 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Human Vision Inspired Action Recognition using Adaptive Spatiotemporal Sampling
Jul 14, 2022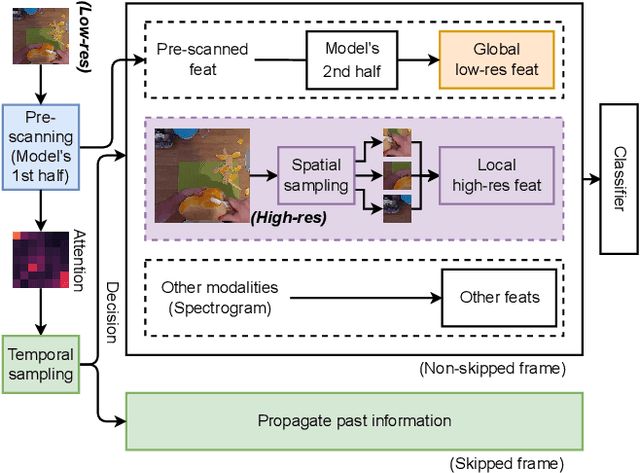

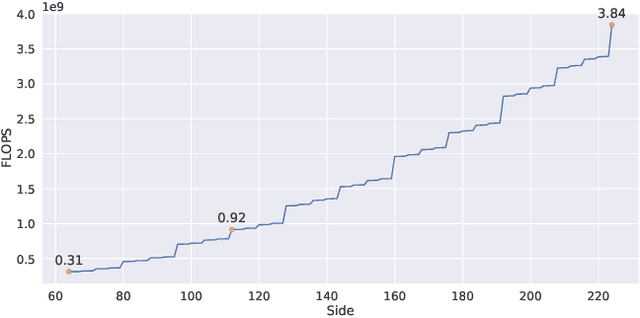

Adaptive sampling that exploits the spatiotemporal redundancy in videos is critical for always-on action recognition on wearable devices with limited computing and battery resources. The commonly used fixed sampling strategy is not context-aware and may under-sample the visual content, and thus adversely impacts both computation efficiency and accuracy. Inspired by the concepts of foveal vision and pre-attentive processing from the human visual perception mechanism, we introduce a novel adaptive spatiotemporal sampling scheme for efficient action recognition. Our system pre-scans the global scene context at low-resolution and decides to skip or request high-resolution features at salient regions for further processing. We validate the system on EPIC-KITCHENS and UCF-101 datasets for action recognition, and show that our proposed approach can greatly speed up inference with a tolerable loss of accuracy compared with those from state-of-the-art baselines. Source code is available in https://github.com/knmac/adaptive_spatiotemporal.
Large-Scale Mixed-Bandwidth Deep Neural Network Acoustic Modeling for Automatic Speech Recognition
Jul 10, 2019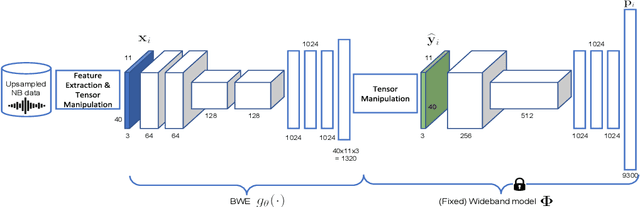

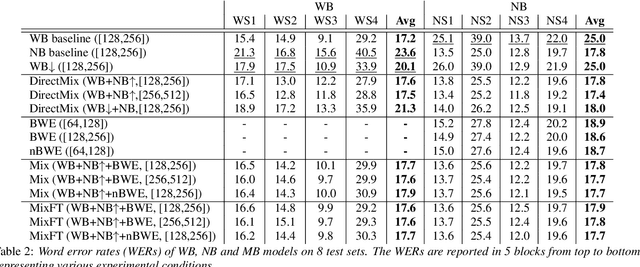
In automatic speech recognition (ASR), wideband (WB) and narrowband (NB) speech signals with different sampling rates typically use separate acoustic models. Therefore mixed-bandwidth (MB) acoustic modeling has important practical values for ASR system deployment. In this paper, we extensively investigate large-scale MB deep neural network acoustic modeling for ASR using 1,150 hours of WB data and 2,300 hours of NB data. We study various MB strategies including downsampling, upsampling and bandwidth extension for MB acoustic modeling and evaluate their performance on 8 diverse WB and NB test sets from various application domains. To deal with the large amounts of training data, distributed training is carried out on multiple GPUs using synchronous data parallelism.
Locally-Consistent Deformable Convolution Networks for Fine-Grained Action Detection
Nov 22, 2018
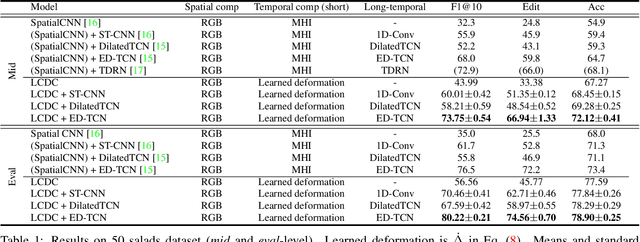
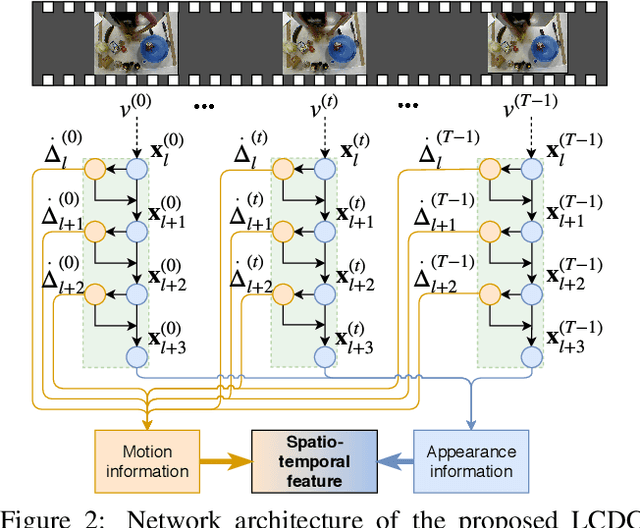
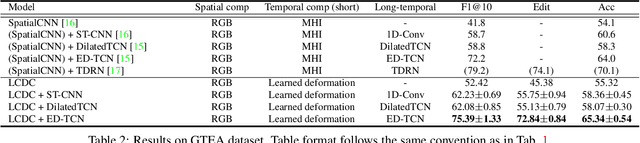
Fine-grained action detection is an important task with numerous applications in robotics, human-computer interaction, and video surveillance. Several existing methods use the popular two-stream approach, which learns the spatial and temporal information independently from one another. Additionally, the temporal stream of the model usually relies on extracted optical flow from the video stream. In this work, we propose a deep learning model to jointly learn both spatial and temporal information without the necessity of optical flow. We also propose a novel convolution, namely locally-consistent deformable convolution, which enforces a local coherency constraint on the receptive fields. The model produces short-term spatio-temporal features, which can be flexibly used in conjunction with other long-temporal modeling networks. The proposed features used in conjunction with a major state-of-the-art long-temporal model ED-TCN outperforms the original ED-TCN implementation on two fine-grained action datasets: 50 Salads and GTEA, by up to 10.0% and 4.3%, and also outperforms the recent state-of-the-art TDRN, by up to 5.9% and 2.6%.