 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInspecting the Process of Bank Credit Rating via Visual Analytics
Aug 06, 2021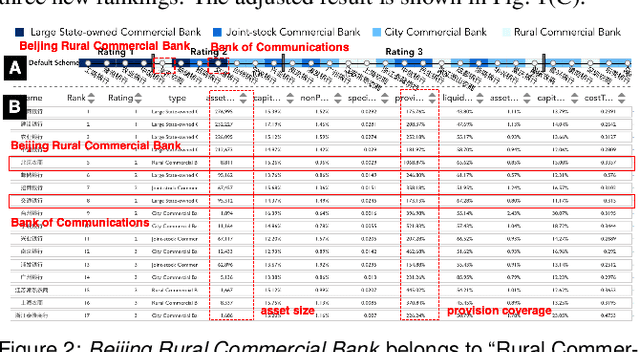
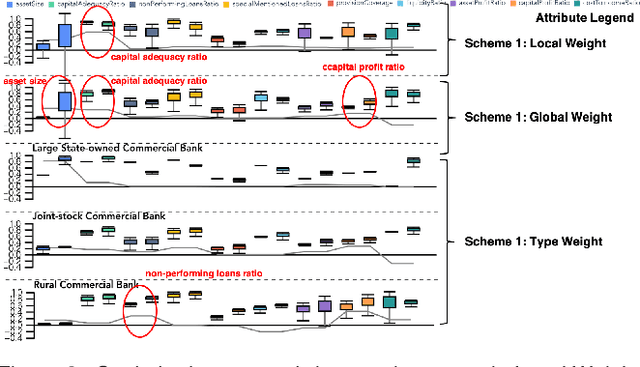
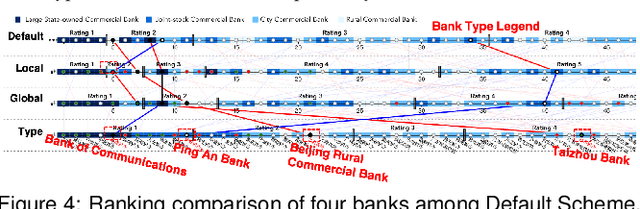
Bank credit rating classifies banks into different levels based on publicly disclosed and internal information, serving as an important input in financial risk management. However, domain experts have a vague idea of exploring and comparing different bank credit rating schemes. A loose connection between subjective and quantitative analysis and difficulties in determining appropriate indicator weights obscure understanding of bank credit ratings. Furthermore, existing models fail to consider bank types by just applying a unified indicator weight set to all banks. We propose RatingVis to assist experts in exploring and comparing different bank credit rating schemes. It supports interactively inferring indicator weights for banks by involving domain knowledge and considers bank types in the analysis loop. We conduct a case study with real-world bank data to verify the efficacy of RatingVis. Expert feedback suggests that our approach helps them better understand different rating schemes.
CASS: Towards Building a Social-Support Chatbot for Online Health Community
Feb 04, 2021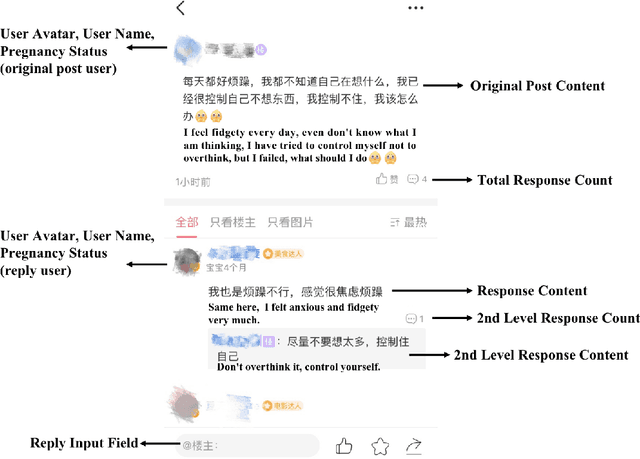
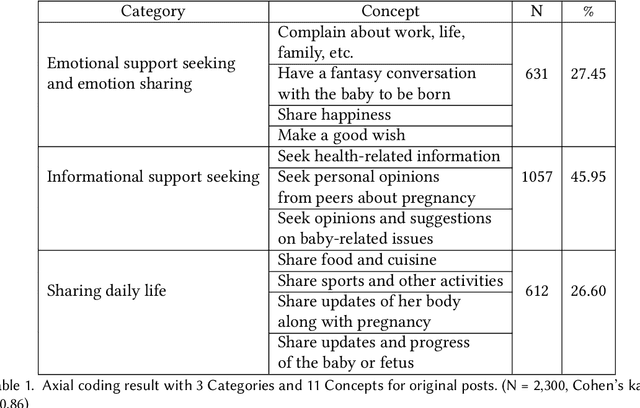
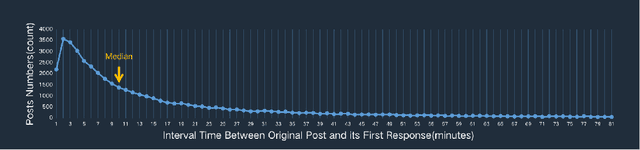
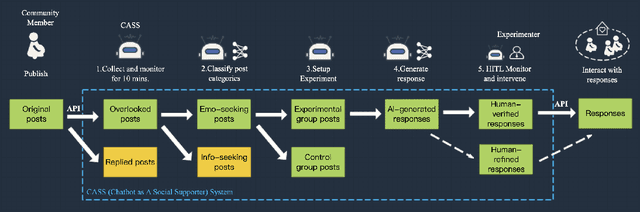
Chatbots systems, despite their popularity in today's HCI and CSCW research, fall short for one of the two reasons: 1) many of the systems use a rule-based dialog flow, thus they can only respond to a limited number of pre-defined inputs with pre-scripted responses; or 2) they are designed with a focus on single-user scenarios, thus it is unclear how these systems may affect other users or the community. In this paper, we develop a generalizable chatbot architecture (CASS) to provide social support for community members in an online health community. The CASS architecture is based on advanced neural network algorithms, thus it can handle new inputs from users and generate a variety of responses to them. CASS is also generalizable as it can be easily migrate to other online communities. With a follow-up field experiment, CASS is proven useful in supporting individual members who seek emotional support. Our work also contributes to fill the research gap on how a chatbot may influence the whole community's engagement.
Characterizing Student Engagement Moods for Dropout Prediction in Question Pool Websites
Feb 02, 2021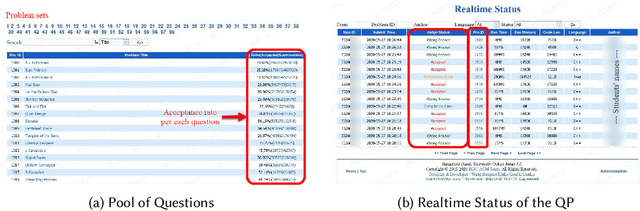
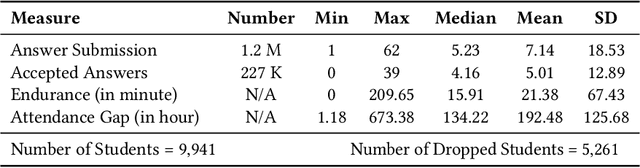
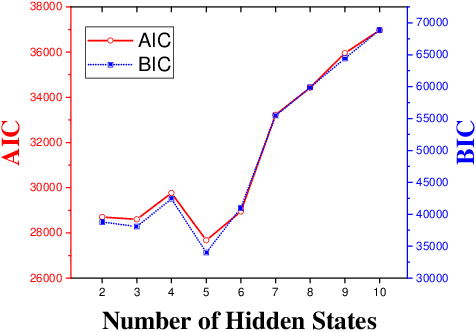
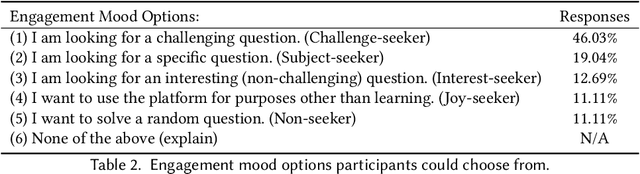
Problem-Based Learning (PBL) is a popular approach to instruction that supports students to get hands-on training by solving problems. Question Pool websites (QPs) such as LeetCode, Code Chef, and Math Playground help PBL by supplying authentic, diverse, and contextualized questions to students. Nonetheless, empirical findings suggest that 40% to 80% of students registered in QPs drop out in less than two months. This research is the first attempt to understand and predict student dropouts from QPs via exploiting students' engagement moods. Adopting a data-driven approach, we identify five different engagement moods for QP students, which are namely challenge-seeker, subject-seeker, interest-seeker, joy-seeker, and non-seeker. We find that students have collective preferences for answering questions in each engagement mood, and deviation from those preferences increases their probability of dropping out significantly. Last but not least, this paper contributes by introducing a new hybrid machine learning model (we call Dropout-Plus) for predicting student dropouts in QPs. The test results on a popular QP in China, with nearly 10K students, show that Dropout-Plus can exceed the rival algorithms' dropout prediction performance in terms of accuracy, F1-measure, and AUC. We wrap up our work by giving some design suggestions to QP managers and online learning professionals to reduce their student dropouts.
Investigating the Effects of Robot Engagement Communication on Learning from Demonstration
May 03, 2020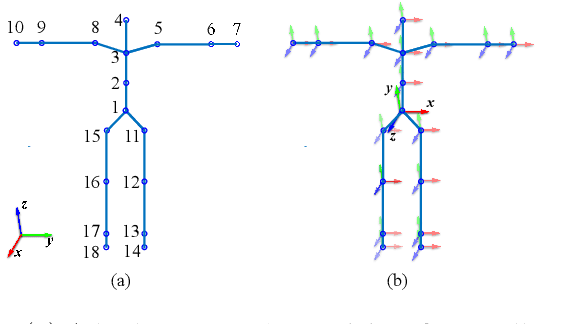
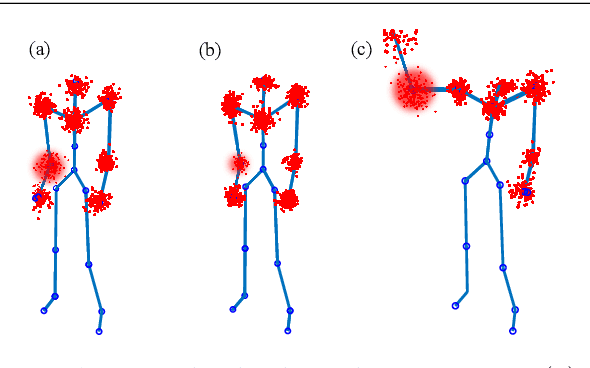

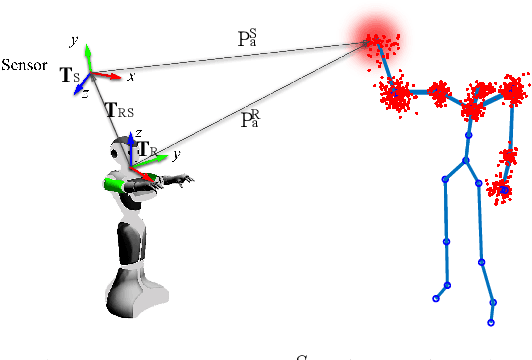
Robot Learning from Demonstration (RLfD) is a technique for robots to derive policies from instructors' examples. Although the reciprocal effects of student engagement on teacher behavior are widely recognized in the educational community, it is unclear whether the same phenomenon holds true for RLfD. To fill this gap, we first design three types of robot engagement behavior (attention, imitation, and a hybrid of the two) based on the learning literature. We then conduct, in a simulation environment, a within-subject user study to investigate the impact of different robot engagement cues on humans compared to a "without-engagement" condition. Results suggest that engagement communication significantly changes the human's estimation of the robots' capability and significantly raises their expectation towards the learning outcomes, even though we do not run actual learning algorithms in the experiments. Moreover, imitation behavior affects humans more than attention does in all metrics, while their combination has the most profound influences on humans. We also find that communicating engagement via imitation or the combined behavior significantly improve humans' perception towards the quality of demonstrations, even if all demonstrations are of the same quality.
VoiceCoach: Interactive Evidence-based Training for Voice Modulation Skills in Public Speaking
Jan 22, 2020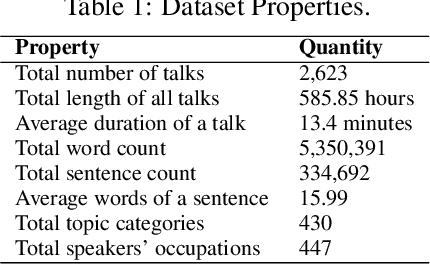
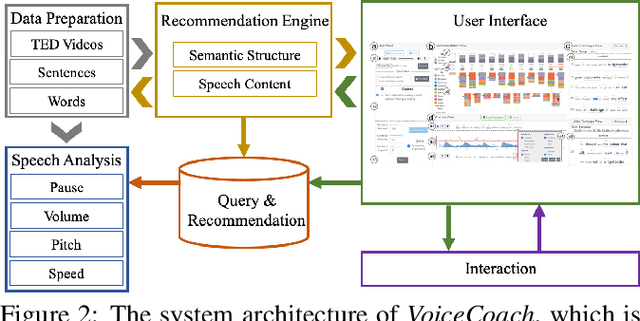

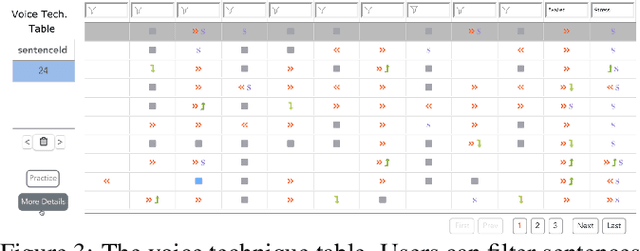
The modulation of voice properties, such as pitch, volume, and speed, is crucial for delivering a successful public speech. However, it is challenging to master different voice modulation skills. Though many guidelines are available, they are often not practical enough to be applied in different public speaking situations, especially for novice speakers. We present VoiceCoach, an interactive evidence-based approach to facilitate the effective training of voice modulation skills. Specifically, we have analyzed the voice modulation skills from 2623 high-quality speeches (i.e., TED Talks) and use them as the benchmark dataset. Given a voice input, VoiceCoach automatically recommends good voice modulation examples from the dataset based on the similarity of both sentence structures and voice modulation skills. Immediate and quantitative visual feedback is provided to guide further improvement. The expert interviews and the user study provide support for the effectiveness and usability of VoiceCoach.
Adversarial Imitation Learning from Incomplete Demonstrations
May 30, 2019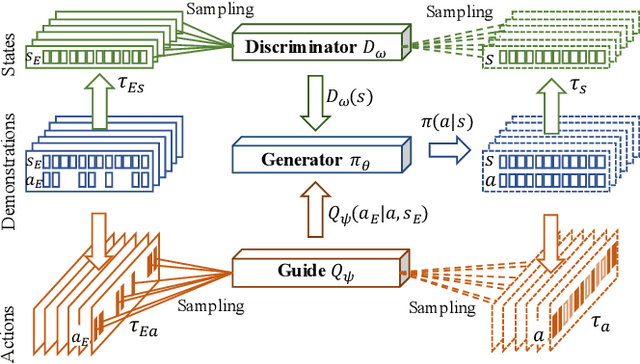

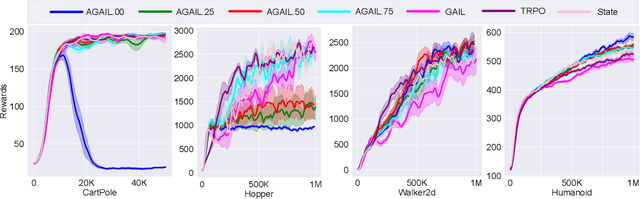
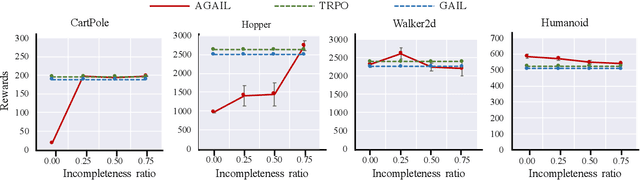
Imitation learning targets deriving a mapping from states to actions, a.k.a. policy, from expert demonstrations. Existing methods for imitation learning typically require any actions in the demonstrations to be fully available, which is hard to ensure in real applications. Though algorithms for learning with unobservable actions have been proposed, they focus solely on state information and overlook the fact that the action sequence could still be partially available and provide useful information for policy deriving. In this paper, we propose a novel algorithm called Action-Guided Adversarial Imitation Learning (AGAIL) that learns a policy from demonstrations with incomplete action sequences, i.e., incomplete demonstrations. The core idea of AGAIL is to separate demonstrations into state and action trajectories, and train a policy with state trajectories while using actions as auxiliary information to guide the training whenever applicable. Built upon the Generative Adversarial Imitation Learning, AGAIL has three components: a generator, a discriminator, and a guide. The generator learns a policy with rewards provided by the discriminator, which tries to distinguish state distributions between demonstrations and samples generated by the policy. The guide provides additional rewards to the generator when demonstrated actions for specific states are available. We compare AGAIL to other methods on benchmark tasks and show that AGAIL consistently delivers comparable performance to the state-of-the-art methods even when the action sequence in demonstrations is only partially available.
Coloring with Words: Guiding Image Colorization Through Text-based Palette Generation
Aug 07, 2018
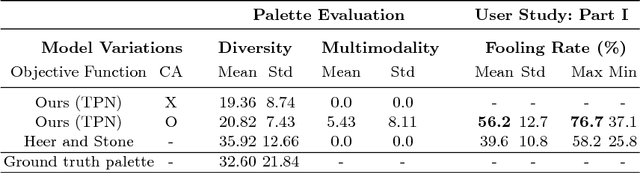


This paper proposes a novel approach to generate multiple color palettes that reflect the semantics of input text and then colorize a given grayscale image according to the generated color palette. In contrast to existing approaches, our model can understand rich text, whether it is a single word, a phrase, or a sentence, and generate multiple possible palettes from it. For this task, we introduce our manually curated dataset called Palette-and-Text (PAT). Our proposed model called Text2Colors consists of two conditional generative adversarial networks: the text-to-palette generation networks and the palette-based colorization networks. The former captures the semantics of the text input and produce relevant color palettes. The latter colorizes a grayscale image using the generated color palette. Our evaluation results show that people preferred our generated palettes over ground truth palettes and that our model can effectively reflect the given palette when colorizing an image.
* 25 pages, 22 figures
Cross-City Transfer Learning for Deep Spatio-Temporal Prediction
May 19, 2018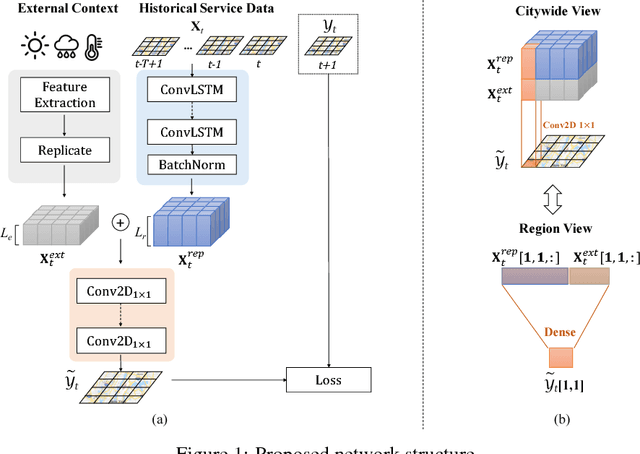
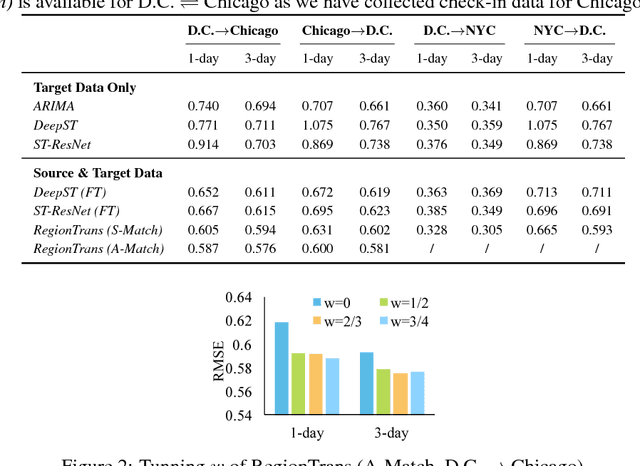
Spatio-temporal prediction is a key type of tasks in urban computing, e.g., traffic flow and air quality. Adequate data is usually a prerequisite, especially when deep learning is adopted. However, the development levels of different cities are unbalanced, and still many cities suffer from data scarcity. To address the problem, we propose a novel cross-city transfer learning method for deep spatio-temporal prediction tasks, called RegionTrans. RegionTrans aims to effectively transfer knowledge from a data-rich source city to a data-scarce target city. More specifically, we first learn an inter-city region matching function to match each target city region to a similar source city region. A neural network is designed to effectively extract region-level representation for spatio-temporal prediction. Finally, an optimization algorithm is proposed to transfer learned features from the source city to the target city with the region matching function. Using citywide crowd flow prediction as a demonstration experiment, we verify the effectiveness of RegionTrans. Results show that RegionTrans can outperform the state-of-the-art fine-tuning deep spatio-temporal prediction models by reducing up to 10.7% prediction error.
Ridesourcing Car Detection by Transfer Learning
May 23, 2017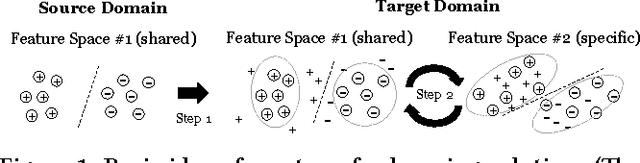
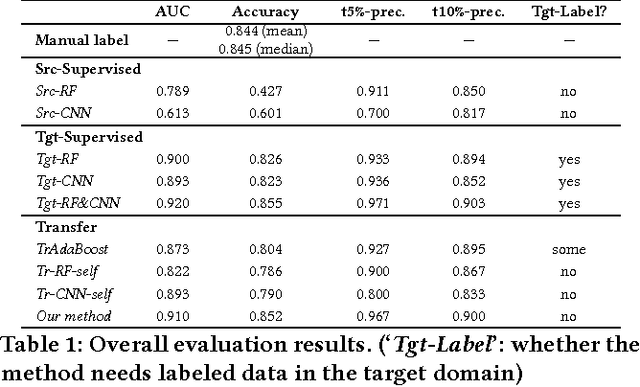
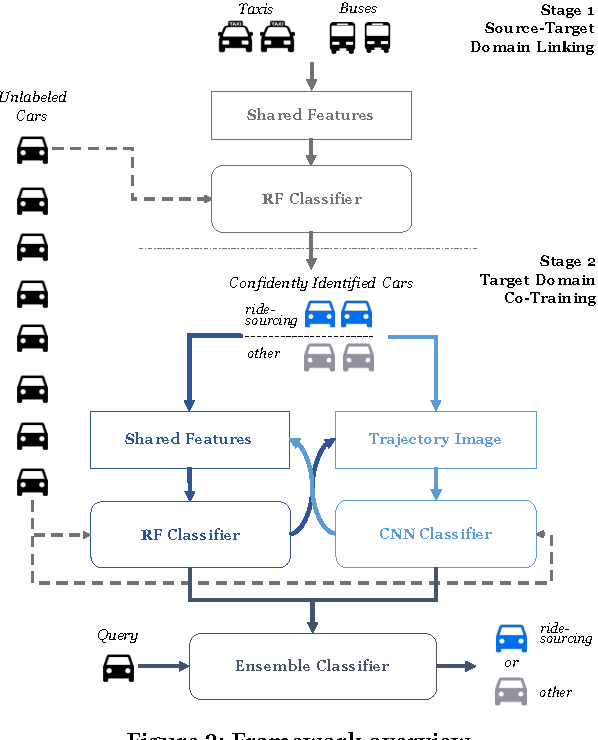
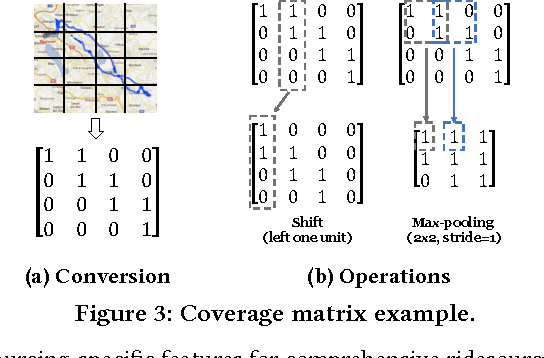
Ridesourcing platforms like Uber and Didi are getting more and more popular around the world. However, unauthorized ridesourcing activities taking advantages of the sharing economy can greatly impair the healthy development of this emerging industry. As the first step to regulate on-demand ride services and eliminate black market, we design a method to detect ridesourcing cars from a pool of cars based on their trajectories. Since licensed ridesourcing car traces are not openly available and may be completely missing in some cities due to legal issues, we turn to transferring knowledge from public transport open data, i.e, taxis and buses, to ridesourcing detection among ordinary vehicles. We propose a two-stage transfer learning framework. In Stage 1, we take taxi and bus data as input to learn a random forest (RF) classifier using trajectory features shared by taxis/buses and ridesourcing/other cars. Then, we use the RF to label all the candidate cars. In Stage 2, leveraging the subset of high confident labels from the previous stage as input, we further learn a convolutional neural network (CNN) classifier for ridesourcing detection, and iteratively refine RF and CNN, as well as the feature set, via a co-training process. Finally, we use the resulting ensemble of RF and CNN to identify the ridesourcing cars in the candidate pool. Experiments on real car, taxi and bus traces show that our transfer learning framework, with no need of a pre-labeled ridesourcing dataset, can achieve similar accuracy as the supervised learning methods.