 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Distributed Training of Deep Neural Networks: Dynamic Communication Thresholding for Model and Data Parallelism
Oct 18, 2020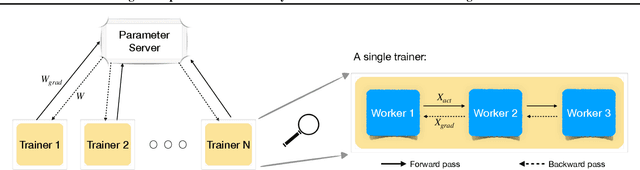
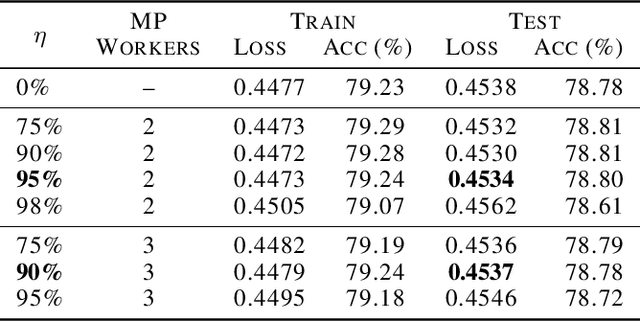
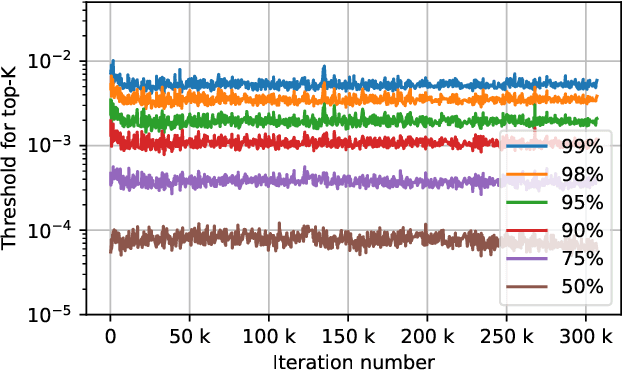
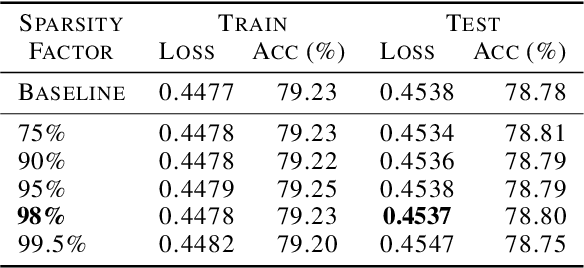
Data Parallelism (DP) and Model Parallelism (MP) are two common paradigms to enable large-scale distributed training of neural networks. Recent trends, such as the improved model performance of deeper and wider neural networks when trained with billions of data points, have prompted the use of hybrid parallelism---a paradigm that employs both DP and MP to scale further parallelization for machine learning. Hybrid training allows compute power to increase, but it runs up against the key bottleneck of communication overhead that hinders scalability. In this paper, we propose a compression framework called Dynamic Communication Thresholding (DCT) for communication-efficient hybrid training. DCT filters the entities to be communicated across the network through a simple hard-thresholding function, allowing only the most relevant information to pass through. For communication efficient DP, DCT compresses the parameter gradients sent to the parameter server during model synchronization, while compensating for the introduced errors with known techniques. For communication efficient MP, DCT incorporates a novel technique to compress the activations and gradients sent across the network during the forward and backward propagation, respectively. This is done by identifying and updating only the most relevant neurons of the neural network for each training sample in the data. Under modest assumptions, we show that the convergence of training is maintained with DCT. We evaluate DCT on natural language processing and recommender system models. DCT reduces overall communication by 20x, improving end-to-end training time on industry scale models by 37%. Moreover, we observe an improvement in the trained model performance, as the induced sparsity is possibly acting as an implicit sparsity based regularization.
Single-Timescale Stochastic Nonconvex-Concave Optimization for Smooth Nonlinear TD Learning
Aug 23, 2020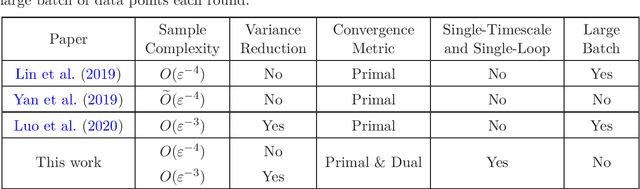
Temporal-Difference (TD) learning with nonlinear smooth function approximation for policy evaluation has achieved great success in modern reinforcement learning. It is shown that such a problem can be reformulated as a stochastic nonconvex-strongly-concave optimization problem, which is challenging as naive stochastic gradient descent-ascent algorithm suffers from slow convergence. Existing approaches for this problem are based on two-timescale or double-loop stochastic gradient algorithms, which may also require sampling large-batch data. However, in practice, a single-timescale single-loop stochastic algorithm is preferred due to its simplicity and also because its step-size is easier to tune. In this paper, we propose two single-timescale single-loop algorithms which require only one data point each step. Our first algorithm implements momentum updates on both primal and dual variables achieving an $O(\varepsilon^{-4})$ sample complexity, which shows the important role of momentum in obtaining a single-timescale algorithm. Our second algorithm improves upon the first one by applying variance reduction on top of momentum, which matches the best known $O(\varepsilon^{-3})$ sample complexity in existing works. Furthermore, our variance-reduction algorithm does not require a large-batch checkpoint. Moreover, our theoretical results for both algorithms are expressed in a tighter form of simultaneous primal and dual side convergence.
Beyond $\mathcal{O}(\sqrt{T})$ Regret for Constrained Online Optimization: Gradual Variations and Mirror Prox
Jun 22, 2020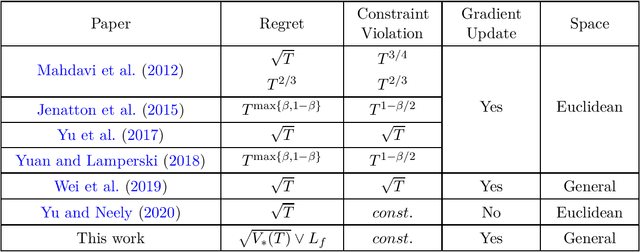
We study constrained online convex optimization, where the constraints consist of a relatively simple constraint set (e.g. a Euclidean ball) and multiple functional constraints. Projections onto such decision sets are usually computationally challenging. So instead of enforcing all constraints over each slot, we allow decisions to violate these functional constraints but aim at achieving a low regret and a low cumulative constraint violation over a horizon of $T$ time slot. The best known bound for solving this problem is $\mathcal{O}(\sqrt{T})$ regret and $\mathcal{O}(1)$ constraint violation, whose algorithms and analysis are restricted to Euclidean spaces. In this paper, we propose a new online primal-dual mirror prox algorithm whose regret is measured via a total gradient variation $V_*(T)$ over a sequence of $T$ loss functions. Specifically, we show that the proposed algorithm can achieve an $\mathcal{O}(\sqrt{V_*(T)})$ regret and $\mathcal{O}(1)$ constraint violation simultaneously. Such a bound holds in general non-Euclidean spaces, is never worse than the previously known $\big( \mathcal{O}(\sqrt{T}), \mathcal{O}(1) \big)$ result, and can be much better on regret when the variation is small. Furthermore, our algorithm is computationally efficient in that only two mirror descent steps are required during each slot instead of solving a general Lagrangian minimization problem. Along the way, our bounds also improve upon those of previous attempts using mirror-prox-type algorithms solving this problem, which yield a relatively worse $\mathcal{O}(T^{2/3})$ regret and $\mathcal{O}(T^{2/3})$ constraint violation.
Upper Confidence Primal-Dual Optimization: Stochastically Constrained Markov Decision Processes with Adversarial Losses and Unknown Transitions
Mar 02, 2020We consider online learning for episodic Markov decision processes (MDPs) with stochastic long-term budget constraints, which plays a central role in ensuring the safety of reinforcement learning. Here the loss function can vary arbitrarily across the episodes, whereas both the loss received and the budget consumption are revealed at the end of each episode. Previous works solve this problem under the restrictive assumption that the transition model of the MDP is known a priori and establish regret bounds that depend polynomially on the cardinalities of the state space $\mathcal{S}$ and the action space $\mathcal{A}$. In this work, we propose a new \emph{upper confidence primal-dual} algorithm, which only requires the trajectories sampled from the transition model. In particular, we prove that the proposed algorithm achieves $\tilde{\mathcal{O}}(L|\mathcal{S}|\sqrt{|\mathcal{A}|T})$ upper bounds of both the regret and the constraint violation, where $L$ is the length of each episode. Our analysis incorporates a new high-probability drift analysis of Lagrange multiplier processes into the celebrated regret analysis of upper confidence reinforcement learning, which demonstrates the power of "optimism in the face of uncertainty" in constrained online learning.
Provably Efficient Safe Exploration via Primal-Dual Policy Optimization
Mar 01, 2020We study the Safe Reinforcement Learning (SRL) problem using the Constrained Markov Decision Process (CMDP) formulation in which an agent aims to maximize the expected total reward subject to a safety constraint on the expected total value of a criterion function (e.g., utility). We focus on an episodic setting with the function approximation where the reward and criterion functions and the Markov transition kernels all have a linear structure but do not impose any additional assumptions on the sampling model. Designing SRL algorithms with provable computational and statistical efficiency is particularly challenging under this setting because of the need to incorporate both the safety constraint and the function approximation into the fundamental exploitation/exploration tradeoff. To this end, we present an {O}ptimistic {P}rimal-{D}ual Proximal Policy {OP}timization (OPDOP) algorithm where the value function is estimated by combining the least-squares policy evaluation and an additional bonus term for safe exploration. We prove that the proposed algorithm achieves an O(d^{1.5}H^{3.5}\sqrt{T}) regret and an O(d^{1.5}H^{3.5}\sqrt{T}) constraint violation, where d is the dimension of the feature mapping, H is the horizon of each episode, and T is the total number of steps. We establish these bounds under the following two settings: (i) Both the reward and criterion functions can change adversarially but are revealed entirely after each episode. (ii) The reward/criterion functions are fixed but the feedback after each episode is bandit. Our bounds depend on the capacity of the state space only through the dimension of the feature mapping and thus our results hold even when the number of states goes to infinity. To the best of our knowledge, we provide the first provably efficient policy optimization algorithm for CMDPs with safe exploration.
Fast Multi-Agent Temporal-Difference Learning via Homotopy Stochastic Primal-Dual Optimization
Aug 24, 2019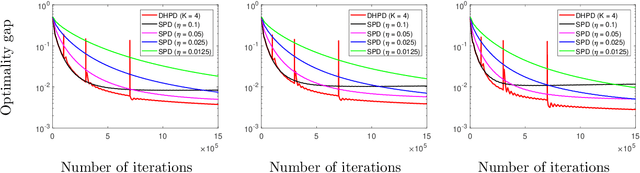
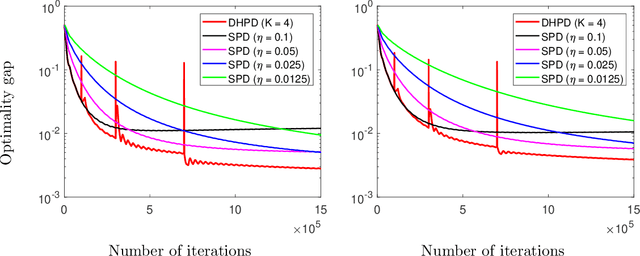
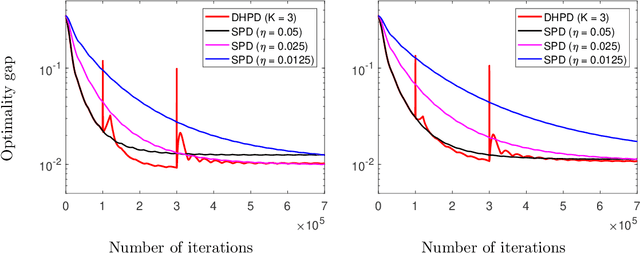
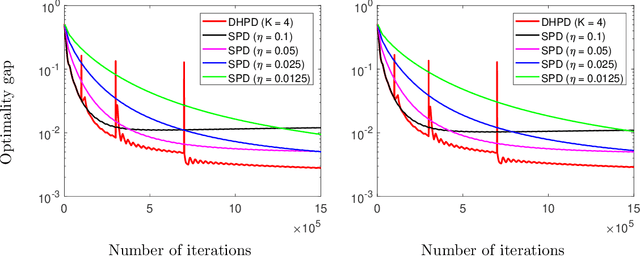
We consider a distributed multi-agent policy evaluation problem in reinforcement learning. In our setup, a group of agents with jointly observed states and private local actions and rewards collaborates to learn the value function of a given policy. When the dimension of state-action space is large, the temporal-difference learning with linear function approximation is widely used. Under the assumption that the samples are i.i.d., the best-known convergence rate for multi-agent temporal-difference learning is $O(1/\sqrt{T})$ minimizing the mean square projected Bellman error. In this paper, we formulate the temporal-difference learning as a distributed stochastic saddle point problem, and propose a new homotopy primal-dual algorithm by adaptively restarting the gradient update from the average of previous iterations. We prove that our algorithm enjoys an $O(1/T)$ convergence rate up to logarithmic factors of $T$, thereby significantly improving the previously-known convergence results on multi-agent temporal-difference learning. Furthermore, since our result explicitly takes into account the Markovian nature of the sampling in policy evaluation, it addresses a broader class of problems than the commonly used i.i.d. sampling scenario. From a stochastic optimization perspective, to the best of our knowledge, the proposed homotopy primal-dual algorithm is the first to achieve $O(1/T)$ convergence rate for distributed stochastic saddle point problem.
Robust One-Bit Recovery via ReLU Generative Networks: Improved Statistical Rates and Global Landscape Analysis
Aug 14, 2019
We study the robust one-bit compressed sensing problem whose goal is to design an algorithm that faithfully recovers any sparse target vector $\theta_0\in\mathbb{R}^d$ uniformly $m$ quantized noisy measurements. Under the assumption that the measurements are sub-Gaussian random vectors, to recover any $k$-sparse $\theta_0$ ($k\ll d$) uniformly up to an error $\varepsilon$ with high probability, the best known computationally tractable algorithm requires $m\geq\tilde{\mathcal{O}}(k\log d/\varepsilon^4)$ measurements. In this paper, we consider a new framework for the one-bit sensing problem where the sparsity is implicitly enforced via mapping a low dimensional representation $x_0 \in \mathbb{R}^k$ through a known $n$-layer ReLU generative network $G:\mathbb{R}^k\rightarrow\mathbb{R}^d$. Such a framework poses low-dimensional priors on $\theta_0$ without a known basis. We propose to recover the target $G(x_0)$ via an unconstrained empirical risk minimization (ERM) problem under a much weaker sub-exponential measurement assumption. For such a problem, we establish a joint statistical and computational analysis. In particular, we prove that the ERM estimator in this new framework achieves an improved statistical rate of $m=\tilde{\mathcal{O}}(kn \log d /\varepsilon^2)$ recovering any $G(x_0)$ uniformly up to an error $\varepsilon$. Moreover, from the lens of computation, despite non-convexity, we prove that the objective of our ERM problem has no spurious stationary point, that is, any stationary point are equally good for recovering the true target up to scaling with a certain accuracy. Furthermore, our analysis also shed lights on the possibility of inverting a deep generative model under partial and quantized measurements, complementing the recent success of using deep generative models for inverse problems.
Online Convex Optimization with Stochastic Constraints
Aug 12, 2017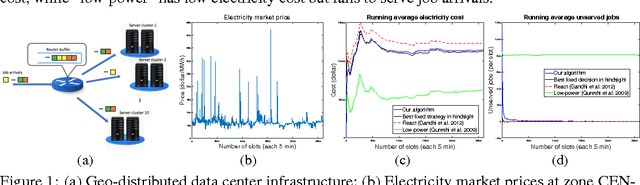
This paper considers online convex optimization (OCO) with stochastic constraints, which generalizes Zinkevich's OCO over a known simple fixed set by introducing multiple stochastic functional constraints that are i.i.d. generated at each round and are disclosed to the decision maker only after the decision is made. This formulation arises naturally when decisions are restricted by stochastic environments or deterministic environments with noisy observations. It also includes many important problems as special cases, such as OCO with long term constraints, stochastic constrained convex optimization, and deterministic constrained convex optimization. To solve this problem, this paper proposes a new algorithm that achieves $O(\sqrt{T})$ expected regret and constraint violations and $O(\sqrt{T}\log(T))$ high probability regret and constraint violations. Experiments on a real-world data center scheduling problem further verify the performance of the new algorithm.