 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuSpeech: Silent Thought, Spoken Answer via Unified Speech-Text Diffusion
Jan 30, 2026Current speech language models generate responses directly without explicit reasoning, leading to errors that cannot be corrected once audio is produced. We introduce \textbf{``Silent Thought, Spoken Answer''} -- a paradigm where speech LLMs generate internal text reasoning alongside spoken responses, with thinking traces informing speech quality. To realize this, we present \method{}, the first diffusion-based speech-text language model supporting both understanding and generation, unifying discrete text and tokenized speech under a single masked diffusion framework. Unlike autoregressive approaches, \method{} jointly generates reasoning traces and speech tokens through iterative denoising, with modality-specific masking schedules. We also construct \dataset{}, the first speech QA dataset with paired text reasoning traces, containing 26K samples totaling 319 hours. Experiments show \method{} achieves state-of-the-art speech-to-speech QA accuracy, outperforming the best baseline by up to 9 points, while attaining the best TTS quality among generative models (6.2\% WER) and preserving language understanding (66.2\% MMLU). Ablations confirm that both the diffusion architecture and thinking traces contribute to these gains.
DART: Distilling Autoregressive Reasoning to Silent Thought
Jun 13, 2025



Chain-of-Thought (CoT) reasoning has significantly advanced Large Language Models (LLMs) in solving complex tasks. However, its autoregressive paradigm leads to significant computational overhead, hindering its deployment in latency-sensitive applications. To address this, we propose \textbf{DART} (\textbf{D}istilling \textbf{A}utoregressive \textbf{R}easoning to Silent \textbf{T}hought), a self-distillation framework that enables LLMs to replace autoregressive CoT with non-autoregressive Silent Thought (ST). Specifically, DART introduces two training pathways: the CoT pathway for traditional reasoning and the ST pathway for generating answers directly from a few ST tokens. The ST pathway utilizes a lightweight Reasoning Evolvement Module (REM) to align its hidden states with the CoT pathway, enabling the ST tokens to evolve into informative embeddings. During inference, only the ST pathway is activated, leveraging evolving ST tokens to deliver the answer directly. Extensive experimental results demonstrate that DART achieves comparable reasoning performance to existing baselines while offering significant efficiency gains, serving as a feasible alternative for efficient reasoning.
FROG: Effective Friend Recommendation in Online Games via Modality-aware User Preferences
Apr 13, 2025



Due to the convenience of mobile devices, the online games have become an important part for user entertainments in reality, creating a demand for friend recommendation in online games. However, none of existing approaches can effectively incorporate the multi-modal user features (\emph{e.g.}, images and texts) with the structural information in the friendship graph, due to the following limitations: (1) some of them ignore the high-order structural proximity between users, (2) some fail to learn the pairwise relevance between users at modality-specific level, and (3) some cannot capture both the local and global user preferences on different modalities. By addressing these issues, in this paper, we propose an end-to-end model \textsc{FROG} that better models the user preferences on potential friends. Comprehensive experiments on both offline evaluation and online deployment at \kw{Tencent} have demonstrated the superiority of \textsc{FROG} over existing approaches.
Towards Better Modeling with Missing Data: A Contrastive Learning-based Visual Analytics Perspective
Sep 18, 2023



Missing data can pose a challenge for machine learning (ML) modeling. To address this, current approaches are categorized into feature imputation and label prediction and are primarily focused on handling missing data to enhance ML performance. These approaches rely on the observed data to estimate the missing values and therefore encounter three main shortcomings in imputation, including the need for different imputation methods for various missing data mechanisms, heavy dependence on the assumption of data distribution, and potential introduction of bias. This study proposes a Contrastive Learning (CL) framework to model observed data with missing values, where the ML model learns the similarity between an incomplete sample and its complete counterpart and the dissimilarity between other samples. Our proposed approach demonstrates the advantages of CL without requiring any imputation. To enhance interpretability, we introduce CIVis, a visual analytics system that incorporates interpretable techniques to visualize the learning process and diagnose the model status. Users can leverage their domain knowledge through interactive sampling to identify negative and positive pairs in CL. The output of CIVis is an optimized model that takes specified features and predicts downstream tasks. We provide two usage scenarios in regression and classification tasks and conduct quantitative experiments, expert interviews, and a qualitative user study to demonstrate the effectiveness of our approach. In short, this study offers a valuable contribution to addressing the challenges associated with ML modeling in the presence of missing data by providing a practical solution that achieves high predictive accuracy and model interpretability.
Deep Music Retrieval for Fine-Grained Videos by Exploiting Cross-Modal-Encoded Voice-Overs
Apr 21, 2021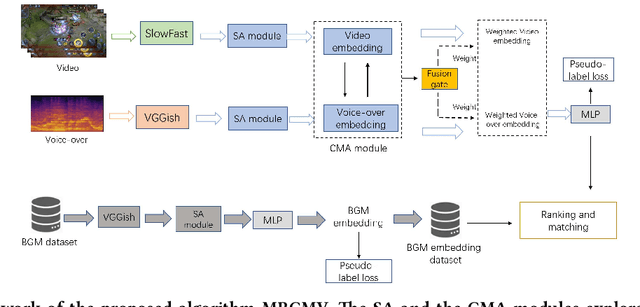
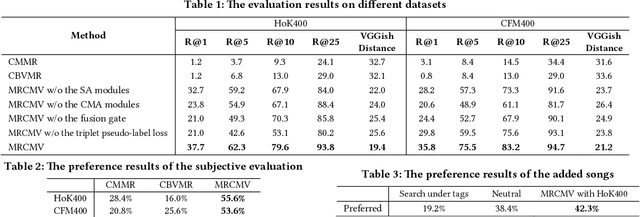
Recently, the witness of the rapidly growing popularity of short videos on different Internet platforms has intensified the need for a background music (BGM) retrieval system. However, existing video-music retrieval methods only based on the visual modality cannot show promising performance regarding videos with fine-grained virtual contents. In this paper, we also investigate the widely added voice-overs in short videos and propose a novel framework to retrieve BGM for fine-grained short videos. In our framework, we use the self-attention (SA) and the cross-modal attention (CMA) modules to explore the intra- and the inter-relationships of different modalities respectively. For balancing the modalities, we dynamically assign different weights to the modal features via a fusion gate. For paring the query and the BGM embeddings, we introduce a triplet pseudo-label loss to constrain the semantics of the modal embeddings. As there are no existing virtual-content video-BGM retrieval datasets, we build and release two virtual-content video datasets HoK400 and CFM400. Experimental results show that our method achieves superior performance and outperforms other state-of-the-art methods with large margins.
Coloring with Words: Guiding Image Colorization Through Text-based Palette Generation
Aug 07, 2018
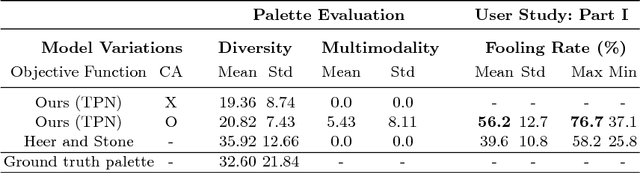


This paper proposes a novel approach to generate multiple color palettes that reflect the semantics of input text and then colorize a given grayscale image according to the generated color palette. In contrast to existing approaches, our model can understand rich text, whether it is a single word, a phrase, or a sentence, and generate multiple possible palettes from it. For this task, we introduce our manually curated dataset called Palette-and-Text (PAT). Our proposed model called Text2Colors consists of two conditional generative adversarial networks: the text-to-palette generation networks and the palette-based colorization networks. The former captures the semantics of the text input and produce relevant color palettes. The latter colorizes a grayscale image using the generated color palette. Our evaluation results show that people preferred our generated palettes over ground truth palettes and that our model can effectively reflect the given palette when colorizing an image.
* 25 pages, 22 figures