 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating the Super-Resolution Convolutional Neural Network
Aug 01, 2016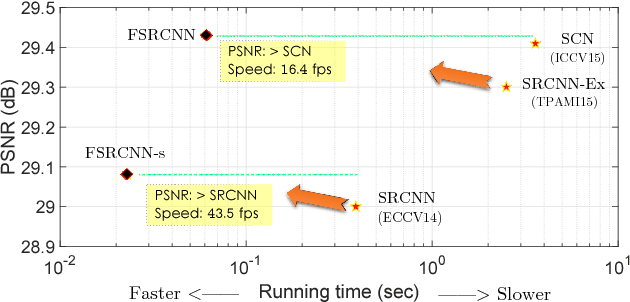
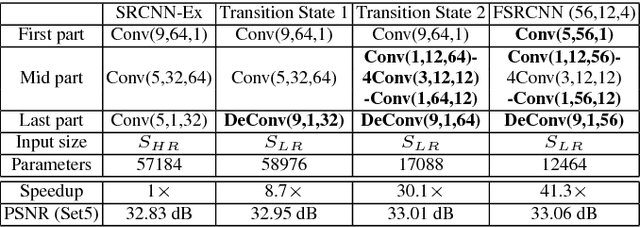
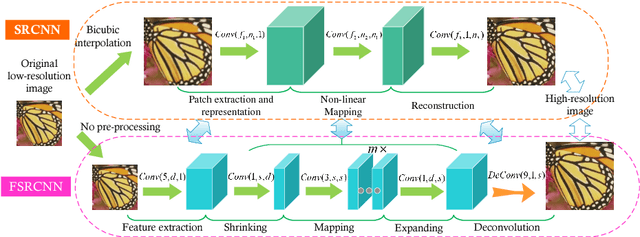
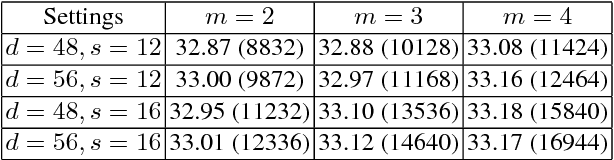
As a successful deep model applied in image super-resolution (SR), the Super-Resolution Convolutional Neural Network (SRCNN) has demonstrated superior performance to the previous hand-crafted models either in speed and restoration quality. However, the high computational cost still hinders it from practical usage that demands real-time performance (24 fps). In this paper, we aim at accelerating the current SRCNN, and propose a compact hourglass-shape CNN structure for faster and better SR. We re-design the SRCNN structure mainly in three aspects. First, we introduce a deconvolution layer at the end of the network, then the mapping is learned directly from the original low-resolution image (without interpolation) to the high-resolution one. Second, we reformulate the mapping layer by shrinking the input feature dimension before mapping and expanding back afterwards. Third, we adopt smaller filter sizes but more mapping layers. The proposed model achieves a speed up of more than 40 times with even superior restoration quality. Further, we present the parameter settings that can achieve real-time performance on a generic CPU while still maintaining good performance. A corresponding transfer strategy is also proposed for fast training and testing across different upscaling factors.
Deep Cascaded Bi-Network for Face Hallucination
Jul 18, 2016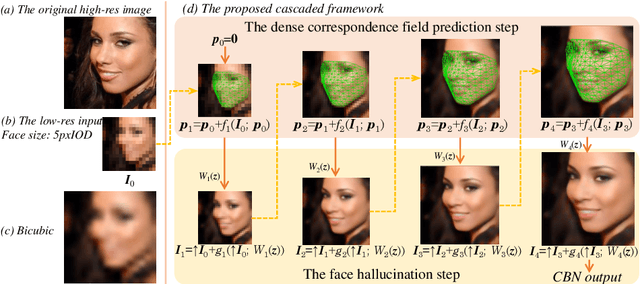
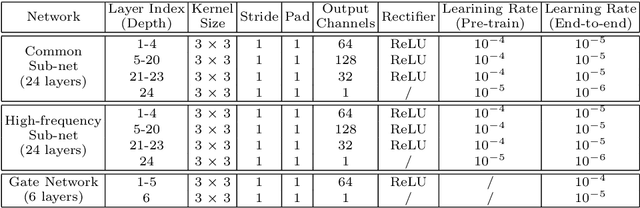

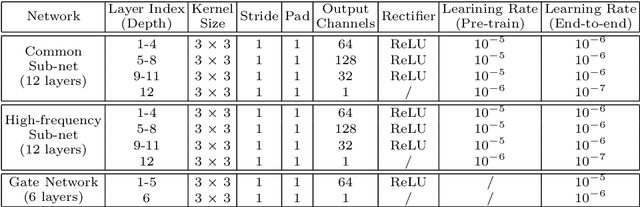
We present a novel framework for hallucinating faces of unconstrained poses and with very low resolution (face size as small as 5pxIOD). In contrast to existing studies that mostly ignore or assume pre-aligned face spatial configuration (e.g. facial landmarks localization or dense correspondence field), we alternatingly optimize two complementary tasks, namely face hallucination and dense correspondence field estimation, in a unified framework. In addition, we propose a new gated deep bi-network that contains two functionality-specialized branches to recover different levels of texture details. Extensive experiments demonstrate that such formulation allows exceptional hallucination quality on in-the-wild low-res faces with significant pose and illumination variations.
Actionness Estimation Using Hybrid Fully Convolutional Networks
Apr 25, 2016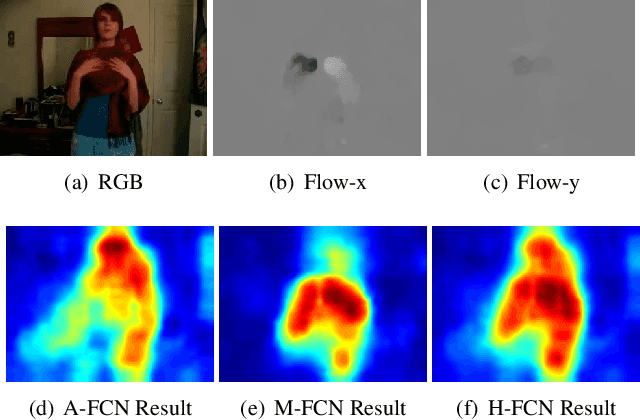
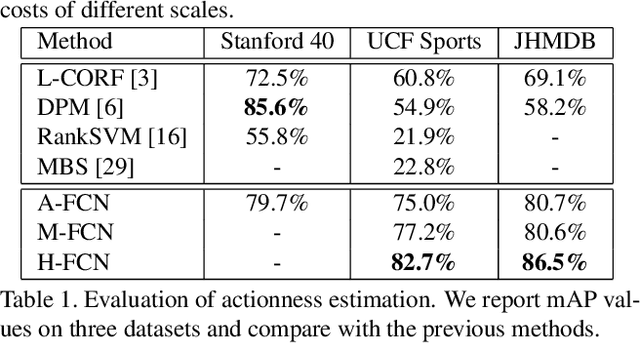
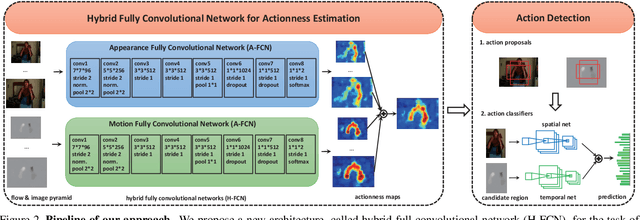
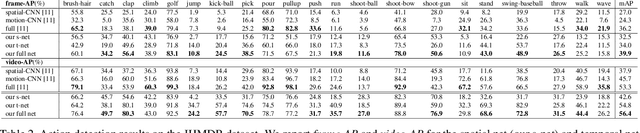
Actionness was introduced to quantify the likelihood of containing a generic action instance at a specific location. Accurate and efficient estimation of actionness is important in video analysis and may benefit other relevant tasks such as action recognition and action detection. This paper presents a new deep architecture for actionness estimation, called hybrid fully convolutional network (H-FCN), which is composed of appearance FCN (A-FCN) and motion FCN (M-FCN). These two FCNs leverage the strong capacity of deep models to estimate actionness maps from the perspectives of static appearance and dynamic motion, respectively. In addition, the fully convolutional nature of H-FCN allows it to efficiently process videos with arbitrary sizes. Experiments are conducted on the challenging datasets of Stanford40, UCF Sports, and JHMDB to verify the effectiveness of H-FCN on actionness estimation, which demonstrate that our method achieves superior performance to previous ones. Moreover, we apply the estimated actionness maps on action proposal generation and action detection. Our actionness maps advance the current state-of-the-art performance of these tasks substantially.
Discriminative Sparse Neighbor Approximation for Imbalanced Learning
Feb 03, 2016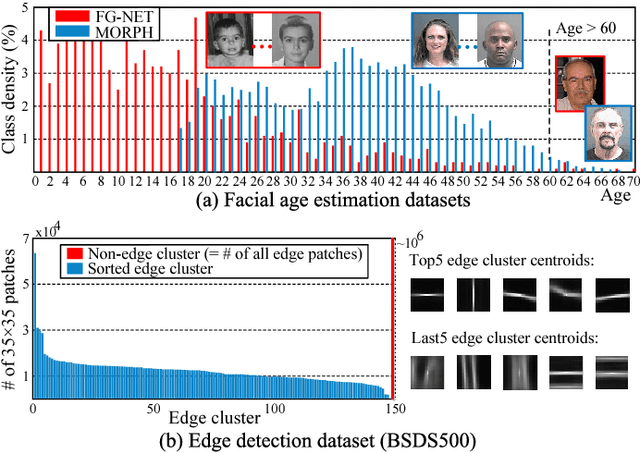

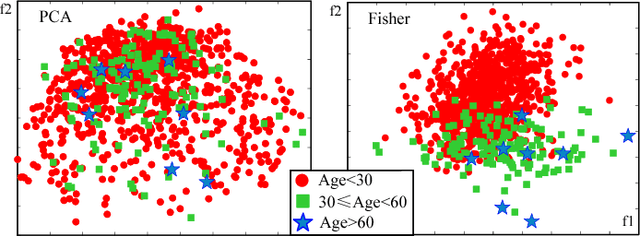
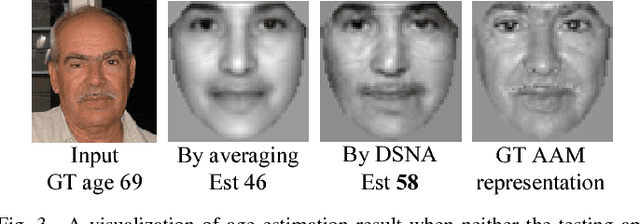
Data imbalance is common in many vision tasks where one or more classes are rare. Without addressing this issue conventional methods tend to be biased toward the majority class with poor predictive accuracy for the minority class. These methods further deteriorate on small, imbalanced data that has a large degree of class overlap. In this study, we propose a novel discriminative sparse neighbor approximation (DSNA) method to ameliorate the effect of class-imbalance during prediction. Specifically, given a test sample, we first traverse it through a cost-sensitive decision forest to collect a good subset of training examples in its local neighborhood. Then we generate from this subset several class-discriminating but overlapping clusters and model each as an affine subspace. From these subspaces, the proposed DSNA iteratively seeks an optimal approximation of the test sample and outputs an unbiased prediction. We show that our method not only effectively mitigates the imbalance issue, but also allows the prediction to extrapolate to unseen data. The latter capability is crucial for achieving accurate prediction on small dataset with limited samples. The proposed imbalanced learning method can be applied to both classification and regression tasks at a wide range of imbalance levels. It significantly outperforms the state-of-the-art methods that do not possess an imbalance handling mechanism, and is found to perform comparably or even better than recent deep learning methods by using hand-crafted features only.
Reading Scene Text in Deep Convolutional Sequences
Dec 20, 2015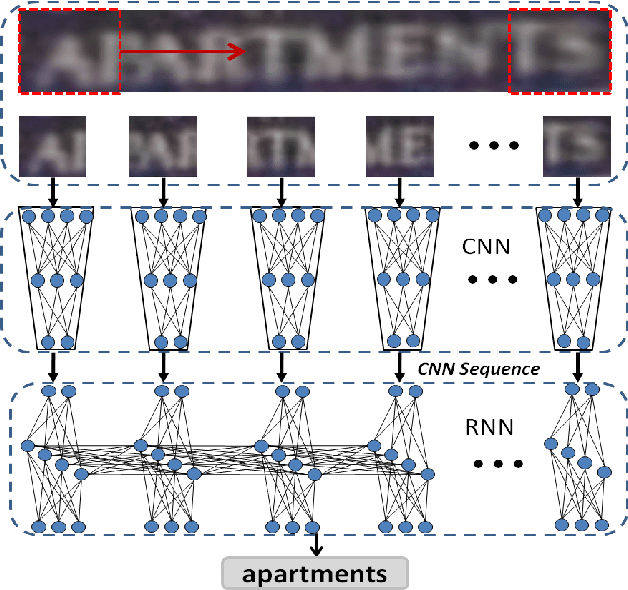
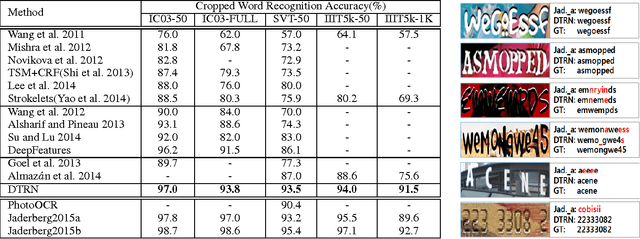
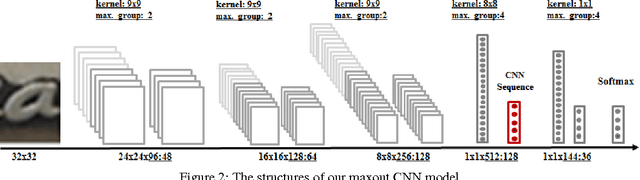
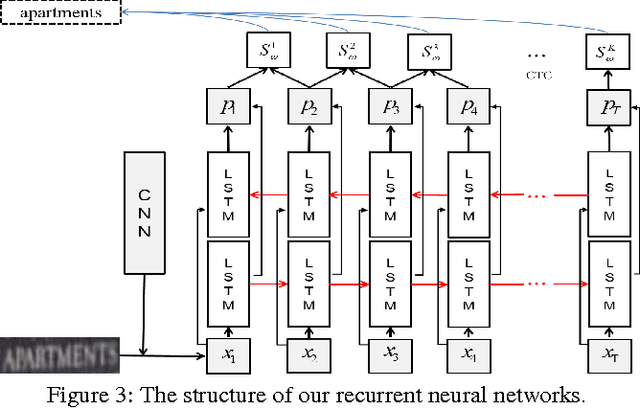
We develop a Deep-Text Recurrent Network (DTRN) that regards scene text reading as a sequence labelling problem. We leverage recent advances of deep convolutional neural networks to generate an ordered high-level sequence from a whole word image, avoiding the difficult character segmentation problem. Then a deep recurrent model, building on long short-term memory (LSTM), is developed to robustly recognize the generated CNN sequences, departing from most existing approaches recognising each character independently. Our model has a number of appealing properties in comparison to existing scene text recognition methods: (i) It can recognise highly ambiguous words by leveraging meaningful context information, allowing it to work reliably without either pre- or post-processing; (ii) the deep CNN feature is robust to various image distortions; (iii) it retains the explicit order information in word image, which is essential to discriminate word strings; (iv) the model does not depend on pre-defined dictionary, and it can process unknown words and arbitrary strings. Codes for the DTRN will be available.
Sparsifying Neural Network Connections for Face Recognition
Dec 07, 2015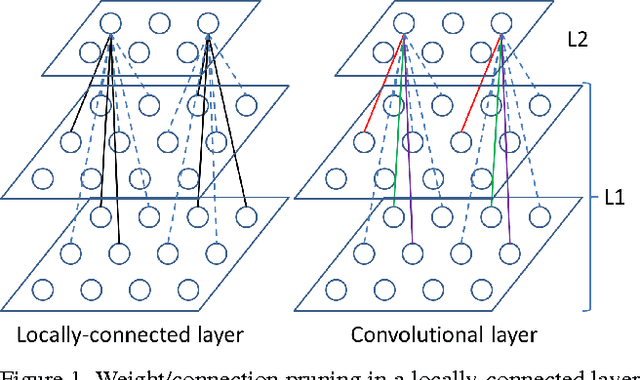
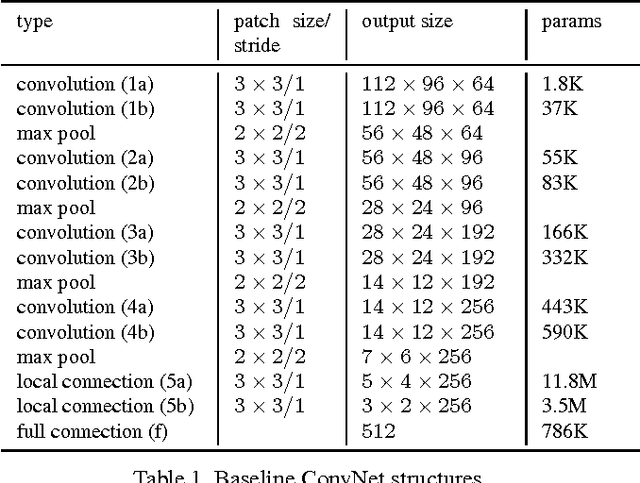

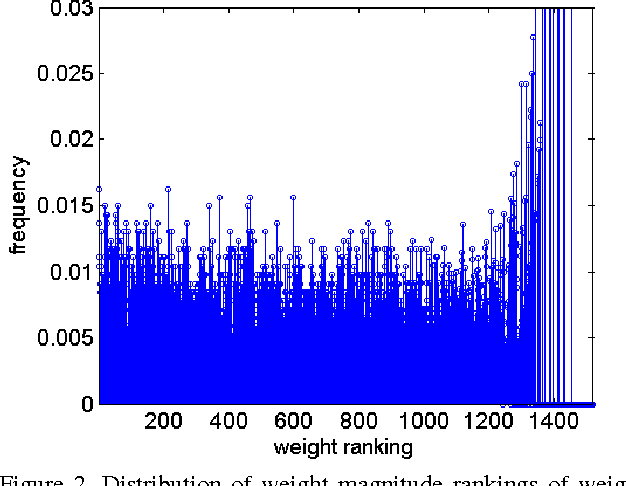
This paper proposes to learn high-performance deep ConvNets with sparse neural connections, referred to as sparse ConvNets, for face recognition. The sparse ConvNets are learned in an iterative way, each time one additional layer is sparsified and the entire model is re-trained given the initial weights learned in previous iterations. One important finding is that directly training the sparse ConvNet from scratch failed to find good solutions for face recognition, while using a previously learned denser model to properly initialize a sparser model is critical to continue learning effective features for face recognition. This paper also proposes a new neural correlation-based weight selection criterion and empirically verifies its effectiveness in selecting informative connections from previously learned models in each iteration. When taking a moderately sparse structure (26%-76% of weights in the dense model), the proposed sparse ConvNet model significantly improves the face recognition performance of the previous state-of-the-art DeepID2+ models given the same training data, while it keeps the performance of the baseline model with only 12% of the original parameters.
Towards Arbitrary-View Face Alignment by Recommendation Trees
Nov 20, 2015
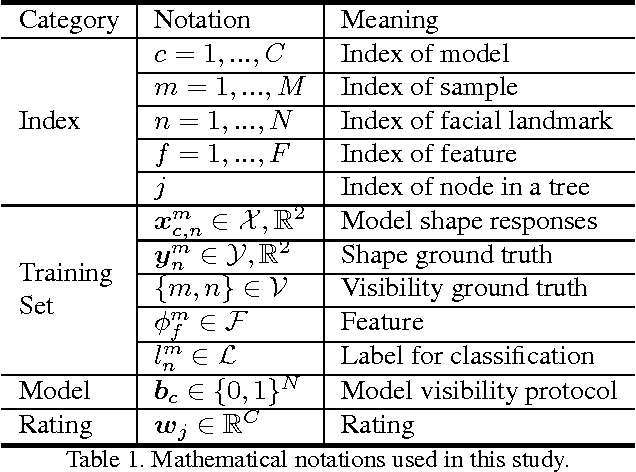
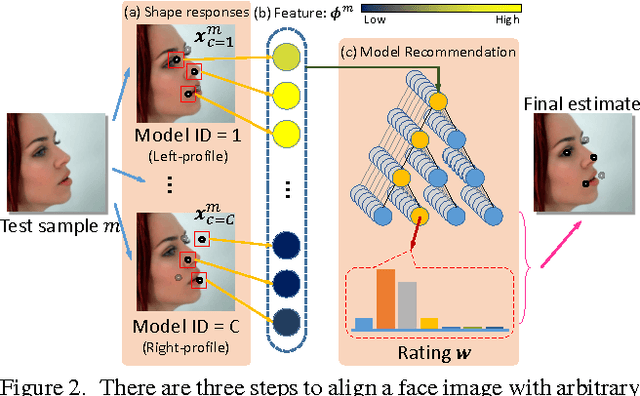

Learning to simultaneously handle face alignment of arbitrary views, e.g. frontal and profile views, appears to be more challenging than we thought. The difficulties lay in i) accommodating the complex appearance-shape relations exhibited in different views, and ii) encompassing the varying landmark point sets due to self-occlusion and different landmark protocols. Most existing studies approach this problem via training multiple viewpoint-specific models, and conduct head pose estimation for model selection. This solution is intuitive but the performance is highly susceptible to inaccurate head pose estimation. In this study, we address this shortcoming through learning an Ensemble of Model Recommendation Trees (EMRT), which is capable of selecting optimal model configuration without prior head pose estimation. The unified framework seamlessly handles different viewpoints and landmark protocols, and it is trained by optimising directly on landmark locations, thus yielding superior results on arbitrary-view face alignment. This is the first study that performs face alignment on the full AFLWdataset with faces of different views including profile view. State-of-the-art performances are also reported on MultiPIE and AFW datasets containing both frontaland profile-view faces.
WIDER FACE: A Face Detection Benchmark
Nov 20, 2015
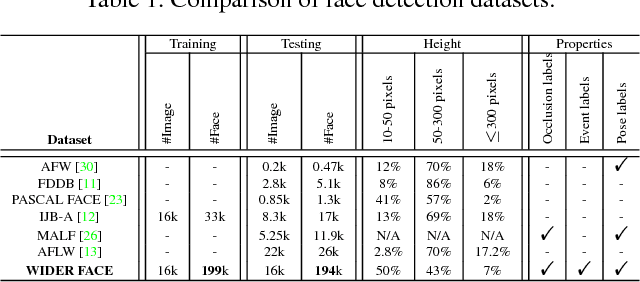

Face detection is one of the most studied topics in the computer vision community. Much of the progresses have been made by the availability of face detection benchmark datasets. We show that there is a gap between current face detection performance and the real world requirements. To facilitate future face detection research, we introduce the WIDER FACE dataset, which is 10 times larger than existing datasets. The dataset contains rich annotations, including occlusions, poses, event categories, and face bounding boxes. Faces in the proposed dataset are extremely challenging due to large variations in scale, pose and occlusion, as shown in Fig. 1. Furthermore, we show that WIDER FACE dataset is an effective training source for face detection. We benchmark several representative detection systems, providing an overview of state-of-the-art performance and propose a solution to deal with large scale variation. Finally, we discuss common failure cases that worth to be further investigated. Dataset can be downloaded at: mmlab.ie.cuhk.edu.hk/projects/WIDERFace
Adjustable Bounded Rectifiers: Towards Deep Binary Representations
Nov 19, 2015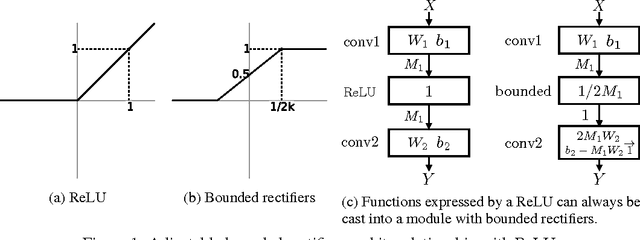



Binary representation is desirable for its memory efficiency, computation speed and robustness. In this paper, we propose adjustable bounded rectifiers to learn binary representations for deep neural networks. While hard constraining representations across layers to be binary makes training unreasonably difficult, we softly encourage activations to diverge from real values to binary by approximating step functions. Our final representation is completely binary. We test our approach on MNIST, CIFAR10, and ILSVRC2012 dataset, and systematically study the training dynamics of the binarization process. Our approach can binarize the last layer representation without loss of performance and binarize all the layers with reasonably small degradations. The memory space that it saves may allow more sophisticated models to be deployed, thus compensating the loss. To the best of our knowledge, this is the first work to report results on current deep network architectures using complete binary middle representations. Given the learned representations, we find that the firing or inhibition of a binary neuron is usually associated with a meaningful interpretation across different classes. This suggests that the semantic structure of a neural network may be manifested through a guided binarization process.
Semantic Image Segmentation via Deep Parsing Network
Sep 24, 2015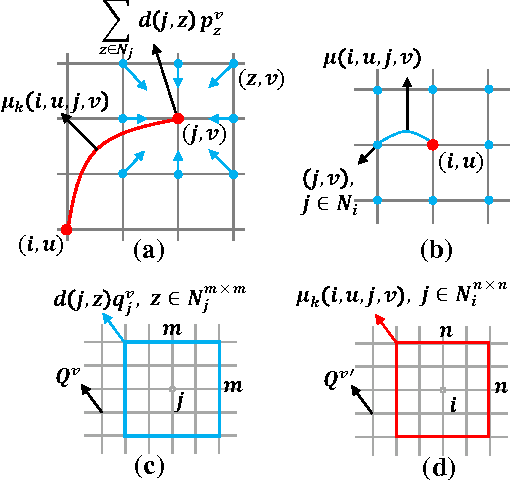
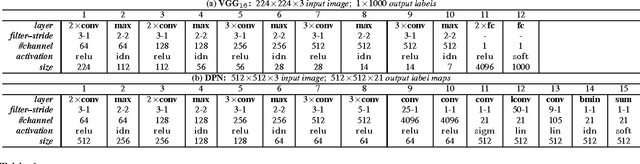
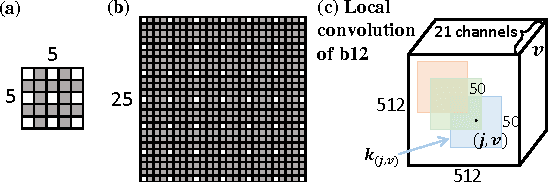

This paper addresses semantic image segmentation by incorporating rich information into Markov Random Field (MRF), including high-order relations and mixture of label contexts. Unlike previous works that optimized MRFs using iterative algorithm, we solve MRF by proposing a Convolutional Neural Network (CNN), namely Deep Parsing Network (DPN), which enables deterministic end-to-end computation in a single forward pass. Specifically, DPN extends a contemporary CNN architecture to model unary terms and additional layers are carefully devised to approximate the mean field algorithm (MF) for pairwise terms. It has several appealing properties. First, different from the recent works that combined CNN and MRF, where many iterations of MF were required for each training image during back-propagation, DPN is able to achieve high performance by approximating one iteration of MF. Second, DPN represents various types of pairwise terms, making many existing works as its special cases. Third, DPN makes MF easier to be parallelized and speeded up in Graphical Processing Unit (GPU). DPN is thoroughly evaluated on the PASCAL VOC 2012 dataset, where a single DPN model yields a new state-of-the-art segmentation accuracy.