 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised End-To-End Contrastive Learning For Time Series Classification
Oct 13, 2023Time series classification is a critical task in various domains, such as finance, healthcare, and sensor data analysis. Unsupervised contrastive learning has garnered significant interest in learning effective representations from time series data with limited labels. The prevalent approach in existing contrastive learning methods consists of two separate stages: pre-training the encoder on unlabeled datasets and fine-tuning the well-trained model on a small-scale labeled dataset. However, such two-stage approaches suffer from several shortcomings, such as the inability of unsupervised pre-training contrastive loss to directly affect downstream fine-tuning classifiers, and the lack of exploiting the classification loss which is guided by valuable ground truth. In this paper, we propose an end-to-end model called SLOTS (Semi-supervised Learning fOr Time clasSification). SLOTS receives semi-labeled datasets, comprising a large number of unlabeled samples and a small proportion of labeled samples, and maps them to an embedding space through an encoder. We calculate not only the unsupervised contrastive loss but also measure the supervised contrastive loss on the samples with ground truth. The learned embeddings are fed into a classifier, and the classification loss is calculated using the available true labels. The unsupervised, supervised contrastive losses and classification loss are jointly used to optimize the encoder and classifier. We evaluate SLOTS by comparing it with ten state-of-the-art methods across five datasets. The results demonstrate that SLOTS is a simple yet effective framework. When compared to the two-stage framework, our end-to-end SLOTS utilizes the same input data, consumes a similar computational cost, but delivers significantly improved performance. We release code and datasets at https://anonymous.4open.science/r/SLOTS-242E.
Speech Audio Synthesis from Tagged MRI and Non-Negative Matrix Factorization via Plastic Transformer
Sep 26, 2023



The tongue's intricate 3D structure, comprising localized functional units, plays a crucial role in the production of speech. When measured using tagged MRI, these functional units exhibit cohesive displacements and derived quantities that facilitate the complex process of speech production. Non-negative matrix factorization-based approaches have been shown to estimate the functional units through motion features, yielding a set of building blocks and a corresponding weighting map. Investigating the link between weighting maps and speech acoustics can offer significant insights into the intricate process of speech production. To this end, in this work, we utilize two-dimensional spectrograms as a proxy representation, and develop an end-to-end deep learning framework for translating weighting maps to their corresponding audio waveforms. Our proposed plastic light transformer (PLT) framework is based on directional product relative position bias and single-level spatial pyramid pooling, thus enabling flexible processing of weighting maps with variable size to fixed-size spectrograms, without input information loss or dimension expansion. Additionally, our PLT framework efficiently models the global correlation of wide matrix input. To improve the realism of our generated spectrograms with relatively limited training samples, we apply pair-wise utterance consistency with Maximum Mean Discrepancy constraint and adversarial training. Experimental results on a dataset of 29 subjects speaking two utterances demonstrated that our framework is able to synthesize speech audio waveforms from weighting maps, outperforming conventional convolution and transformer models.
Bias and Fairness in Chatbots: An Overview
Sep 16, 2023



Chatbots have been studied for more than half a century. With the rapid development of natural language processing (NLP) technologies in recent years, chatbots using large language models (LLMs) have received much attention nowadays. Compared with traditional ones, modern chatbots are more powerful and have been used in real-world applications. There are however, bias and fairness concerns in modern chatbot design. Due to the huge amounts of training data, extremely large model sizes, and lack of interpretability, bias mitigation and fairness preservation of modern chatbots are challenging. Thus, a comprehensive overview on bias and fairness in chatbot systems is given in this paper. The history of chatbots and their categories are first reviewed. Then, bias sources and potential harms in applications are analyzed. Considerations in designing fair and unbiased chatbot systems are examined. Finally, future research directions are discussed.
MRecGen: Multimodal Appropriate Reaction Generator
Jul 05, 2023Verbal and non-verbal human reaction generation is a challenging task, as different reactions could be appropriate for responding to the same behaviour. This paper proposes the first multiple and multimodal (verbal and nonverbal) appropriate human reaction generation framework that can generate appropriate and realistic human-style reactions (displayed in the form of synchronised text, audio and video streams) in response to an input user behaviour. This novel technique can be applied to various human-computer interaction scenarios by generating appropriate virtual agent/robot behaviours. Our demo is available at \url{https://github.com/SSYSteve/MRecGen}.
Incremental Learning for Heterogeneous Structure Segmentation in Brain Tumor MRI
May 30, 2023



Deep learning (DL) models for segmenting various anatomical structures have achieved great success via a static DL model that is trained in a single source domain. Yet, the static DL model is likely to perform poorly in a continually evolving environment, requiring appropriate model updates. In an incremental learning setting, we would expect that well-trained static models are updated, following continually evolving target domain data -- e.g., additional lesions or structures of interest -- collected from different sites, without catastrophic forgetting. This, however, poses challenges, due to distribution shifts, additional structures not seen during the initial model training, and the absence of training data in a source domain. To address these challenges, in this work, we seek to progressively evolve an ``off-the-shelf" trained segmentation model to diverse datasets with additional anatomical categories in a unified manner. Specifically, we first propose a divergence-aware dual-flow module with balanced rigidity and plasticity branches to decouple old and new tasks, which is guided by continuous batch renormalization. Then, a complementary pseudo-label training scheme with self-entropy regularized momentum MixUp decay is developed for adaptive network optimization. We evaluated our framework on a brain tumor segmentation task with continually changing target domains -- i.e., new MRI scanners/modalities with incremental structures. Our framework was able to well retain the discriminability of previously learned structures, hence enabling the realistic life-long segmentation model extension along with the widespread accumulation of big medical data.
Attentive Continuous Generative Self-training for Unsupervised Domain Adaptive Medical Image Translation
May 23, 2023



Self-training is an important class of unsupervised domain adaptation (UDA) approaches that are used to mitigate the problem of domain shift, when applying knowledge learned from a labeled source domain to unlabeled and heterogeneous target domains. While self-training-based UDA has shown considerable promise on discriminative tasks, including classification and segmentation, through reliable pseudo-label filtering based on the maximum softmax probability, there is a paucity of prior work on self-training-based UDA for generative tasks, including image modality translation. To fill this gap, in this work, we seek to develop a generative self-training (GST) framework for domain adaptive image translation with continuous value prediction and regression objectives. Specifically, we quantify both aleatoric and epistemic uncertainties within our GST using variational Bayes learning to measure the reliability of synthesized data. We also introduce a self-attention scheme that de-emphasizes the background region to prevent it from dominating the training process. The adaptation is then carried out by an alternating optimization scheme with target domain supervision that focuses attention on the regions with reliable pseudo-labels. We evaluated our framework on two cross-scanner/center, inter-subject translation tasks, including tagged-to-cine magnetic resonance (MR) image translation and T1-weighted MR-to-fractional anisotropy translation. Extensive validations with unpaired target domain data showed that our GST yielded superior synthesis performance in comparison to adversarial training UDA methods.
NFI$_2$: Learning Noise-Free Illuminance-Interpolator for Unsupervised Low-Light Image Enhancement
May 17, 2023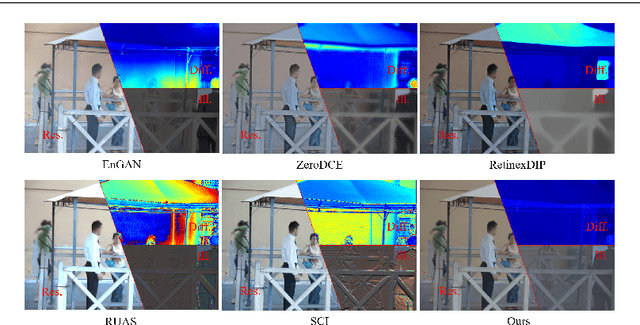
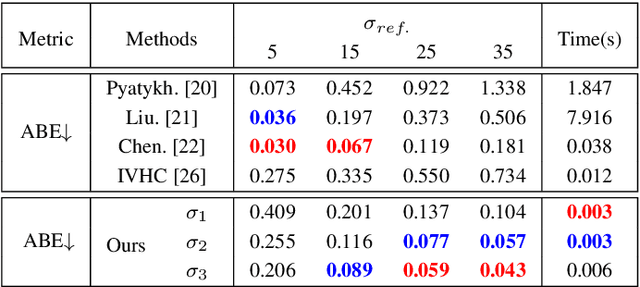
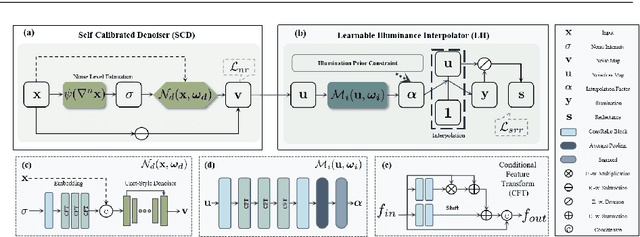
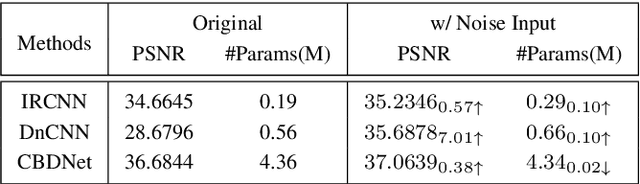
Low-light situations severely restrict the pursuit of aesthetic quality in consumer photography. Although many efforts are devoted to designing heuristics, it is generally mired in a shallow spiral of tedium, such as piling up complex network architectures and empirical strategies. How to delve into the essential physical principles of illumination compensation has been neglected. Following the way of simplifying the complexity, this paper innovatively proposes a simple and efficient Noise-Free Illumination Interpolator (NFI$_2$). According to the constraint principle of illuminance and reflectance within a limited dynamic range, as a prior knowledge in the recovery process, we construct a learnable illuminance interpolator and thereby compensating for non-uniform lighting. With the intention of adapting denoising without annotated data, we design a self-calibrated denoiser with the intrinsic image properties to acquire noise-free low-light images. Starting from the properties of natural image manifolds, a self-regularized recovery loss is introduced as a way to encourage more natural and realistic reflectance map. The model architecture and training losses, guided by prior knowledge, complement and benefit each other, forming a powerful unsupervised leaning framework. Comprehensive experiments demonstrate that the proposed algorithm produces competitive qualitative and quantitative results while maintaining favorable generalization capability in unknown real-world scenarios.
Posterior Estimation Using Deep Learning: A Simulation Study of Compartmental Modeling in Dynamic PET
Mar 17, 2023Background: In medical imaging, images are usually treated as deterministic, while their uncertainties are largely underexplored. Purpose: This work aims at using deep learning to efficiently estimate posterior distributions of imaging parameters, which in turn can be used to derive the most probable parameters as well as their uncertainties. Methods: Our deep learning-based approaches are based on a variational Bayesian inference framework, which is implemented using two different deep neural networks based on conditional variational auto-encoder (CVAE), CVAE-dual-encoder and CVAE-dual-decoder. The conventional CVAE framework, i.e., CVAE-vanilla, can be regarded as a simplified case of these two neural networks. We applied these approaches to a simulation study of dynamic brain PET imaging using a reference region-based kinetic model. Results: In the simulation study, we estimated posterior distributions of PET kinetic parameters given a measurement of time-activity curve. Our proposed CVAE-dual-encoder and CVAE-dual-decoder yield results that are in good agreement with the asymptotically unbiased posterior distributions sampled by Markov Chain Monte Carlo (MCMC). The CVAE-vanilla can also be used for estimating posterior distributions, although it has an inferior performance to both CVAE-dual-encoder and CVAE-dual-decoder. Conclusions: We have evaluated the performance of our deep learning approaches for estimating posterior distributions in dynamic brain PET. Our deep learning approaches yield posterior distributions, which are in good agreement with unbiased distributions estimated by MCMC. All these neural networks have different characteristics and can be chosen by the user for specific applications. The proposed methods are general and can be adapted to other problems.
Synthesizing audio from tongue motion during speech using tagged MRI via transformer
Feb 14, 2023Investigating the relationship between internal tissue point motion of the tongue and oropharyngeal muscle deformation measured from tagged MRI and intelligible speech can aid in advancing speech motor control theories and developing novel treatment methods for speech related-disorders. However, elucidating the relationship between these two sources of information is challenging, due in part to the disparity in data structure between spatiotemporal motion fields (i.e., 4D motion fields) and one-dimensional audio waveforms. In this work, we present an efficient encoder-decoder translation network for exploring the predictive information inherent in 4D motion fields via 2D spectrograms as a surrogate of the audio data. Specifically, our encoder is based on 3D convolutional spatial modeling and transformer-based temporal modeling. The extracted features are processed by an asymmetric 2D convolution decoder to generate spectrograms that correspond to 4D motion fields. Furthermore, we incorporate a generative adversarial training approach into our framework to further improve synthesis quality on our generated spectrograms. We experiment on 63 paired motion field sequences and speech waveforms, demonstrating that our framework enables the generation of clear audio waveforms from a sequence of motion fields. Thus, our framework has the potential to improve our understanding of the relationship between these two modalities and inform the development of treatments for speech disorders.
Successive Subspace Learning for Cardiac Disease Classification with Two-phase Deformation Fields from Cine MRI
Jan 21, 2023



Cardiac cine magnetic resonance imaging (MRI) has been used to characterize cardiovascular diseases (CVD), often providing a noninvasive phenotyping tool.~While recently flourished deep learning based approaches using cine MRI yield accurate characterization results, the performance is often degraded by small training samples. In addition, many deep learning models are deemed a ``black box," for which models remain largely elusive in how models yield a prediction and how reliable they are. To alleviate this, this work proposes a lightweight successive subspace learning (SSL) framework for CVD classification, based on an interpretable feedforward design, in conjunction with a cardiac atlas. Specifically, our hierarchical SSL model is based on (i) neighborhood voxel expansion, (ii) unsupervised subspace approximation, (iii) supervised regression, and (iv) multi-level feature integration. In addition, using two-phase 3D deformation fields, including end-diastolic and end-systolic phases, derived between the atlas and individual subjects as input offers objective means of assessing CVD, even with small training samples. We evaluate our framework on the ACDC2017 database, comprising one healthy group and four disease groups. Compared with 3D CNN-based approaches, our framework achieves superior classification performance with 140$\times$ fewer parameters, which supports its potential value in clinical use.