 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldOdysseyBench: An Open-World Benchmark for Long-Horizon Stability of Interactive World Models
Jul 02, 2026Despite rapid progress in interactive world models (IWMs), existing benchmarks evaluate action following only at trajectory level and ignore memory and interaction physics. We introduce WorldOdysseyBench, an open-world benchmark for long-horizon stability across four dimensions, each with tailored innovations: (i) Action: per-frame action metric bypassing cross-model semantic scale disparity and exposing failures hidden by trajectory; (ii) Vision: segment-based drift metric capturing non-monotonic mid-sequence collapse missed by start-vs-end comparisons; (iii) Physics: controllability-gated evaluation over mechanics, optics, and 3D consistency, scoring plausibility under faithful action execution; (iv) Memory: action-decoupled protocol evaluating scene memory via transition-localized 3D point-cloud reconstruction and subject memory via tracking-plus-VLM reasoning. The benchmark comprises 600+ test cases across Nature, Urban, and Indoor scenes in first/third-person views with WASD 10-60s continuous interaction. Evaluating 10+ open/closed-source models reveals none reliably satisfies all dimensions; even the best achieves only moderate scores. Advances on WorldOdysseyBench are steps toward IWMs that are stable, physically grounded, memory-faithful, and deployable in real-world applications.
WorldRoamBench: An Open-World Benchmark for Long-Horizon Stability of Interactive World Models
Jun 30, 2026Despite rapid progress in interactive world models (IWMs), existing benchmarks evaluate action following only at trajectory level and ignore memory and interaction physics. We introduce WorldRoamBench, an open-world benchmark for long-horizon stability across four dimensions, each with tailored innovations: (i) Action: per-frame action metric bypassing cross-model semantic scale disparity and exposing failures hidden by trajectory; (ii) Vision: segment-based drift metric capturing non-monotonic mid-sequence collapse missed by start-vs-end comparisons; (iii) Physics: controllability-gated evaluation over mechanics, optics, and 3D consistency, scoring plausibility under faithful action execution; (iv) Memory: action-decoupled protocol evaluating scene memory via transition-localized 3D point-cloud reconstruction and subject memory via tracking-plus-VLM reasoning. The benchmark comprises 600+ test cases across Nature, Urban, and Indoor scenes in first/third-person views with WASD 10-60s continuous interaction. Evaluating 10+ open/closed-source models reveals none reliably satisfies all dimensions; even the best achieves only moderate scores. Advances on WorldRoamBench are steps toward IWMs that are stable, physically grounded, memory-faithful, and deployable in real-world applications.
Multi-Stakeholder LLM Alignment: Decomposing Estimation from Aggregation
May 26, 2026Multi-stakeholder tasks require one output to satisfy users with conflicting preferences. Holistic LLM judges conflate utility estimation and utility aggregation, yielding unstable implicit weights. We show empirically and theoretically that this aggregation-specific \emph{weighting noise} can create large score shifts when stakeholder satisfaction is dispersed; in our experiments, these weight-induced shifts also increase with stakeholder count. We propose \textsc{DecompR}: counterfactual-calibrated weights are fixed from query structure before candidate scoring, while per-role utilities are estimated independently, removing candidate-dependent weight drift and reducing estimation noise.
Aligning Agents via Planning: A Benchmark for Trajectory-Level Reward Modeling
Apr 09, 2026In classical Reinforcement Learning from Human Feedback (RLHF), Reward Models (RMs) serve as the fundamental signal provider for model alignment. As Large Language Models evolve into agentic systems capable of autonomous tool invocation and complex reasoning, the paradigm of reward modeling faces unprecedented challenges--most notably, the lack of benchmarks specifically designed to assess RM capabilities within tool-integrated environments. To address this gap, we present Plan-RewardBench, a trajectory-level preference benchmark designed to evaluate how well judges distinguish preferred versus distractor agent trajectories in complex tool-using scenarios. Plan-RewardBench covers four representative task families -- (i) Safety Refusal, (ii) Tool-Irrelevance / Unavailability, (iii) Complex Planning, and (iv) Robust Error Recovery -- comprising validated positive trajectories and confusable hard negatives constructed via multi-model natural rollouts, rule-based perturbations, and minimal-edit LLM perturbations. We benchmark representative RMs (generative, discriminative, and LLM-as-Judge) under a unified pairwise protocol, reporting accuracy trends across varying trajectory lengths and task categories. Furthermore, we provide diagnostic analyses of prevalent failure modes. Our results reveal that all three evaluator families face substantial challenges, with performance degrading sharply on long-horizon trajectories, underscoring the necessity for specialized training in agentic, trajectory-level reward modeling. Ultimately, Plan-RewardBench aims to serve as both a practical evaluation suite and a reusable blueprint for constructing agentic planning preference data.
AMAP Agentic Planning Technical Report
Dec 31, 2025We present STAgent, an agentic large language model tailored for spatio-temporal understanding, designed to solve complex tasks such as constrained point-of-interest discovery and itinerary planning. STAgent is a specialized model capable of interacting with ten distinct tools within spatio-temporal scenarios, enabling it to explore, verify, and refine intermediate steps during complex reasoning. Notably, STAgent effectively preserves its general capabilities. We empower STAgent with these capabilities through three key contributions: (1) a stable tool environment that supports over ten domain-specific tools, enabling asynchronous rollout and training; (2) a hierarchical data curation framework that identifies high-quality data like a needle in a haystack, curating high-quality queries with a filter ratio of 1:10,000, emphasizing both diversity and difficulty; and (3) a cascaded training recipe that starts with a seed SFT stage acting as a guardian to measure query difficulty, followed by a second SFT stage fine-tuned on queries with high certainty, and an ultimate RL stage that leverages data of low certainty. Initialized with Qwen3-30B-A3B to establish a strong SFT foundation and leverage insights into sample difficulty, STAgent yields promising performance on TravelBench while maintaining its general capabilities across a wide range of general benchmarks, thereby demonstrating the effectiveness of our proposed agentic model.
Enhancing Human Experience in Human-Agent Collaboration: A Human-Centered Modeling Approach Based on Positive Human Gain
Jan 28, 2024



Existing game AI research mainly focuses on enhancing agents' abilities to win games, but this does not inherently make humans have a better experience when collaborating with these agents. For example, agents may dominate the collaboration and exhibit unintended or detrimental behaviors, leading to poor experiences for their human partners. In other words, most game AI agents are modeled in a "self-centered" manner. In this paper, we propose a "human-centered" modeling scheme for collaborative agents that aims to enhance the experience of humans. Specifically, we model the experience of humans as the goals they expect to achieve during the task. We expect that agents should learn to enhance the extent to which humans achieve these goals while maintaining agents' original abilities (e.g., winning games). To achieve this, we propose the Reinforcement Learning from Human Gain (RLHG) approach. The RLHG approach introduces a "baseline", which corresponds to the extent to which humans primitively achieve their goals, and encourages agents to learn behaviors that can effectively enhance humans in achieving their goals better. We evaluate the RLHG agent in the popular Multi-player Online Battle Arena (MOBA) game, Honor of Kings, by conducting real-world human-agent tests. Both objective performance and subjective preference results show that the RLHG agent provides participants better gaming experience.
AIM 2019 Challenge on Image Demoireing: Methods and Results
Nov 08, 2019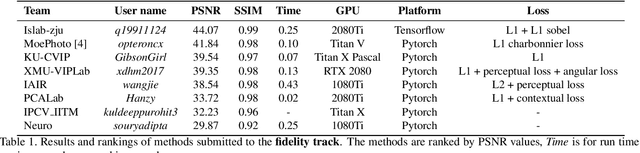
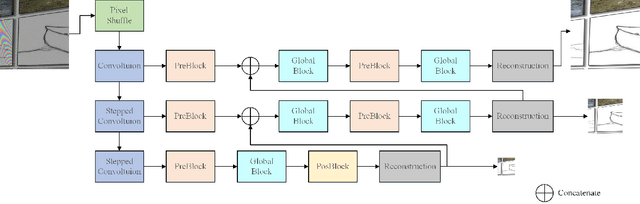
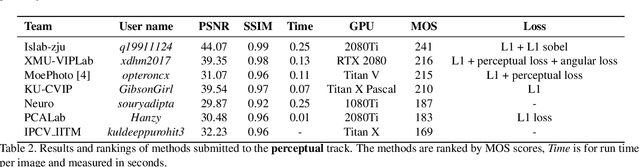
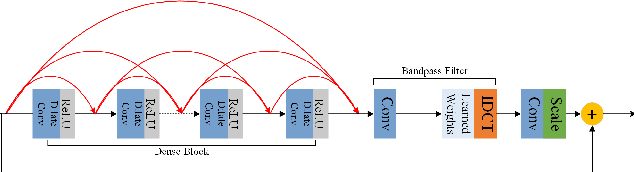
This paper reviews the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. This paper describes the challenge, and focuses on the proposed solutions and their results. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. A new dataset, called LCDMoire was created for this challenge, and consists of 10,200 synthetically generated image pairs (moire and clean ground truth). The challenge was divided into 2 tracks. Track 1 targeted fidelity, measuring the ability of demoire methods to obtain a moire-free image compared with the ground truth, while Track 2 examined the perceptual quality of demoire methods. The tracks had 60 and 39 registered participants, respectively. A total of eight teams competed in the final testing phase. The entries span the current the state-of-the-art in the image demoireing problem.