 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSirens' Whisper: Inaudible Near-Ultrasonic Jailbreaks of Speech-Driven LLMs
Mar 14, 2026Speech-driven large language models (LLMs) are increasingly accessed through speech interfaces, introducing new security risks via open acoustic channels. We present Sirens' Whisper (SWhisper), the first practical framework for covert prompt-based attacks against speech-driven LLMs under realistic black-box conditions using commodity hardware. SWhisper enables robust, inaudible delivery of arbitrary target baseband audio-including long and structured prompts-on commodity devices by encoding it into near-ultrasound waveforms that demodulate faithfully after acoustic transmission and microphone nonlinearity. This is achieved through a simple yet effective approach to modeling nonlinear channel characteristics across devices and environments, combined with lightweight channel-inversion pre-compensation. Building on this high-fidelity covert channel, we design a voice-aware jailbreak generation method that ensures intelligibility, brevity, and transferability under speech-driven interfaces. Experiments across both commercial and open-source speech-driven LLMs demonstrate strong black-box effectiveness. On commercial models, SWhisper achieves up to 0.94 non-refusal (NR) and 0.925 specific-convincing (SC). A controlled user study further shows that the injected jailbreak audio is perceptually indistinguishable from background-only playback for human listeners. Although jailbreaks serve as a case study, the underlying covert acoustic channel enables a broader class of high-fidelity prompt-injection and commandexecution attacks.
SIN:Superpixel Interpolation Network
Oct 17, 2021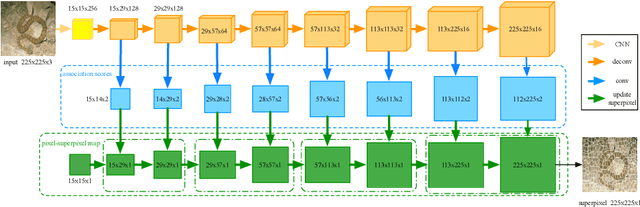

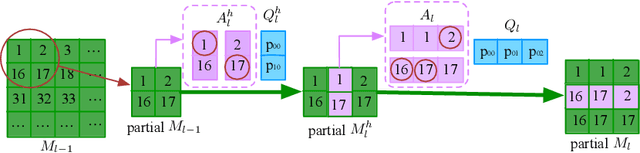

Superpixels have been widely used in computer vision tasks due to their representational and computational efficiency. Meanwhile, deep learning and end-to-end framework have made great progress in various fields including computer vision. However, existing superpixel algorithms cannot be integrated into subsequent tasks in an end-to-end way. Traditional algorithms and deep learning-based algorithms are two main streams in superpixel segmentation. The former is non-differentiable and the latter needs a non-differentiable post-processing step to enforce connectivity, which constraints the integration of superpixels and downstream tasks. In this paper, we propose a deep learning-based superpixel segmentation algorithm SIN which can be integrated with downstream tasks in an end-to-end way. Owing to some downstream tasks such as visual tracking require real-time speed, the speed of generating superpixels is also important. To remove the post-processing step, our algorithm enforces spatial connectivity from the start. Superpixels are initialized by sampled pixels and other pixels are assigned to superpixels through multiple updating steps. Each step consists of a horizontal and a vertical interpolation, which is the key to enforcing spatial connectivity. Multi-layer outputs of a fully convolutional network are utilized to predict association scores for interpolations. Experimental results show that our approach runs at about 80fps and performs favorably against state-of-the-art methods. Furthermore, we design a simple but effective loss function which reduces much training time. The improvements of superpixel-based tasks demonstrate the effectiveness of our algorithm. We hope SIN will be integrated into downstream tasks in an end-to-end way and benefit the superpixel-based community. Code is available at: \href{https://github.com/yuanqqq/SIN}{https://github.com/yuanqqq/SIN}.