 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Understanding Generic Objects: Modeling, Segmentation, and Reconstruction
Paper and Code
Apr 02, 2021
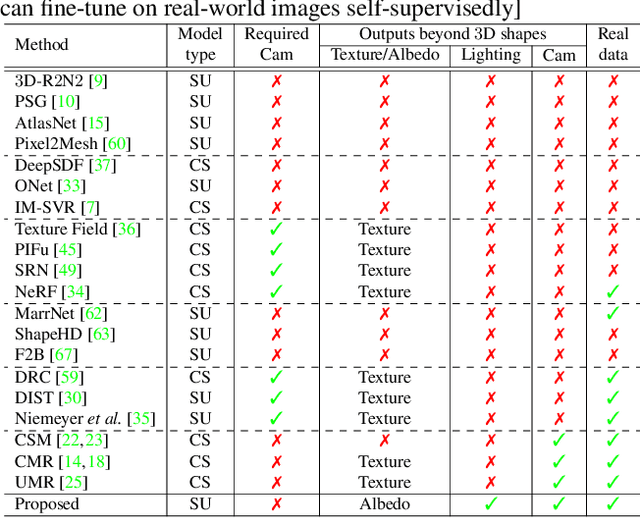
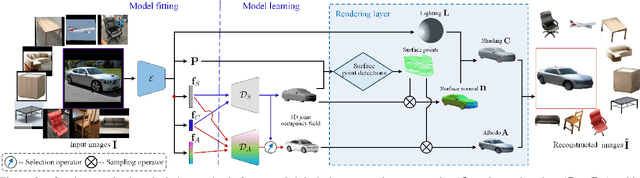
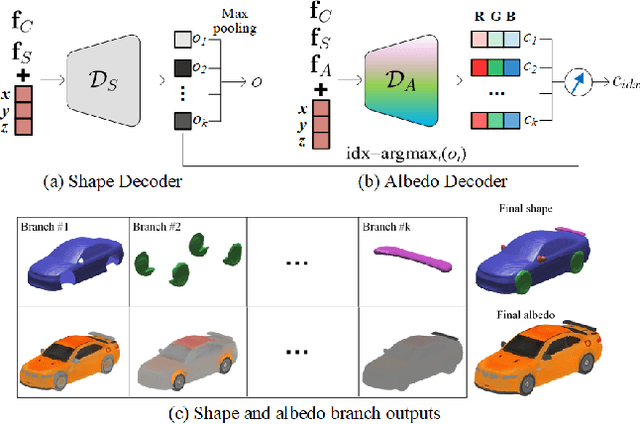
Inferring 3D structure of a generic object from a 2D image is a long-standing objective of computer vision. Conventional approaches either learn completely from CAD-generated synthetic data, which have difficulty in inference from real images, or generate 2.5D depth image via intrinsic decomposition, which is limited compared to the full 3D reconstruction. One fundamental challenge lies in how to leverage numerous real 2D images without any 3D ground truth. To address this issue, we take an alternative approach with semi-supervised learning. That is, for a 2D image of a generic object, we decompose it into latent representations of category, shape and albedo, lighting and camera projection matrix, decode the representations to segmented 3D shape and albedo respectively, and fuse these components to render an image well approximating the input image. Using a category-adaptive 3D joint occupancy field (JOF), we show that the complete shape and albedo modeling enables us to leverage real 2D images in both modeling and model fitting. The effectiveness of our approach is demonstrated through superior 3D reconstruction from a single image, being either synthetic or real, and shape segmentation.