 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSirens' Whisper: Inaudible Near-Ultrasonic Jailbreaks of Speech-Driven LLMs
Mar 14, 2026Speech-driven large language models (LLMs) are increasingly accessed through speech interfaces, introducing new security risks via open acoustic channels. We present Sirens' Whisper (SWhisper), the first practical framework for covert prompt-based attacks against speech-driven LLMs under realistic black-box conditions using commodity hardware. SWhisper enables robust, inaudible delivery of arbitrary target baseband audio-including long and structured prompts-on commodity devices by encoding it into near-ultrasound waveforms that demodulate faithfully after acoustic transmission and microphone nonlinearity. This is achieved through a simple yet effective approach to modeling nonlinear channel characteristics across devices and environments, combined with lightweight channel-inversion pre-compensation. Building on this high-fidelity covert channel, we design a voice-aware jailbreak generation method that ensures intelligibility, brevity, and transferability under speech-driven interfaces. Experiments across both commercial and open-source speech-driven LLMs demonstrate strong black-box effectiveness. On commercial models, SWhisper achieves up to 0.94 non-refusal (NR) and 0.925 specific-convincing (SC). A controlled user study further shows that the injected jailbreak audio is perceptually indistinguishable from background-only playback for human listeners. Although jailbreaks serve as a case study, the underlying covert acoustic channel enables a broader class of high-fidelity prompt-injection and commandexecution attacks.
Semantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
Factored Attention and Embedding for Unstructured-view Topic-related Ultrasound Report Generation
Mar 12, 2022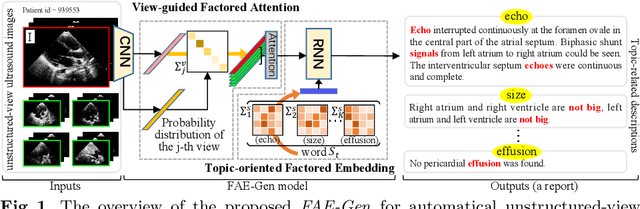
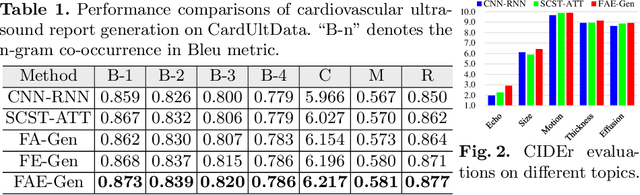

Echocardiography is widely used to clinical practice for diagnosis and treatment, e.g., on the common congenital heart defects. The traditional manual manipulation is error-prone due to the staff shortage, excess workload, and less experience, leading to the urgent requirement of an automated computer-aided reporting system to lighten the workload of ultrasonologists considerably and assist them in decision making. Despite some recent successful attempts in automatical medical report generation, they are trapped in the ultrasound report generation, which involves unstructured-view images and topic-related descriptions. To this end, we investigate the task of the unstructured-view topic-related ultrasound report generation, and propose a novel factored attention and embedding model (termed FAE-Gen). The proposed FAE-Gen mainly consists of two modules, i.e., view-guided factored attention and topic-oriented factored embedding, which 1) capture the homogeneous and heterogeneous morphological characteristic across different views, and 2) generate the descriptions with different syntactic patterns and different emphatic contents for different topics. Experimental evaluations are conducted on a to-be-released large-scale clinical cardiovascular ultrasound dataset (CardUltData). Both quantitative comparisons and qualitative analysis demonstrate the effectiveness and the superiority of FAE-Gen over seven commonly-used metrics.