset. Thanks to the advanced language understanding capabilities of LLMs, we utilize LLMs to evaluate the value of each option during the selection process. Furthermore, we design a greedy sampling process where samples are incrementally added to the subset, thereby improving efficiency by eliminating the need for exhaustive traversal of the entire dataset with the limited budget. Extensive experiments demonstrate that selected data from our method not only surpass the performance of the full dataset but also achieves competitive results with state-of-the-art (SOTA) studies, while requiring fewer selections. Moreover, we validate our approach on a larger medical dataset, highlighting its practical applicability in real-world applications.
VoxEval: Benchmarking the Knowledge Understanding Capabilities of End-to-End Spoken Language Models
Jan 09, 2025



With the growing demand for developing speech-based interaction models, end-to-end Spoken Language Models (SLMs) have emerged as a promising solution. When engaging in conversations with humans, it is essential for these models to comprehend a wide range of world knowledge. In this paper, we introduce VoxEval, a novel speech question-answering benchmark specifically designed to assess SLMs' knowledge understanding through purely speech-based interactions. Unlike existing AudioQA benchmarks, VoxEval maintains speech format for both questions and answers, evaluates model robustness across diverse audio conditions (varying timbres, audio qualities, and speaking styles), and pioneers the assessment of challenging domains like mathematical problem-solving in spoken format. Our comprehensive evaluation of recent SLMs using VoxEval reveals significant performance limitations in current models, highlighting crucial areas for future improvements.
Recent Advances in Speech Language Models: A Survey
Oct 01, 2024



Large Language Models (LLMs) have recently garnered significant attention, primarily for their capabilities in text-based interactions. However, natural human interaction often relies on speech, necessitating a shift towards voice-based models. A straightforward approach to achieve this involves a pipeline of ``Automatic Speech Recognition (ASR) + LLM + Text-to-Speech (TTS)", where input speech is transcribed to text, processed by an LLM, and then converted back to speech. Despite being straightforward, this method suffers from inherent limitations, such as information loss during modality conversion and error accumulation across the three stages. To address these issues, Speech Language Models (SpeechLMs) -- end-to-end models that generate speech without converting from text -- have emerged as a promising alternative. This survey paper provides the first comprehensive overview of recent methodologies for constructing SpeechLMs, detailing the key components of their architecture and the various training recipes integral to their development. Additionally, we systematically survey the various capabilities of SpeechLMs, categorize the evaluation metrics for SpeechLMs, and discuss the challenges and future research directions in this rapidly evolving field.
Direct Alignment of Language Models via Quality-Aware Self-Refinement
May 31, 2024
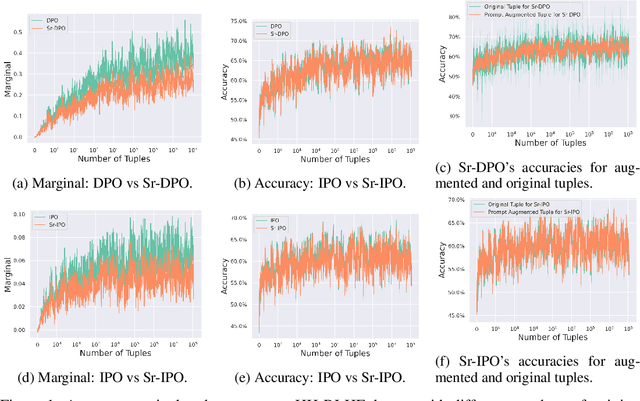
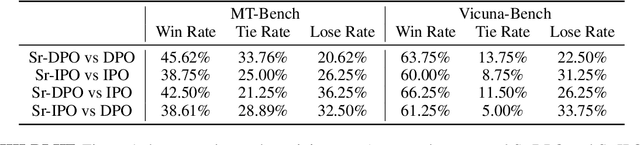
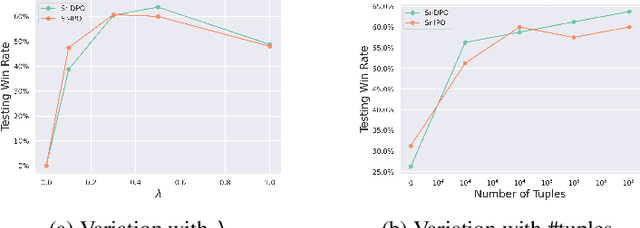
Reinforcement Learning from Human Feedback (RLHF) has been commonly used to align the behaviors of Large Language Models (LLMs) with human preferences. Recently, a popular alternative is Direct Policy Optimization (DPO), which replaces an LLM-based reward model with the policy itself, thus obviating the need for extra memory and training time to learn the reward model. However, DPO does not consider the relative qualities of the positive and negative responses, and can lead to sub-optimal training outcomes. To alleviate this problem, we investigate the use of intrinsic knowledge within the on-the-fly fine-tuning LLM to obtain relative qualities and help to refine the loss function. Specifically, we leverage the knowledge of the LLM to design a refinement function to estimate the quality of both the positive and negative responses. We show that the constructed refinement function can help self-refine the loss function under mild assumptions. The refinement function is integrated into DPO and its variant Identity Policy Optimization (IPO). Experiments across various evaluators indicate that they can improve the performance of the fine-tuned models over DPO and IPO.
LightMBERT: A Simple Yet Effective Method for Multilingual BERT Distillation
Mar 11, 2021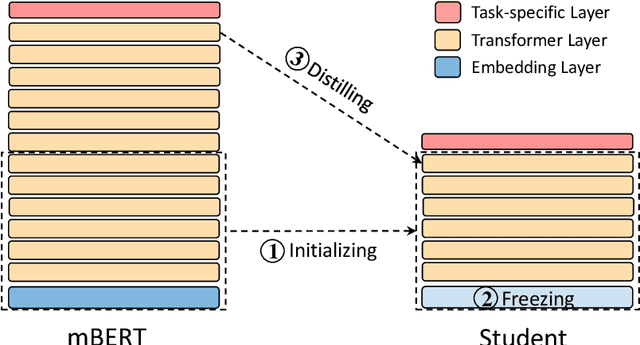
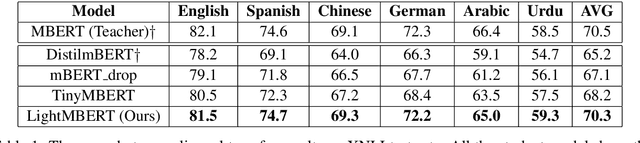
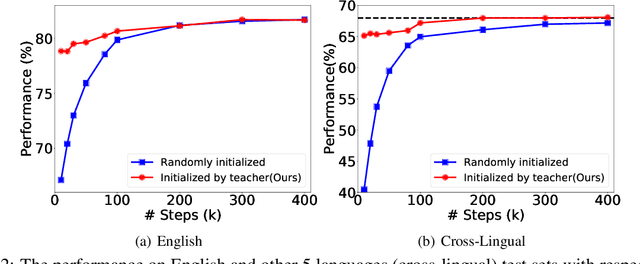

The multilingual pre-trained language models (e.g, mBERT, XLM and XLM-R) have shown impressive performance on cross-lingual natural language understanding tasks. However, these models are computationally intensive and difficult to be deployed on resource-restricted devices. In this paper, we propose a simple yet effective distillation method (LightMBERT) for transferring the cross-lingual generalization ability of the multilingual BERT to a small student model. The experiment results empirically demonstrate the efficiency and effectiveness of LightMBERT, which is significantly better than the baselines and performs comparable to the teacher mBERT.
Improving Task-Agnostic BERT Distillation with Layer Mapping Search
Dec 11, 2020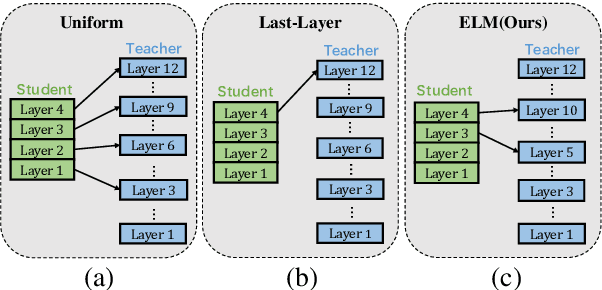

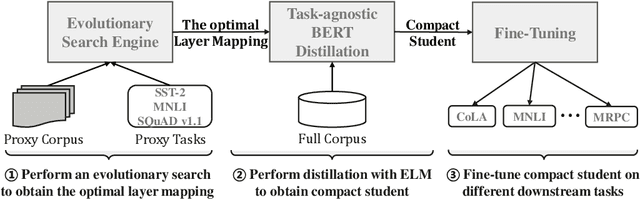
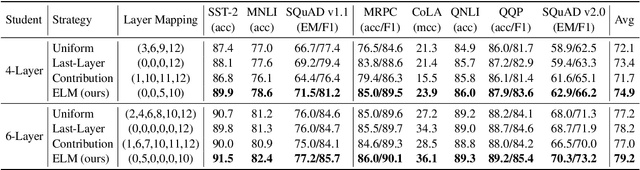
Knowledge distillation (KD) which transfers the knowledge from a large teacher model to a small student model, has been widely used to compress the BERT model recently. Besides the supervision in the output in the original KD, recent works show that layer-level supervision is crucial to the performance of the student BERT model. However, previous works designed the layer mapping strategy heuristically (e.g., uniform or last-layer), which can lead to inferior performance. In this paper, we propose to use the genetic algorithm (GA) to search for the optimal layer mapping automatically. To accelerate the search process, we further propose a proxy setting where a small portion of the training corpus are sampled for distillation, and three representative tasks are chosen for evaluation. After obtaining the optimal layer mapping, we perform the task-agnostic BERT distillation with it on the whole corpus to build a compact student model, which can be directly fine-tuned on downstream tasks. Comprehensive experiments on the evaluation benchmarks demonstrate that 1) layer mapping strategy has a significant effect on task-agnostic BERT distillation and different layer mappings can result in quite different performances; 2) the optimal layer mapping strategy from the proposed search process consistently outperforms the other heuristic ones; 3) with the optimal layer mapping, our student model achieves state-of-the-art performance on the GLUE tasks.
TinyBERT: Distilling BERT for Natural Language Understanding
Sep 24, 2019
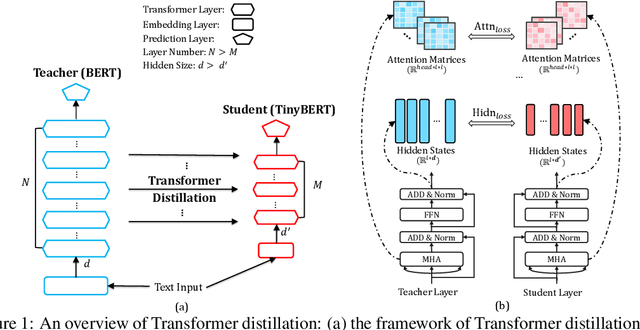
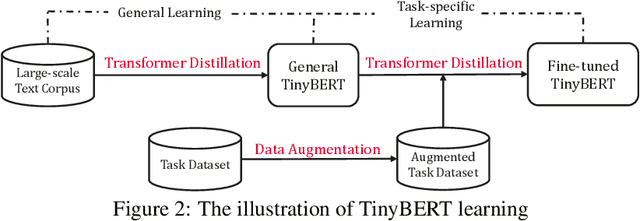
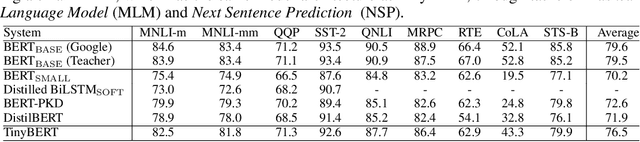
Language model pre-training, such as BERT, has significantly improved the performances of many natural language processing tasks. However, pre-trained language models are usually computationally expensive and memory intensive, so it is difficult to effectively execute them on some resource-restricted devices. To accelerate inference and reduce model size while maintaining accuracy, we firstly propose a novel transformer distillation method that is a specially designed knowledge distillation (KD) method for transformer-based models. By leveraging this new KD method, the plenty of knowledge encoded in a large teacher BERT can be well transferred to a small student TinyBERT. Moreover, we introduce a new two-stage learning framework for TinyBERT, which performs transformer distillation at both the pre-training and task-specific learning stages. This framework ensures that TinyBERT can capture both the general-domain and task-specific knowledge of the teacher BERT. TinyBERT is empirically effective and achieves comparable results with BERT in GLUE datasets, while being 7.5x smaller and 9.4x faster on inference. TinyBERT is also significantly better than state-of-the-art baselines, even with only about 28% parameters and 31% inference time of baselines.