 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaDreamer: Efficient Text-to-3D Creation With Disentangling Geometry and Texture
Nov 16, 2023Generative models for 3D object synthesis have seen significant advancements with the incorporation of prior knowledge distilled from 2D diffusion models. Nevertheless, challenges persist in the form of multi-view geometric inconsistencies and slow generation speeds within the existing 3D synthesis frameworks. This can be attributed to two factors: firstly, the deficiency of abundant geometric a priori knowledge in optimization, and secondly, the entanglement issue between geometry and texture in conventional 3D generation methods.In response, we introduce MetaDreammer, a two-stage optimization approach that leverages rich 2D and 3D prior knowledge. In the first stage, our emphasis is on optimizing the geometric representation to ensure multi-view consistency and accuracy of 3D objects. In the second stage, we concentrate on fine-tuning the geometry and optimizing the texture, thereby achieving a more refined 3D object. Through leveraging 2D and 3D prior knowledge in two stages, respectively, we effectively mitigate the interdependence between geometry and texture. MetaDreamer establishes clear optimization objectives for each stage, resulting in significant time savings in the 3D generation process. Ultimately, MetaDreamer can generate high-quality 3D objects based on textual prompts within 20 minutes, and to the best of our knowledge, it is the most efficient text-to-3D generation method. Furthermore, we introduce image control into the process, enhancing the controllability of 3D generation. Extensive empirical evidence confirms that our method is not only highly efficient but also achieves a quality level that is at the forefront of current state-of-the-art 3D generation techniques.
Evaluating the Adversarial Robustness of Convolution-based Human Motion Prediction
Jul 03, 2023Human motion prediction has achieved a brilliant performance with the help of CNNs, which facilitates human-machine cooperation. However, currently, there is no work evaluating the potential risk in human motion prediction when facing adversarial attacks, which may cause danger in real applications. The adversarial attack will face two problems against human motion prediction: 1. For naturalness, pose data is highly related to the physical dynamics of human skeletons where Lp norm constraints cannot constrain the adversarial example well; 2. Unlike the pixel value in images, pose data is diverse at scale because of the different acquisition equipment and the data processing, which makes it hard to set fixed parameters to perform attacks. To solve the problems above, we propose a new adversarial attack method that perturbs the input human motion sequence by maximizing the prediction error with physical constraints. Specifically, we introduce a novel adaptable scheme that facilitates the attack to suit the scale of the target pose and two physical constraints to enhance the imperceptibility of the adversarial example. The evaluating experiments on three datasets show that the prediction errors of all target models are enlarged significantly, which means current convolution-based human motion prediction models can be easily disturbed under the proposed attack. The quantitative analysis shows that prior knowledge and semantic information modeling can be the key to the adversarial robustness of human motion predictors. The qualitative results indicate that the adversarial sample is hard to be noticed when compared frame by frame but is relatively easy to be detected when the sample is animated.
Self-supervised Domain Adaptation for Breaking the Limits of Low-quality Fundus Image Quality Enhancement
Jan 17, 2023Retinal fundus images have been applied for the diagnosis and screening of eye diseases, such as Diabetic Retinopathy (DR) or Diabetic Macular Edema (DME). However, both low-quality fundus images and style inconsistency potentially increase uncertainty in the diagnosis of fundus disease and even lead to misdiagnosis by ophthalmologists. Most of the existing image enhancement methods mainly focus on improving the image quality by leveraging the guidance of high-quality images, which is difficult to be collected in medical applications. In this paper, we tackle image quality enhancement in a fully unsupervised setting, i.e., neither paired images nor high-quality images. To this end, we explore the potential of the self-supervised task for improving the quality of fundus images without the requirement of high-quality reference images. Specifically, we construct multiple patch-wise domains via an auxiliary pre-trained quality assessment network and a style clustering. To achieve robust low-quality image enhancement and address style inconsistency, we formulate two self-supervised domain adaptation tasks to disentangle the features of image content, low-quality factor and style information by exploring intrinsic supervision signals within the low-quality images. Extensive experiments are conducted on EyeQ and Messidor datasets, and results show that our DASQE method achieves new state-of-the-art performance when only low-quality images are available.
Co-training with High-Confidence Pseudo Labels for Semi-supervised Medical Image Segmentation
Jan 11, 2023High-quality pseudo labels are essential for semi-supervised semantic segmentation. Consistency regularization and pseudo labeling-based semi-supervised methods perform co-training using the pseudo labels from multi-view inputs. However, such co-training models tend to converge early to a consensus during training, so that the models degenerate to the self-training ones. Besides, the multi-view inputs are generated by perturbing or augmenting the original images, which inevitably introduces noise into the input leading to low-confidence pseudo labels. To address these issues, we propose an \textbf{U}ncertainty-guided Collaborative Mean-Teacher (UCMT) for semi-supervised semantic segmentation with the high-confidence pseudo labels. Concretely, UCMT consists of two main components: 1) collaborative mean-teacher (CMT) for encouraging model disagreement and performing co-training between the sub-networks, and 2) uncertainty-guided region mix (UMIX) for manipulating the input images according to the uncertainty maps of CMT and facilitating CMT to produce high-confidence pseudo labels. Combining the strengths of UMIX with CMT, UCMT can retain model disagreement and enhance the quality of pseudo labels for the co-training segmentation. Extensive experiments on four public medical image datasets including 2D and 3D modalities demonstrate the superiority of UCMT over the state-of-the-art. Code is available at: https://github.com/Senyh/UCMT.
Learning Dynamic Correlations in Spatiotemporal Graphs for Motion Prediction
Apr 14, 2022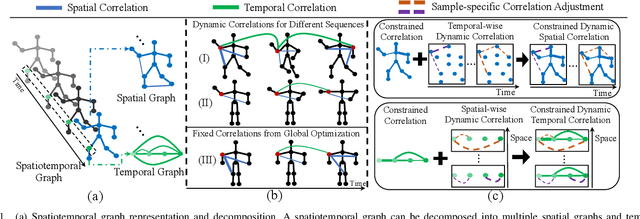
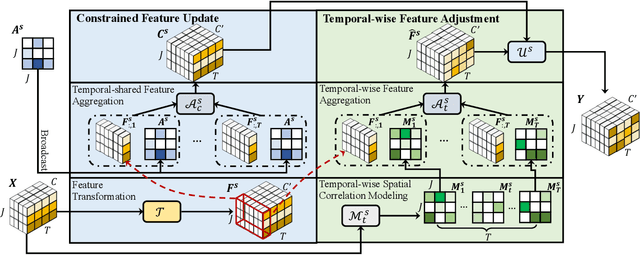
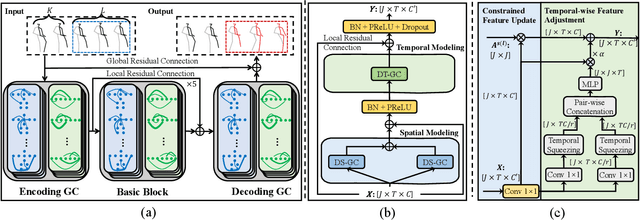

Human motion prediction is a challenge task due to the dynamic spatiotemporal graph correlations in different motion sequences. How to efficiently represent spatiotemporal graph correlations and model dynamic correlation variances between different motion sequences is a challenge for spatiotemporal graph representation in motion prediction. In this work, we present Dynamic SpatioTemporal Graph Convolution (DSTD-GC). The proposed DSTD-GC decomposes dynamic spatiotemporal graph modeling into a combination of Dynamic Spatial Graph Convolution (DS-GC) and Dynamic Temporal Graph Convolution (DT-GC). As human motions are subject to common constraints like body connections and present dynamic motion patterns from different samples, we present Constrained Dynamic Correlation Modeling strategy to represent the spatial/temporal graph as a shared spatial/temporal correlation and a function to extract temporal-specific /spatial-specific adjustments for each sample. The modeling strategy represents the spatiotemporal graph with 28.6\% parameters of the state-of-the-art static decomposition representation while also explicitly models sample-specific spatiotemporal correlation variances. Moreover, we also mathematically reformulating spatiotemporal graph convolutions and their decomposed variants into a unified form and find that DSTD-GC relaxes strict constraints of other graph convolutions, leading to a stronger representation capability. Combining DSTD-GC with prior knowledge, we propose a powerful spatiotemporal graph convolution network called DSTD-GCN which outperforms state-of-the-art methods on the Human3.6M and CMU Mocap datasets in prediction accuracy with fewest parameters.
ASCNet: Action Semantic Consistent Learning of Arbitrary Progress Levels for Early Action Prediction
Jan 23, 2022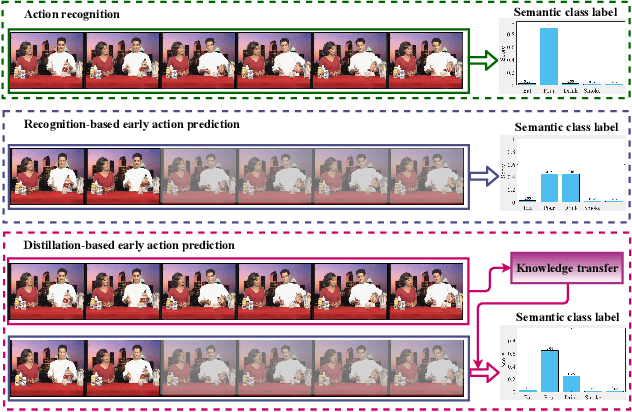
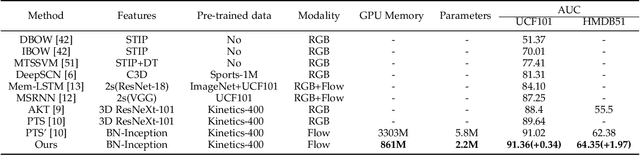
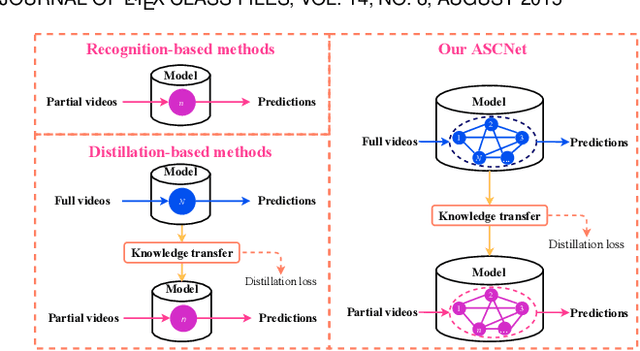
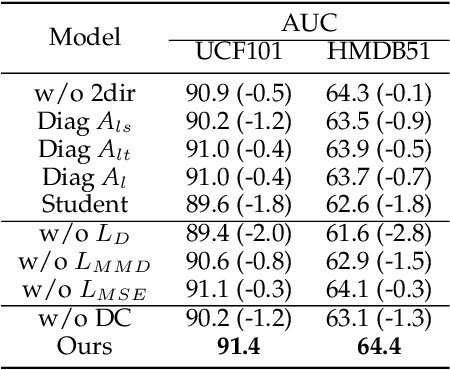
Early action prediction aims to recognize human actions from only a part of action execution, which is an important video analysis task for many practical applications. Most prior works treat partial or full videos as a whole, which neglects the semantic consistencies among partial videos of various progress levels due to their large intra-class variances. In contrast, we partition original partial or full videos to form a series of new partial videos and mine the Action Semantic Consistent Knowledge (ASCK) among these new partial videos evolving in arbitrary progress levels. Moreover, a novel Action Semantic Consistent learning network (ASCNet) under the teacher-student framework is proposed for early action prediction. Specifically, we treat partial videos as nodes and their action semantic consistencies as edges. Then we build a bi-directional fully connected graph for the teacher network and a single-directional fully connected graph for the student network to model ASCK among partial videos. The MSE and MMD losses are incorporated as our distillation loss to further transfer the ASCK from the teacher to the student network. Extensive experiments and ablative studies have been conducted, demonstrating the effectiveness of modeling ASCK for early action prediction. With the proposed ASCNet, we have achieved state-of-the-art performance on two benchmarks. The code will be released if the paper is accepted.
Mobile Augmented Reality: User Interfaces, Frameworks, and Intelligence
Jun 16, 2021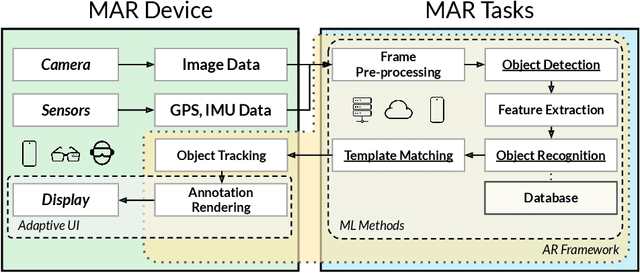
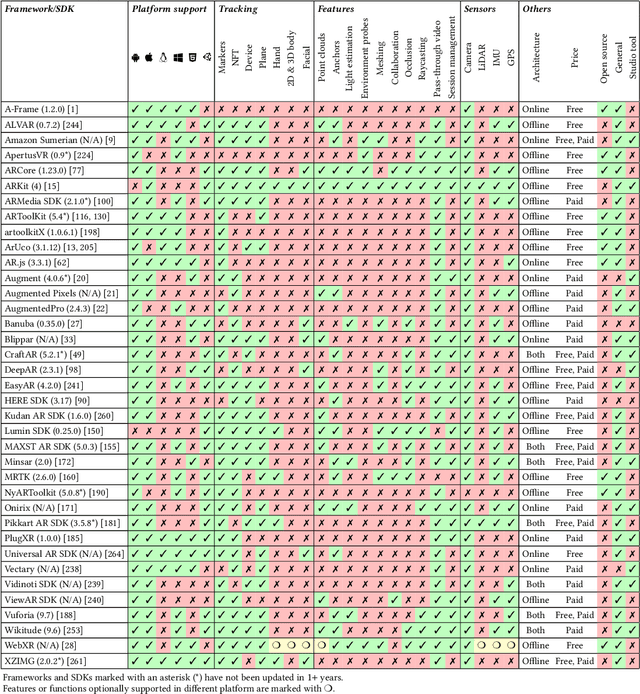
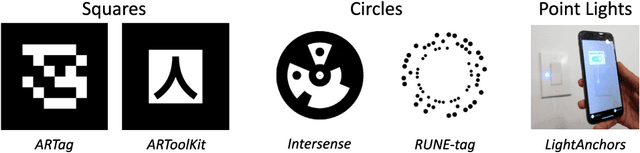
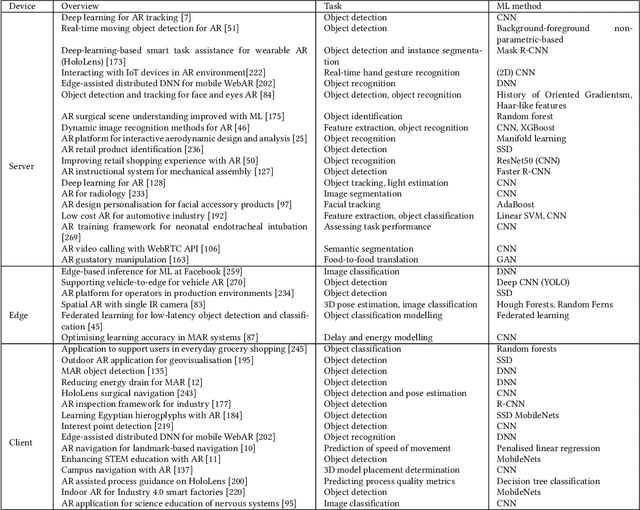
Mobile Augmented Reality (MAR) integrates computer-generated virtual objects with physical environments for mobile devices. MAR systems enable users to interact with MAR devices, such as smartphones and head-worn wearables, and performs seamless transitions from the physical world to a mixed world with digital entities. These MAR systems support user experiences by using MAR devices to provide universal accessibility to digital contents. Over the past 20 years, a number of MAR systems have been developed, however, the studies and design of MAR frameworks have not yet been systematically reviewed from the perspective of user-centric design. This article presents the first effort of surveying existing MAR frameworks (count: 37) and further discusses the latest studies on MAR through a top-down approach: 1) MAR applications; 2) MAR visualisation techniques adaptive to user mobility and contexts; 3) systematic evaluation of MAR frameworks including supported platforms and corresponding features such as tracking, feature extraction plus sensing capabilities; and 4) underlying machine learning approaches supporting intelligent operations within MAR systems. Finally, we summarise the development of emerging research fields, current state-of-the-art, and discuss the important open challenges and possible theoretical and technical directions. This survey aims to benefit both researchers and MAR system developers alike.
A robust low data solution: dimension prediction of semiconductor nanorods
Oct 27, 2020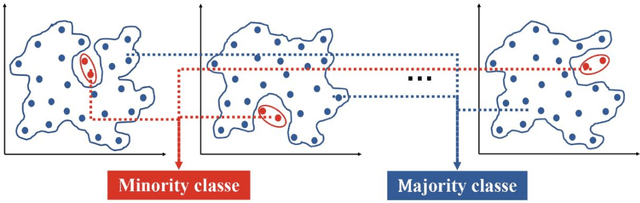
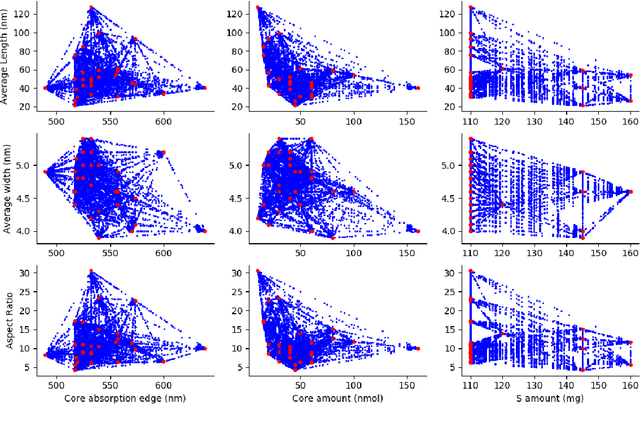
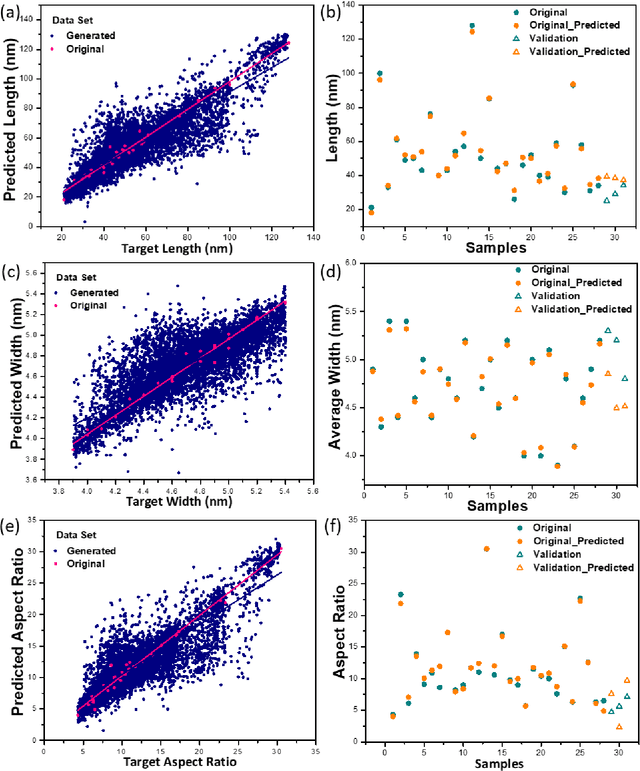
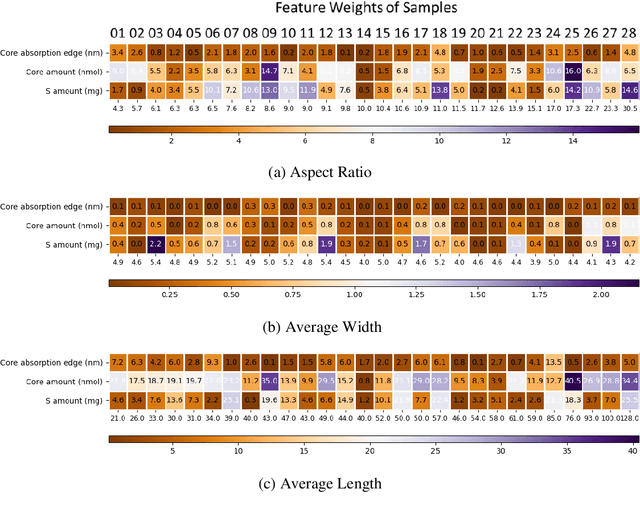
Precise control over dimension of nanocrystals is critical to tune the properties for various applications. However, the traditional control through experimental optimization is slow, tedious and time consuming. Herein a robust deep neural network-based regression algorithm has been developed for precise prediction of length, width, and aspect ratios of semiconductor nanorods (NRs). Given there is limited experimental data available (28 samples), a Synthetic Minority Oversampling Technique for regression (SMOTE-REG) has been employed for the first time for data generation. Deep neural network is further applied to develop regression model which demonstrated the well performed prediction on both the original and generated data with a similar distribution. The prediction model is further validated with additional experimental data, showing accurate prediction results. Additionally, Local Interpretable Model-Agnostic Explanations (LIME) is used to interpret the weight for each variable, which corresponds to its importance towards the target dimension, which is approved to be well correlated well with experimental observations.
SDMTL: Semi-Decoupled Multi-grained Trajectory Learning for 3D human motion prediction
Oct 11, 2020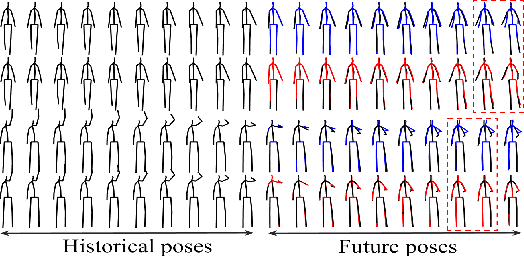
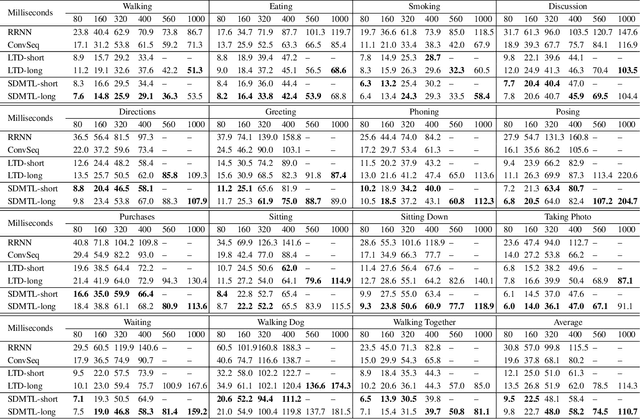
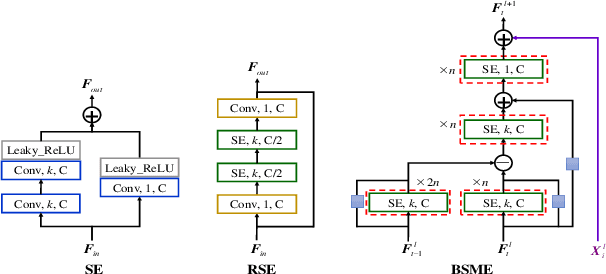
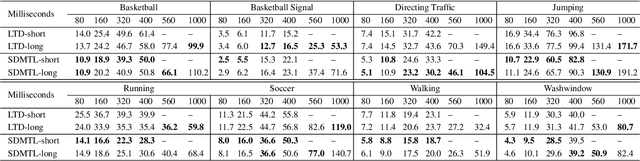
Predicting future human motion is critical for intelligent robots to interact with humans in the real world, and human motion has the nature of multi-granularity. However, most of the existing work either implicitly modeled multi-granularity information via fixed modes or focused on modeling a single granularity, making it hard to well capture this nature for accurate predictions. In contrast, we propose a novel end-to-end network, Semi-Decoupled Multi-grained Trajectory Learning network (SDMTL), to predict future poses, which not only flexibly captures rich multi-grained trajectory information but also aggregates multi-granularity information for predictions. Specifically, we first introduce a Brain-inspired Semi-decoupled Motion-sensitive Encoding module (BSME), effectively capturing spatiotemporal features in a semi-decoupled manner. Then, we capture the temporal dynamics of motion trajectory at multi-granularity, including fine granularity and coarse granularity. We learn multi-grained trajectory information using BSMEs hierarchically and further capture the information of temporal evolutional directions at each granularity by gathering the outputs of BSMEs at each granularity and applying temporal convolutions along the motion trajectory. Next, the captured motion dynamics can be further enhanced by aggregating the information of multi-granularity with a weighted summation scheme. Finally, experimental results on two benchmarks, including Human3.6M and CMU-Mocap, show that our method achieves state-of-the-art performance, demonstrating the effectiveness of our proposed method. The code will be available if the paper is accepted.
AGVNet: Attention Guided Velocity Learning for 3D Human Motion Prediction
Jun 09, 2020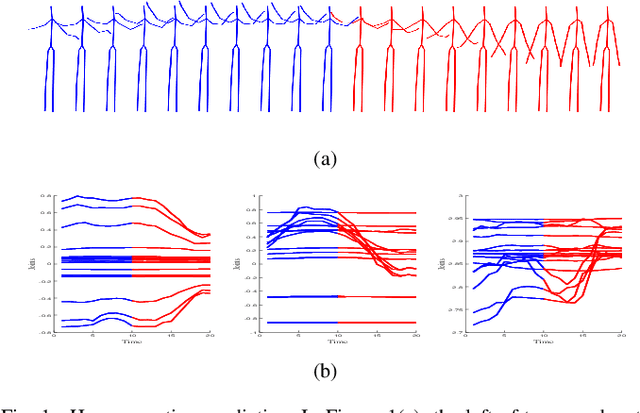
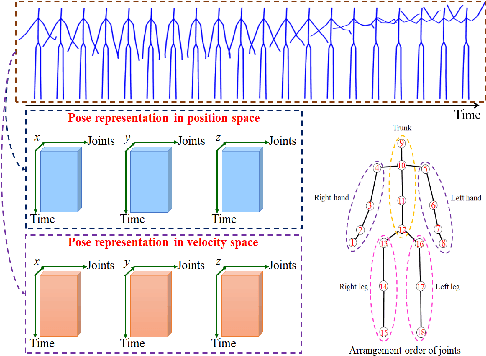
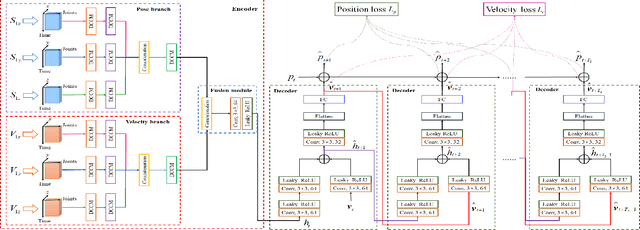
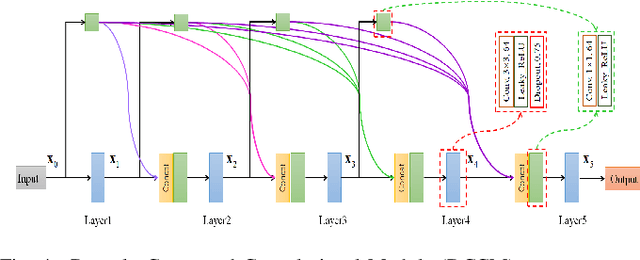
Prediction of human motion plays a significant role in human-machine interactions for a variety of real-life applications. In this paper, we propose a novel attention-guided velocity learning network, AGVNet, that utilizes multi-order information such as positions and velocities derived from the dynamic states of the human body for predicting human motion. Unlike existing methods, our network formulates the human motion system as a dynamic system and predicts human motion using the position and velocity of poses. Specifically, a multi-level Encoder is proposed to model the dynamics of moving joints at the axis level and joint level. A recursive feedforward Decoder generates future poses recursively by reusing the predictions at the previous time-steps and fusing multiple order information from both the velocity and position space. To avoid the error accumulation, a unique loss function, ATPL (Attention Temporal Prediction Loss), is designed with decreasing attention to the later predictions, making the network more accurate for predictions at the early time-steps. The experiments on two benchmark datasets (i.e., Human$3.6$M and $3$DPW) confirm that our method achieves state-of-the-art performance with improved effectiveness. The code will be made public once the paper is accepted.