 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge distillation: A good teacher is patient and consistent
Jun 09, 2021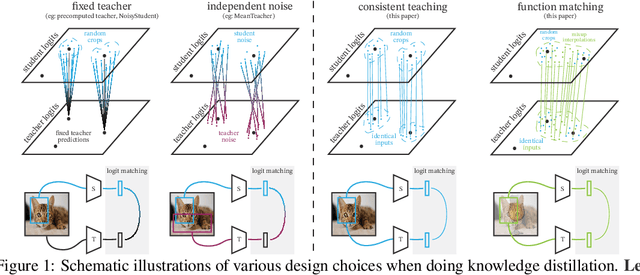
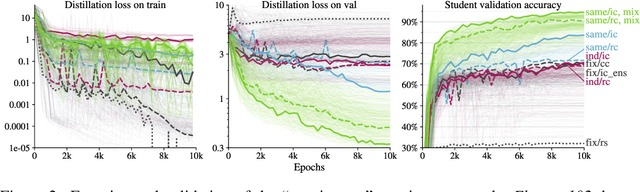

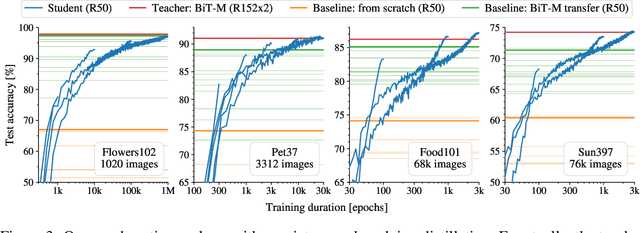
There is a growing discrepancy in computer vision between large-scale models that achieve state-of-the-art performance and models that are affordable in practical applications. In this paper we address this issue and significantly bridge the gap between these two types of models. Throughout our empirical investigation we do not aim to necessarily propose a new method, but strive to identify a robust and effective recipe for making state-of-the-art large scale models affordable in practice. We demonstrate that, when performed correctly, knowledge distillation can be a powerful tool for reducing the size of large models without compromising their performance. In particular, we uncover that there are certain implicit design choices, which may drastically affect the effectiveness of distillation. Our key contribution is the explicit identification of these design choices, which were not previously articulated in the literature. We back up our findings by a comprehensive empirical study, demonstrate compelling results on a wide range of vision datasets and, in particular, obtain a state-of-the-art ResNet-50 model for ImageNet, which achieves 82.8\% top-1 accuracy.
Scaling Vision Transformers
Jun 08, 2021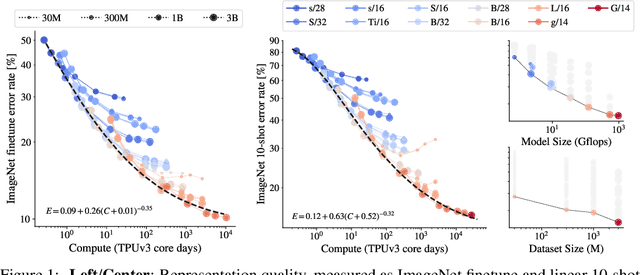
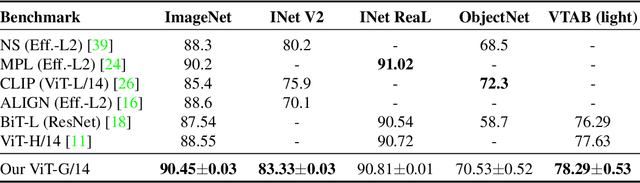
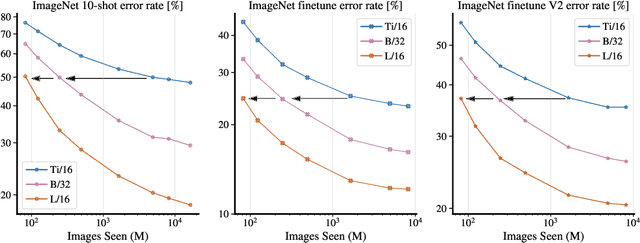
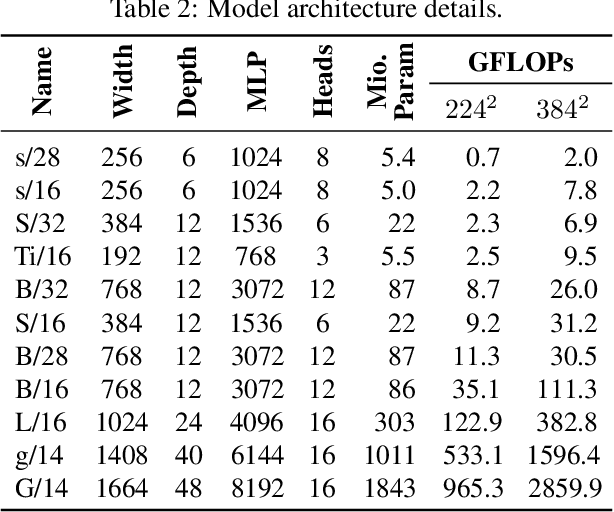
Attention-based neural networks such as the Vision Transformer (ViT) have recently attained state-of-the-art results on many computer vision benchmarks. Scale is a primary ingredient in attaining excellent results, therefore, understanding a model's scaling properties is a key to designing future generations effectively. While the laws for scaling Transformer language models have been studied, it is unknown how Vision Transformers scale. To address this, we scale ViT models and data, both up and down, and characterize the relationships between error rate, data, and compute. Along the way, we refine the architecture and training of ViT, reducing memory consumption and increasing accuracy the resulting models. As a result, we successfully train a ViT model with two billion parameters, which attains a new state-of-the-art on ImageNet of 90.45% top-1 accuracy. The model also performs well on few-shot learning, for example, attaining 84.86% top-1 accuracy on ImageNet with only 10 examples per class.
MLP-Mixer: An all-MLP Architecture for Vision
May 17, 2021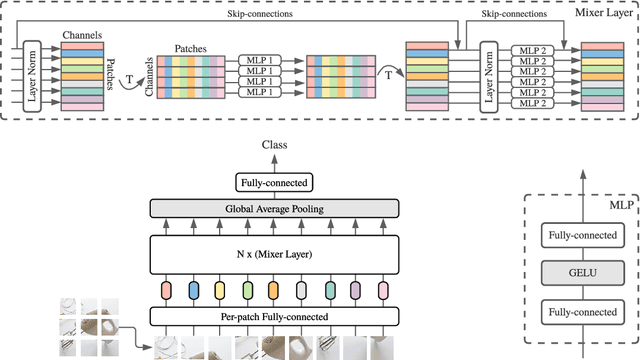
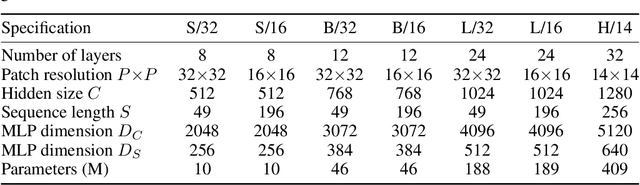
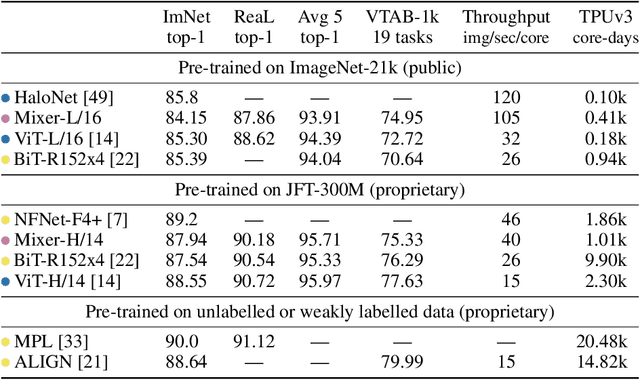
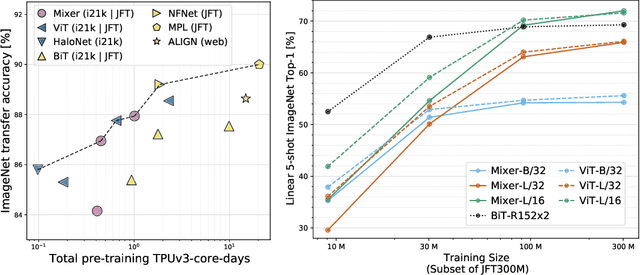
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. "mixing" the per-location features), and one with MLPs applied across patches (i.e. "mixing" spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.
SI-Score: An image dataset for fine-grained analysis of robustness to object location, rotation and size
Apr 09, 2021

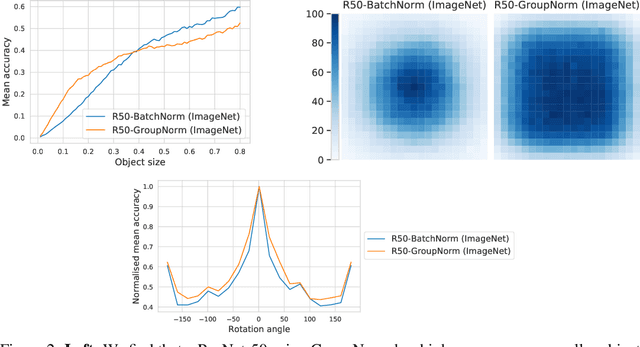

Before deploying machine learning models it is critical to assess their robustness. In the context of deep neural networks for image understanding, changing the object location, rotation and size may affect the predictions in non-trivial ways. In this work we perform a fine-grained analysis of robustness with respect to these factors of variation using SI-Score, a synthetic dataset. In particular, we investigate ResNets, Vision Transformers and CLIP, and identify interesting qualitative differences between these.
Comparing Transfer and Meta Learning Approaches on a Unified Few-Shot Classification Benchmark
Apr 06, 2021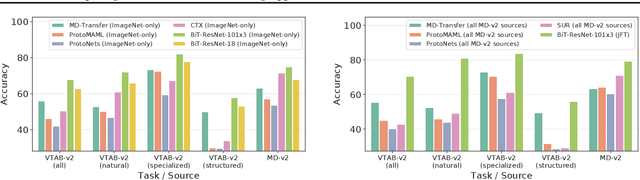
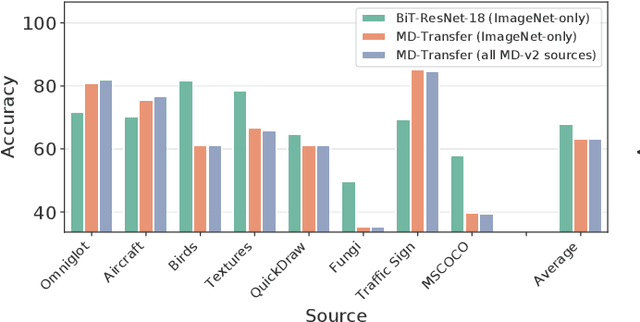

Meta and transfer learning are two successful families of approaches to few-shot learning. Despite highly related goals, state-of-the-art advances in each family are measured largely in isolation of each other. As a result of diverging evaluation norms, a direct or thorough comparison of different approaches is challenging. To bridge this gap, we perform a cross-family study of the best transfer and meta learners on both a large-scale meta-learning benchmark (Meta-Dataset, MD), and a transfer learning benchmark (Visual Task Adaptation Benchmark, VTAB). We find that, on average, large-scale transfer methods (Big Transfer, BiT) outperform competing approaches on MD, even when trained only on ImageNet. In contrast, meta-learning approaches struggle to compete on VTAB when trained and validated on MD. However, BiT is not without limitations, and pushing for scale does not improve performance on highly out-of-distribution MD tasks. In performing this study, we reveal a number of discrepancies in evaluation norms and study some of these in light of the performance gap. We hope that this work facilitates sharing of insights from each community, and accelerates progress on few-shot learning.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Oct 22, 2020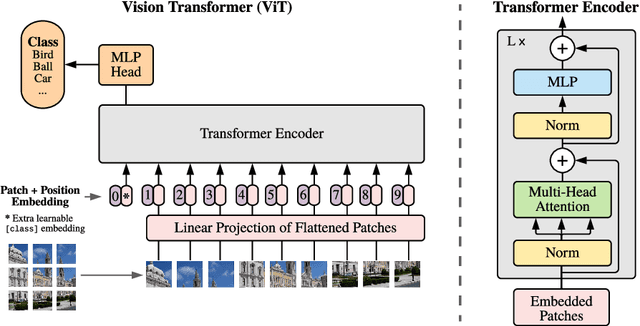

While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
Training general representations for remote sensing using in-domain knowledge
Sep 30, 2020
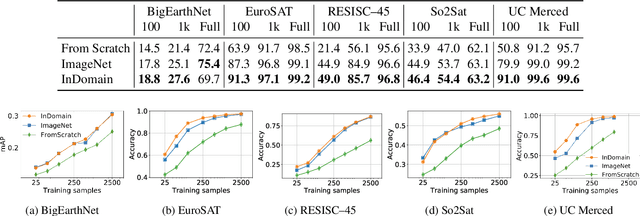
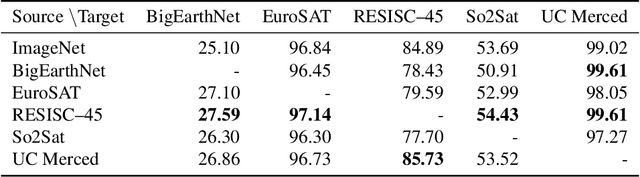
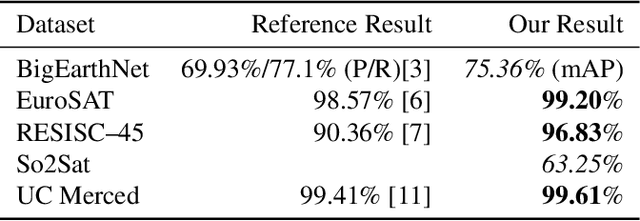
Automatically finding good and general remote sensing representations allows to perform transfer learning on a wide range of applications - improving the accuracy and reducing the required number of training samples. This paper investigates development of generic remote sensing representations, and explores which characteristics are important for a dataset to be a good source for representation learning. For this analysis, five diverse remote sensing datasets are selected and used for both, disjoint upstream representation learning and downstream model training and evaluation. A common evaluation protocol is used to establish baselines for these datasets that achieve state-of-the-art performance. As the results indicate, especially with a low number of available training samples a significant performance enhancement can be observed when including additionally in-domain data in comparison to training models from scratch or fine-tuning only on ImageNet (up to 11% and 40%, respectively, at 100 training samples). All datasets and pretrained representation models are published online.
On Robustness and Transferability of Convolutional Neural Networks
Jul 16, 2020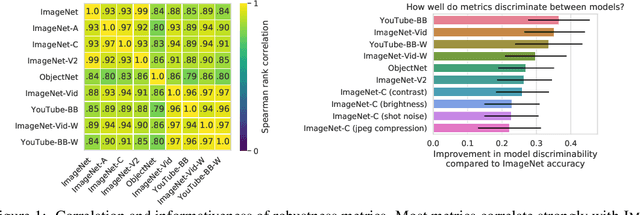

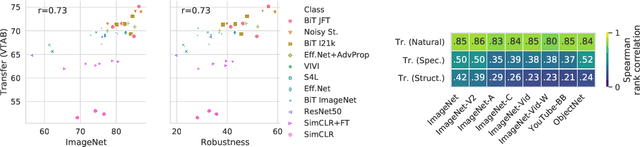
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we revisit the out-of-distribution and transfer performance of modern image classification CNNs and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset we use for a systematic analysis across common factors of variation. \end{abstract}
Are we done with ImageNet?
Jun 12, 2020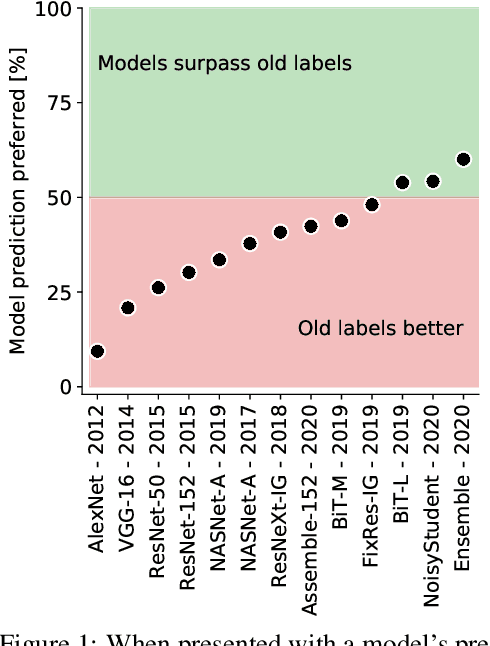
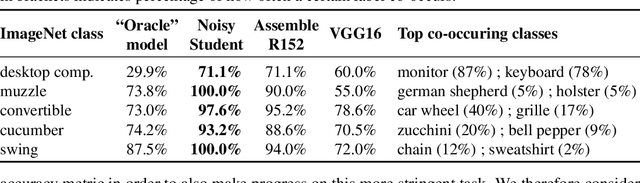
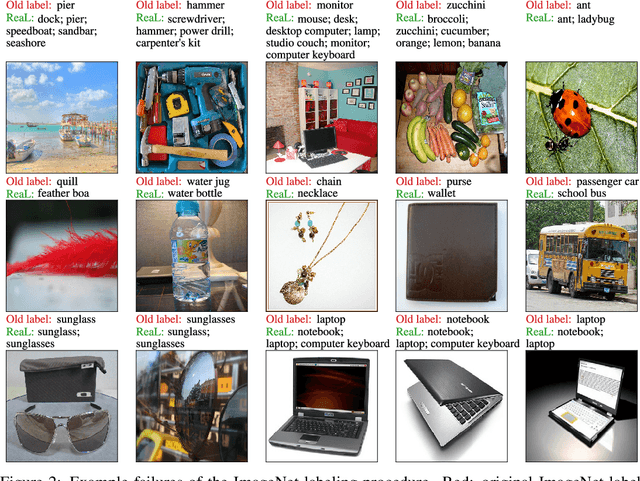
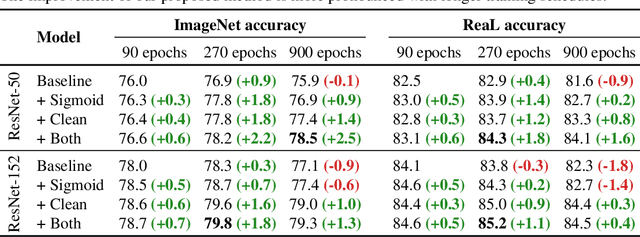
Yes, and no. We ask whether recent progress on the ImageNet classification benchmark continues to represent meaningful generalization, or whether the community has started to overfit to the idiosyncrasies of its labeling procedure. We therefore develop a significantly more robust procedure for collecting human annotations of the ImageNet validation set. Using these new labels, we reassess the accuracy of recently proposed ImageNet classifiers, and find their gains to be substantially smaller than those reported on the original labels. Furthermore, we find the original ImageNet labels to no longer be the best predictors of this independently-collected set, indicating that their usefulness in evaluating vision models may be nearing an end. Nevertheless, we find our annotation procedure to have largely remedied the errors in the original labels, reinforcing ImageNet as a powerful benchmark for future research in visual recognition.