 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT-Powered Hierarchical Comparisons for Image Classification
Nov 01, 2023

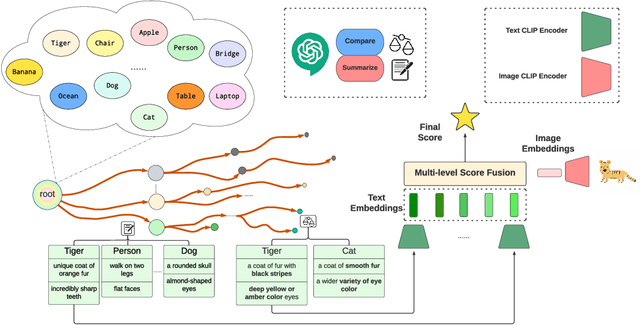

The zero-shot open-vocabulary challenge in image classification is tackled by pretrained vision-language models like CLIP, which benefit from incorporating class-specific knowledge from large language models (LLMs) like ChatGPT. However, biases in CLIP lead to similar descriptions for distinct but related classes, prompting our novel image classification framework via hierarchical comparisons: using LLMs to recursively group classes into hierarchies and classifying images by comparing image-text embeddings at each hierarchy level, resulting in an intuitive, effective, and explainable approach.
PrObeD: Proactive Object Detection Wrapper
Oct 28, 2023



Previous research in $2D$ object detection focuses on various tasks, including detecting objects in generic and camouflaged images. These works are regarded as passive works for object detection as they take the input image as is. However, convergence to global minima is not guaranteed to be optimal in neural networks; therefore, we argue that the trained weights in the object detector are not optimal. To rectify this problem, we propose a wrapper based on proactive schemes, PrObeD, which enhances the performance of these object detectors by learning a signal. PrObeD consists of an encoder-decoder architecture, where the encoder network generates an image-dependent signal termed templates to encrypt the input images, and the decoder recovers this template from the encrypted images. We propose that learning the optimum template results in an object detector with an improved detection performance. The template acts as a mask to the input images to highlight semantics useful for the object detector. Finetuning the object detector with these encrypted images enhances the detection performance for both generic and camouflaged. Our experiments on MS-COCO, CAMO, COD$10$K, and NC$4$K datasets show improvement over different detectors after applying PrObeD. Our models/codes are available at https://github.com/vishal3477/Proactive-Object-Detection.
Learning Clothing and Pose Invariant 3D Shape Representation for Long-Term Person Re-Identification
Aug 29, 2023



Long-Term Person Re-Identification (LT-ReID) has become increasingly crucial in computer vision and biometrics. In this work, we aim to extend LT-ReID beyond pedestrian recognition to include a wider range of real-world human activities while still accounting for cloth-changing scenarios over large time gaps. This setting poses additional challenges due to the geometric misalignment and appearance ambiguity caused by the diversity of human pose and clothing. To address these challenges, we propose a new approach 3DInvarReID for (i) disentangling identity from non-identity components (pose, clothing shape, and texture) of 3D clothed humans, and (ii) reconstructing accurate 3D clothed body shapes and learning discriminative features of naked body shapes for person ReID in a joint manner. To better evaluate our study of LT-ReID, we collect a real-world dataset called CCDA, which contains a wide variety of human activities and clothing changes. Experimentally, we show the superior performance of our approach for person ReID.
Dialogue for Prompting: a Policy-Gradient-Based Discrete Prompt Optimization for Few-shot Learning
Aug 14, 2023



Prompt-based pre-trained language models (PLMs) paradigm have succeeded substantially in few-shot natural language processing (NLP) tasks. However, prior discrete prompt optimization methods require expert knowledge to design the base prompt set and identify high-quality prompts, which is costly, inefficient, and subjective. Meanwhile, existing continuous prompt optimization methods improve the performance by learning the ideal prompts through the gradient information of PLMs, whose high computational cost, and low readability and generalizability are often concerning. To address the research gap, we propose a Dialogue-comprised Policy-gradient-based Discrete Prompt Optimization ($DP_2O$) method. We first design a multi-round dialogue alignment strategy for readability prompt set generation based on GPT-4. Furthermore, we propose an efficient prompt screening metric to identify high-quality prompts with linear complexity. Finally, we construct a reinforcement learning (RL) framework based on policy gradients to match the prompts to inputs optimally. By training a policy network with only 0.67% of the PLM parameter size on the tasks in the few-shot setting, $DP_2O$ outperforms the state-of-the-art (SOTA) method by 1.52% in accuracy on average on four open-source datasets. Moreover, subsequent experiments also demonstrate that $DP_2O$ has good universality, robustness, and generalization ability.
FarSight: A Physics-Driven Whole-Body Biometric System at Large Distance and Altitude
Jun 29, 2023



Whole-body biometric recognition is an important area of research due to its vast applications in law enforcement, border security, and surveillance. This paper presents the end-to-end design, development and evaluation of FarSight, an innovative software system designed for whole-body (fusion of face, gait and body shape) biometric recognition. FarSight accepts videos from elevated platforms and drones as input and outputs a candidate list of identities from a gallery. The system is designed to address several challenges, including (i) low-quality imagery, (ii) large yaw and pitch angles, (iii) robust feature extraction to accommodate large intra-person variabilities and large inter-person similarities, and (iv) the large domain gap between training and test sets. FarSight combines the physics of imaging and deep learning models to enhance image restoration and biometric feature encoding. We test FarSight's effectiveness using the newly acquired IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) dataset. Notably, FarSight demonstrated a substantial performance increase on the BRIAR dataset, with gains of +11.82% Rank-20 identification and +11.3% TAR@1% FAR.
Tame a Wild Camera: In-the-Wild Monocular Camera Calibration
Jun 19, 2023



3D sensing for monocular in-the-wild images, e.g., depth estimation and 3D object detection, has become increasingly important. However, the unknown intrinsic parameter hinders their development and deployment. Previous methods for the monocular camera calibration rely on specific 3D objects or strong geometry prior, such as using a checkerboard or imposing a Manhattan World assumption. This work solves the problem from the other perspective by exploiting the monocular 3D prior. Our method is assumption-free and calibrates the complete $4$ Degree-of-Freedom (DoF) intrinsic parameters. First, we demonstrate intrinsic is solved from two well-studied monocular priors, i.e., monocular depthmap, and surface normal map. However, this solution imposes a low-bias and low-variance requirement for depth estimation. Alternatively, we introduce a novel monocular 3D prior, the incidence field, defined as the incidence rays between points in 3D space and pixels in the 2D imaging plane. The incidence field is a pixel-wise parametrization of the intrinsic invariant to image cropping and resizing. With the estimated incidence field, a robust RANSAC algorithm recovers intrinsic. We demonstrate the effectiveness of our method by showing superior performance on synthetic and zero-shot testing datasets. Beyond calibration, we demonstrate downstream applications in image manipulation detection & restoration, uncalibrated two-view pose estimation, and 3D sensing. Codes, models, and data will be held in https://github.com/ShngJZ/WildCamera.
DCFace: Synthetic Face Generation with Dual Condition Diffusion Model
Apr 14, 2023



Generating synthetic datasets for training face recognition models is challenging because dataset generation entails more than creating high fidelity images. It involves generating multiple images of same subjects under different factors (\textit{e.g.}, variations in pose, illumination, expression, aging and occlusion) which follows the real image conditional distribution. Previous works have studied the generation of synthetic datasets using GAN or 3D models. In this work, we approach the problem from the aspect of combining subject appearance (ID) and external factor (style) conditions. These two conditions provide a direct way to control the inter-class and intra-class variations. To this end, we propose a Dual Condition Face Generator (DCFace) based on a diffusion model. Our novel Patch-wise style extractor and Time-step dependent ID loss enables DCFace to consistently produce face images of the same subject under different styles with precise control. Face recognition models trained on synthetic images from the proposed DCFace provide higher verification accuracies compared to previous works by $6.11\%$ on average in $4$ out of $5$ test datasets, LFW, CFP-FP, CPLFW, AgeDB and CALFW. Code is available at https://github.com/mk-minchul/dcface
MaLP: Manipulation Localization Using a Proactive Scheme
Apr 04, 2023



Advancements in the generation quality of various Generative Models (GMs) has made it necessary to not only perform binary manipulation detection but also localize the modified pixels in an image. However, prior works termed as passive for manipulation localization exhibit poor generalization performance over unseen GMs and attribute modifications. To combat this issue, we propose a proactive scheme for manipulation localization, termed MaLP. We encrypt the real images by adding a learned template. If the image is manipulated by any GM, this added protection from the template not only aids binary detection but also helps in identifying the pixels modified by the GM. The template is learned by leveraging local and global-level features estimated by a two-branch architecture. We show that MaLP performs better than prior passive works. We also show the generalizability of MaLP by testing on 22 different GMs, providing a benchmark for future research on manipulation localization. Finally, we show that MaLP can be used as a discriminator for improving the generation quality of GMs. Our models/codes are available at www.github.com/vishal3477/pro_loc.
PMatch: Paired Masked Image Modeling for Dense Geometric Matching
Mar 30, 2023

Dense geometric matching determines the dense pixel-wise correspondence between a source and support image corresponding to the same 3D structure. Prior works employ an encoder of transformer blocks to correlate the two-frame features. However, existing monocular pretraining tasks, e.g., image classification, and masked image modeling (MIM), can not pretrain the cross-frame module, yielding less optimal performance. To resolve this, we reformulate the MIM from reconstructing a single masked image to reconstructing a pair of masked images, enabling the pretraining of transformer module. Additionally, we incorporate a decoder into pretraining for improved upsampling results. Further, to be robust to the textureless area, we propose a novel cross-frame global matching module (CFGM). Since the most textureless area is planar surfaces, we propose a homography loss to further regularize its learning. Combined together, we achieve the State-of-The-Art (SoTA) performance on geometric matching. Codes and models are available at https://github.com/ShngJZ/PMatch.
Hierarchical Fine-Grained Image Forgery Detection and Localization
Mar 30, 2023



Differences in forgery attributes of images generated in CNN-synthesized and image-editing domains are large, and such differences make a unified image forgery detection and localization (IFDL) challenging. To this end, we present a hierarchical fine-grained formulation for IFDL representation learning. Specifically, we first represent forgery attributes of a manipulated image with multiple labels at different levels. Then we perform fine-grained classification at these levels using the hierarchical dependency between them. As a result, the algorithm is encouraged to learn both comprehensive features and inherent hierarchical nature of different forgery attributes, thereby improving the IFDL representation. Our proposed IFDL framework contains three components: multi-branch feature extractor, localization and classification modules. Each branch of the feature extractor learns to classify forgery attributes at one level, while localization and classification modules segment the pixel-level forgery region and detect image-level forgery, respectively. Lastly, we construct a hierarchical fine-grained dataset to facilitate our study. We demonstrate the effectiveness of our method on $7$ different benchmarks, for both tasks of IFDL and forgery attribute classification. Our source code and dataset can be found: \href{https://github.com/CHELSEA234/HiFi_IFDL}{github.com/CHELSEA234/HiFi-IFDL}.