 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Emotion Recognition with Multiscale Area Attention and Data Augmentation
Feb 03, 2021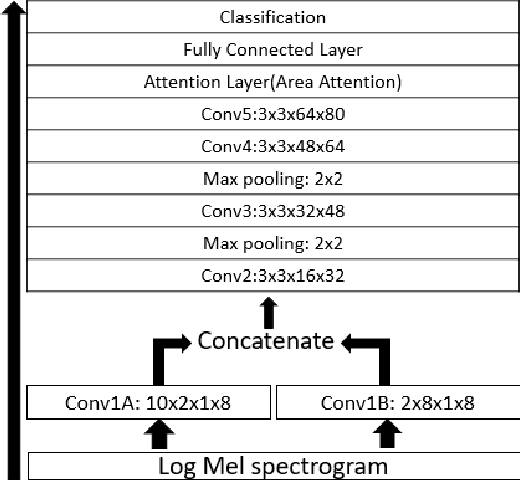

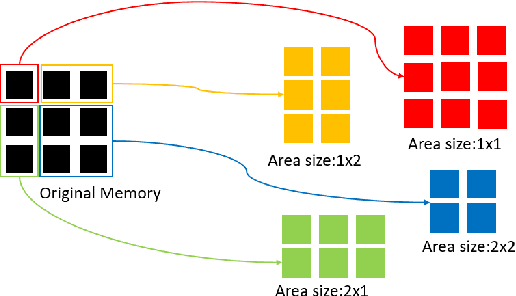
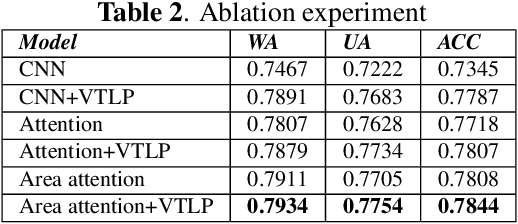
In Speech Emotion Recognition (SER), emotional characteristics often appear in diverse forms of energy patterns in spectrograms. Typical attention neural network classifiers of SER are usually optimized on a fixed attention granularity. In this paper, we apply multiscale area attention in a deep convolutional neural network to attend emotional characteristics with varied granularities and therefore the classifier can benefit from an ensemble of attentions with different scales. To deal with data sparsity, we conduct data augmentation with vocal tract length perturbation (VTLP) to improve the generalization capability of the classifier. Experiments are carried out on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) dataset. We achieved 79.34% weighted accuracy (WA) and 77.54% unweighted accuracy (UA), which, to the best of our knowledge, is the state of the art on this dataset.
Map Generation from Large Scale Incomplete and Inaccurate Data Labels
May 20, 2020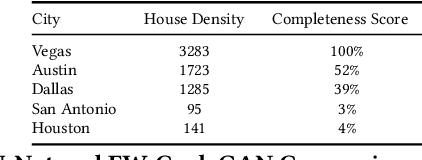
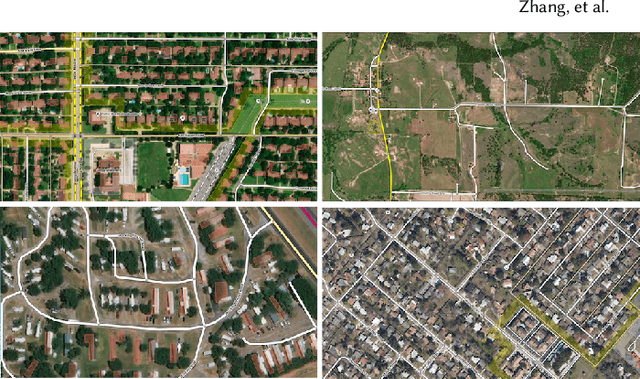

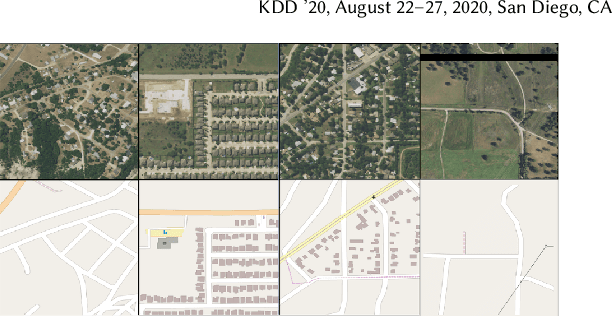
Accurately and globally mapping human infrastructure is an important and challenging task with applications in routing, regulation compliance monitoring, and natural disaster response management etc.. In this paper we present progress in developing an algorithmic pipeline and distributed compute system that automates the process of map creation using high resolution aerial images. Unlike previous studies, most of which use datasets that are available only in a few cities across the world, we utilizes publicly available imagery and map data, both of which cover the contiguous United States (CONUS). We approach the technical challenge of inaccurate and incomplete training data adopting state-of-the-art convolutional neural network architectures such as the U-Net and the CycleGAN to incrementally generate maps with increasingly more accurate and more complete labels of man-made infrastructure such as roads and houses. Since scaling the mapping task to CONUS calls for parallelization, we then adopted an asynchronous distributed stochastic parallel gradient descent training scheme to distribute the computational workload onto a cluster of GPUs with nearly linear speed-up.
Distributed Training of Deep Neural Network Acoustic Models for Automatic Speech Recognition
Feb 24, 2020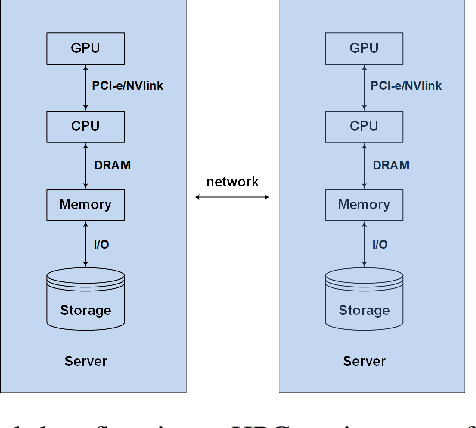
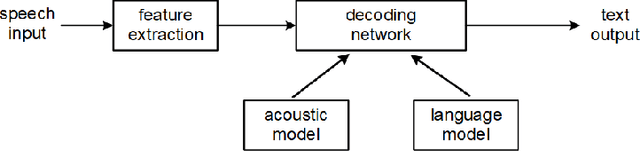
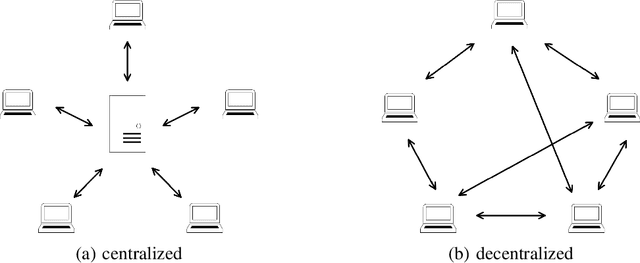
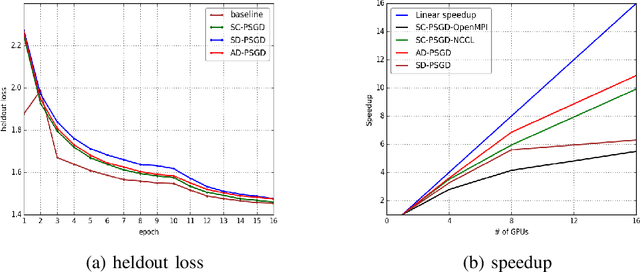
The past decade has witnessed great progress in Automatic Speech Recognition (ASR) due to advances in deep learning. The improvements in performance can be attributed to both improved models and large-scale training data. Key to training such models is the employment of efficient distributed learning techniques. In this article, we provide an overview of distributed training techniques for deep neural network acoustic models for ASR. Starting with the fundamentals of data parallel stochastic gradient descent (SGD) and ASR acoustic modeling, we will investigate various distributed training strategies and their realizations in high performance computing (HPC) environments with an emphasis on striking the balance between communication and computation. Experiments are carried out on a popular public benchmark to study the convergence, speedup and recognition performance of the investigated strategies.
Improving Efficiency in Large-Scale Decentralized Distributed Training
Feb 04, 2020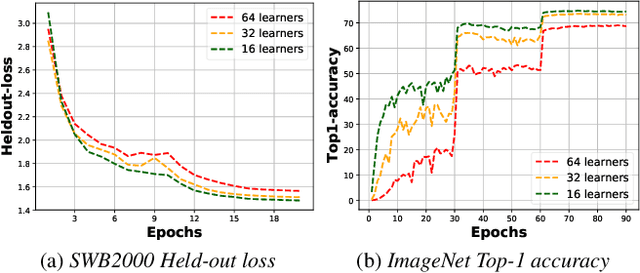
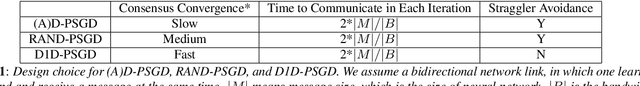
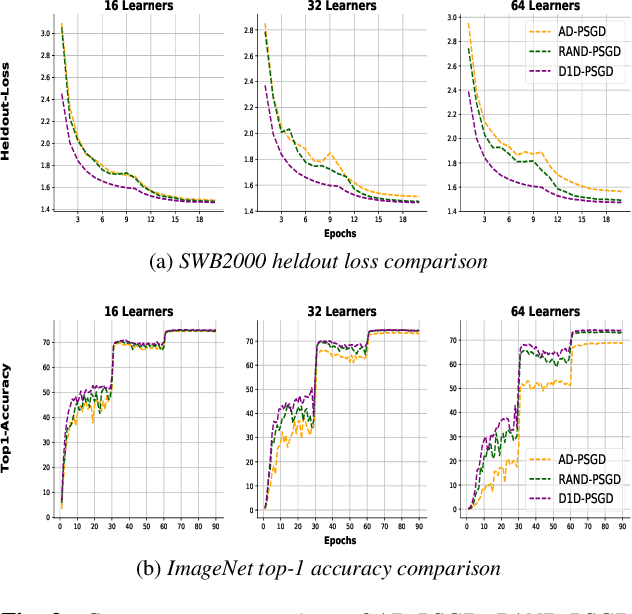

Decentralized Parallel SGD (D-PSGD) and its asynchronous variant Asynchronous Parallel SGD (AD-PSGD) is a family of distributed learning algorithms that have been demonstrated to perform well for large-scale deep learning tasks. One drawback of (A)D-PSGD is that the spectral gap of the mixing matrix decreases when the number of learners in the system increases, which hampers convergence. In this paper, we investigate techniques to accelerate (A)D-PSGD based training by improving the spectral gap while minimizing the communication cost. We demonstrate the effectiveness of our proposed techniques by running experiments on the 2000-hour Switchboard speech recognition task and the ImageNet computer vision task. On an IBM P9 supercomputer, our system is able to train an LSTM acoustic model in 2.28 hours with 7.5% WER on the Hub5-2000 Switchboard (SWB) test set and 13.3% WER on the CallHome (CH) test set using 64 V100 GPUs and in 1.98 hours with 7.7% WER on SWB and 13.3% WER on CH using 128 V100 GPUs, the fastest training time reported to date.
Towards Better Understanding of Adaptive Gradient Algorithms in Generative Adversarial Nets
Dec 26, 2019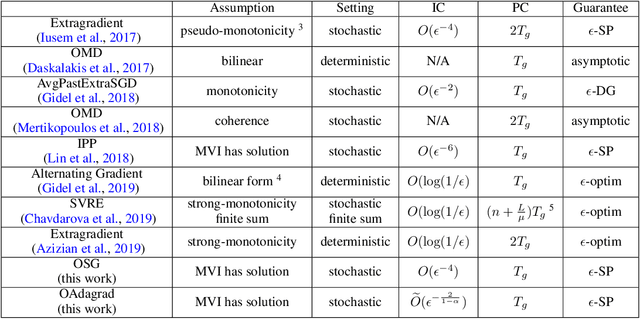
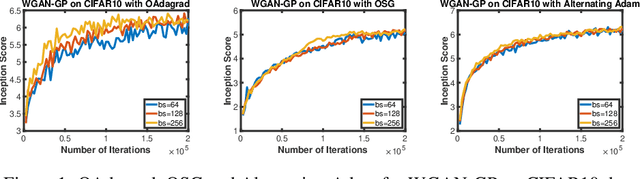
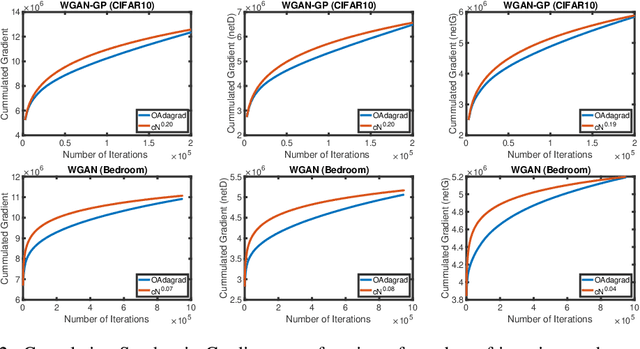
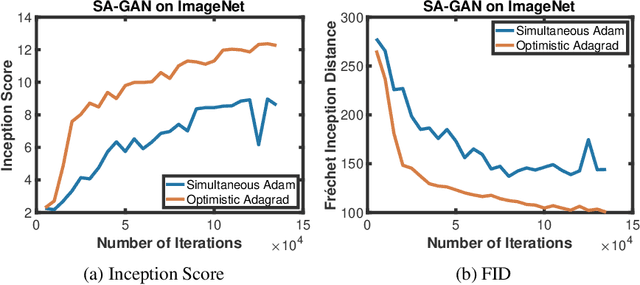
Adaptive gradient algorithms perform gradient-based updates using the history of gradients and are ubiquitous in training deep neural networks. While adaptive gradient methods theory is well understood for minimization problems, the underlying factors driving their empirical success in min-max problems such as GANs remain unclear. In this paper, we aim at bridging this gap from both theoretical and empirical perspectives. First, we analyze a variant of Optimistic Stochastic Gradient (OSG) proposed in~\citep{daskalakis2017training} for solving a class of non-convex non-concave min-max problem and establish $O(\epsilon^{-4})$ complexity for finding $\epsilon$-first-order stationary point, in which the algorithm only requires invoking one stochastic first-order oracle while enjoying state-of-the-art iteration complexity achieved by stochastic extragradient method by~\citep{iusem2017extragradient}. Then we propose an adaptive variant of OSG named Optimistic Adagrad (OAdagrad) and reveal an \emph{improved} adaptive complexity $\widetilde{O}\left(\epsilon^{-\frac{2}{1-\alpha}}\right)$~\footnote{Here $\widetilde{O}(\cdot)$ compresses a logarithmic factor of $\epsilon$.}, where $\alpha$ characterizes the growth rate of the cumulative stochastic gradient and $0\leq \alpha\leq 1/2$. To the best of our knowledge, this is the first work for establishing adaptive complexity in non-convex non-concave min-max optimization. Empirically, our experiments show that indeed adaptive gradient algorithms outperform their non-adaptive counterparts in GAN training. Moreover, this observation can be explained by the slow growth rate of the cumulative stochastic gradient, as observed empirically.
Task-Based Learning
Nov 19, 2019
This paper talks about task-based learning.
Decentralized Parallel Algorithm for Training Generative Adversarial Nets
Oct 30, 2019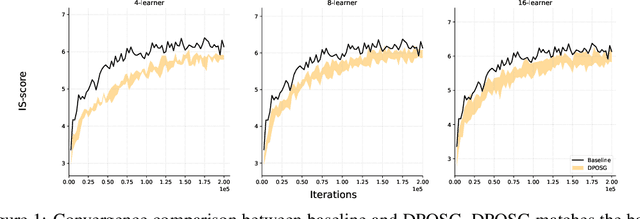
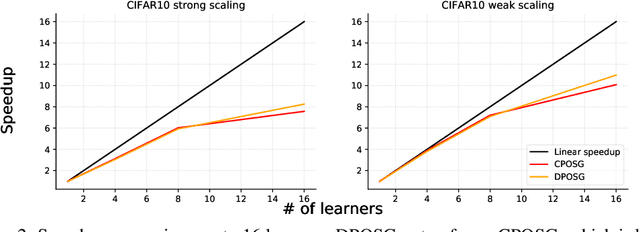
Generative Adversarial Networks (GANs) are powerful class of generative models in the deep learning community. Current practice on large-scale GAN training \cite{brock2018large} utilizes large models and distributed large-batch training strategies, and is implemented on deep learning frameworks (e.g., TensorFlow, PyTorch, etc.) designed in a centralized manner. In the centralized network topology, every worker needs to communicate with the central node. However, when the network bandwidth is low or network latency is high, the performance would be significantly degraded. Despite recent progress on decentralized algorithms for training deep neural networks, it remains unclear whether it is possible to train GANs in a decentralized manner. In this paper, we design a decentralized algorithm for solving a class of non-convex non-concave min-max problem with provable guarantee. Experimental results on GANs demonstrate the effectiveness of the proposed algorithm.
Challenging the Boundaries of Speech Recognition: The MALACH Corpus
Aug 09, 2019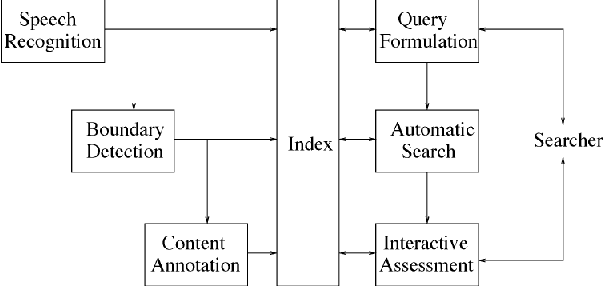
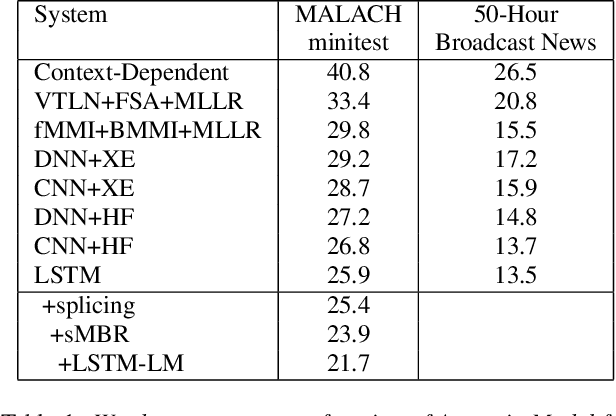
There has been huge progress in speech recognition over the last several years. Tasks once thought extremely difficult, such as SWITCHBOARD, now approach levels of human performance. The MALACH corpus (LDC catalog LDC2012S05), a 375-Hour subset of a large archive of Holocaust testimonies collected by the Survivors of the Shoah Visual History Foundation, presents significant challenges to the speech community. The collection consists of unconstrained, natural speech filled with disfluencies, heavy accents, age-related coarticulations, un-cued speaker and language switching, and emotional speech - all still open problems for speech recognition systems. Transcription is challenging even for skilled human annotators. This paper proposes that the community place focus on the MALACH corpus to develop speech recognition systems that are more robust with respect to accents, disfluencies and emotional speech. To reduce the barrier for entry, a lexicon and training and testing setups have been created and baseline results using current deep learning technologies are presented. The metadata has just been released by LDC (LDC2019S11). It is hoped that this resource will enable the community to build on top of these baselines so that the extremely important information in these and related oral histories becomes accessible to a wider audience.
Large-Scale Mixed-Bandwidth Deep Neural Network Acoustic Modeling for Automatic Speech Recognition
Jul 10, 2019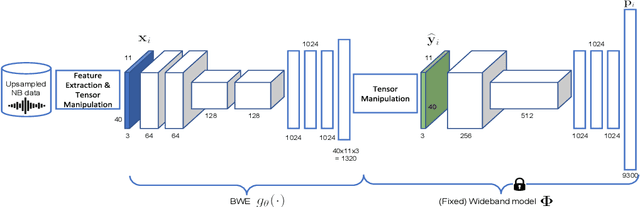

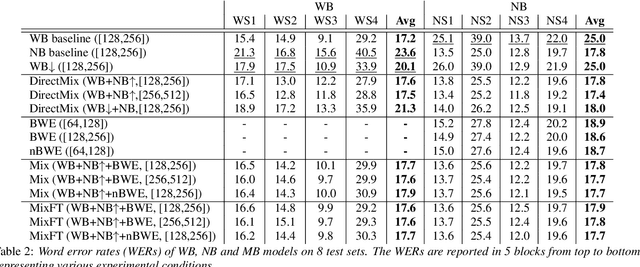
In automatic speech recognition (ASR), wideband (WB) and narrowband (NB) speech signals with different sampling rates typically use separate acoustic models. Therefore mixed-bandwidth (MB) acoustic modeling has important practical values for ASR system deployment. In this paper, we extensively investigate large-scale MB deep neural network acoustic modeling for ASR using 1,150 hours of WB data and 2,300 hours of NB data. We study various MB strategies including downsampling, upsampling and bandwidth extension for MB acoustic modeling and evaluate their performance on 8 diverse WB and NB test sets from various application domains. To deal with the large amounts of training data, distributed training is carried out on multiple GPUs using synchronous data parallelism.
Acoustic Model Optimization Based On Evolutionary Stochastic Gradient Descent with Anchors for Automatic Speech Recognition
Jul 10, 2019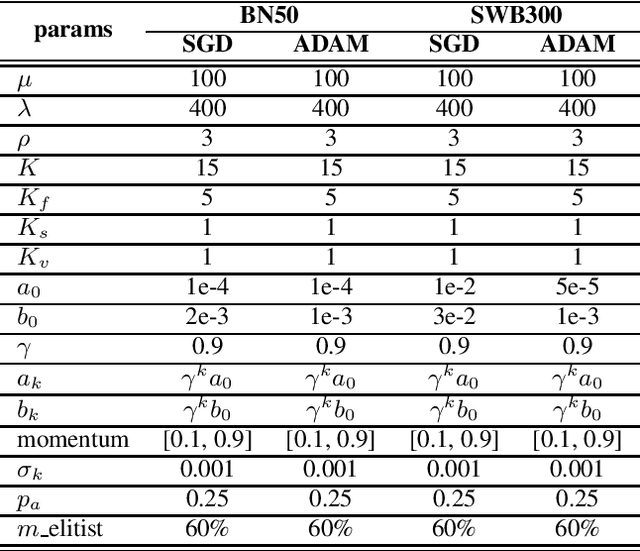
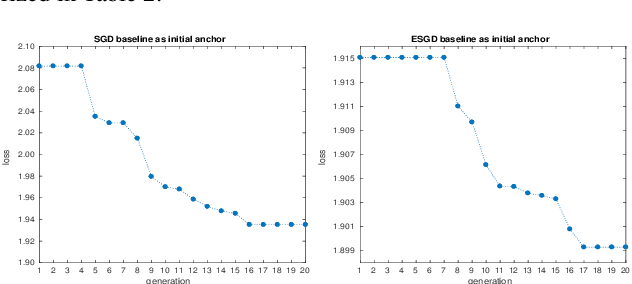
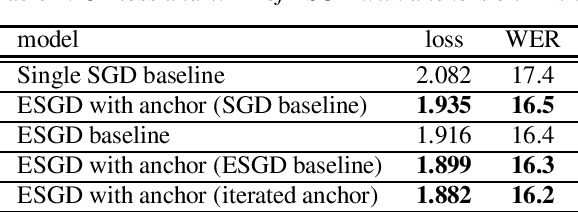
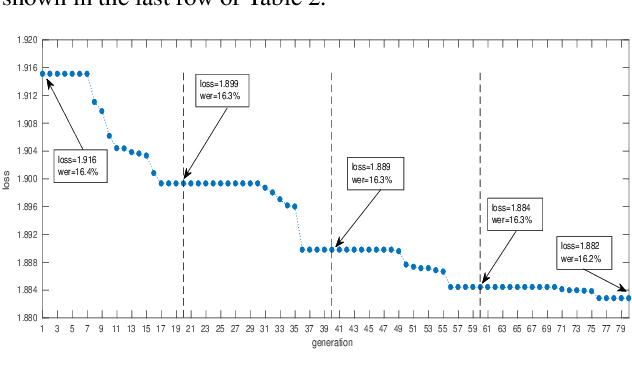
Evolutionary stochastic gradient descent (ESGD) was proposed as a population-based approach that combines the merits of gradient-aware and gradient-free optimization algorithms for superior overall optimization performance. In this paper we investigate a variant of ESGD for optimization of acoustic models for automatic speech recognition (ASR). In this variant, we assume the existence of a well-trained acoustic model and use it as an anchor in the parent population whose good "gene" will propagate in the evolution to the offsprings. We propose an ESGD algorithm leveraging the anchor models such that it guarantees the best fitness of the population will never degrade from the anchor model. Experiments on 50-hour Broadcast News (BN50) and 300-hour Switchboard (SWB300) show that the ESGD with anchors can further improve the loss and ASR performance over the existing well-trained acoustic models.