 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Bias into Bugs: Bandit-Guided Style Manipulation Attacks on LLM Judges
May 28, 2026The known stylistic biases in LLM judges, such as a preference for verbosity or specific sentence structures, present an underexplored security vulnerability. In this work, we introduce BITE (BIas exploraTion and Exploitation), a black-box adversarial framework that learns semantics-preserving edits to mislead an LLM judge and artificially inflate the scores it assigns. We cast the selection of stylistic edits as a contextual bandit problem and use a LinUCB policy to adaptively choose edits that maximize the judge's score without access to model parameters or gradients. Empirically, we test BITE across a diverse range of LLM judges and tasks, including both pointwise and pairwise comparisons on chatbot leaderboards and AI-reviewer benchmarks. BITE achieves an attack success rate exceeding 65% and raises scores by 1-2 points on a 9-point scale, all while preserving semantic equivalence. We further assess the attack's stealthiness, showing that BITE evades standard style-control methods and several detection baselines. Our findings expose a fundamental weakness in the LLM-as-a-judge paradigm and motivate robust, attack-aware evaluation. Our code is available at https://github.com/xianglinyang/llm-as-a-judge-attack.
Inverting the Shield: Systematically Generating Safety Tests from Policy Specifications
May 24, 2026The widespread integration of Large Language Models (LLMs) necessitates rigorous and systematic safety evaluation. Existing paradigms either rely on constructed benchmarks to assess safety from predefined perspectives, or employ dynamic red-teaming to probe potential vulnerabilities. While effective, these approaches face challenges, as they depend heavily on expert domain knowledge, offer limited systematic guarantees, and are vulnerable to rapid obsolescence. To address these limitations, we introduce a novel framework POLARIS that brings the rigor of specification-based software testing to AI safety. POLARIS first compiles unstructured natural-language policies into First-Order Logic (FOL) representations, establishing a traceable link between high-level rules and concrete test cases. This formalization enables the construction of a Semantic Policy Graph, where complex policy violation scenarios are encoded as traversable paths. By systematically exploring this graph, POLARIS uncovers compositional violation patterns, which are then instantiated into executable natural-language test queries, enabling coverage-driven and reproducible safety testing. Experiments demonstrate that POLARIS achieves higher policy coverage and attack success counts compared to established baselines. Crucially, by bridging formal methods and AI safety, POLARIS provides a principled, automated approach to ensuring LLMs adhere to safety-critical policies with verifiable traceability. We release our code at https://github.com/huac-lxy/POLARIS.
LLM-enabled Applications Require System-Level Threat Monitoring
Feb 23, 2026LLM-enabled applications are rapidly reshaping the software ecosystem by using large language models as core reasoning components for complex task execution. This paradigm shift, however, introduces fundamentally new reliability challenges and significantly expands the security attack surface, due to the non-deterministic, learning-driven, and difficult-to-verify nature of LLM behavior. In light of these emerging and unavoidable safety challenges, we argue that such risks should be treated as expected operational conditions rather than exceptional events, necessitating a dedicated incident-response perspective. Consequently, the primary barrier to trustworthy deployment is not further improving model capability but establishing system-level threat monitoring mechanisms that can detect and contextualize security-relevant anomalies after deployment -- an aspect largely underexplored beyond testing or guardrail-based defenses. Accordingly, this position paper advocates systematic and comprehensive monitoring of security threats in LLM-enabled applications as a prerequisite for reliable operation and a foundation for dedicated incident-response frameworks.
Zombie Agents: Persistent Control of Self-Evolving LLM Agents via Self-Reinforcing Injections
Feb 17, 2026Self-evolving LLM agents update their internal state across sessions, often by writing and reusing long-term memory. This design improves performance on long-horizon tasks but creates a security risk: untrusted external content observed during a benign session can be stored as memory and later treated as instruction. We study this risk and formalize a persistent attack we call a Zombie Agent, where an attacker covertly implants a payload that survives across sessions, effectively turning the agent into a puppet of the attacker. We present a black-box attack framework that uses only indirect exposure through attacker-controlled web content. The attack has two phases. During infection, the agent reads a poisoned source while completing a benign task and writes the payload into long-term memory through its normal update process. During trigger, the payload is retrieved or carried forward and causes unauthorized tool behavior. We design mechanism-specific persistence strategies for common memory implementations, including sliding-window and retrieval-augmented memory, to resist truncation and relevance filtering. We evaluate the attack on representative agent setups and tasks, measuring both persistence over time and the ability to induce unauthorized actions while preserving benign task quality. Our results show that memory evolution can convert one-time indirect injection into persistent compromise, which suggests that defenses focused only on per-session prompt filtering are not sufficient for self-evolving agents.
Sparse Layer Sharpness-Aware Minimization for Efficient Fine-Tuning
Feb 10, 2026Sharpness-aware minimization (SAM) seeks the minima with a flat loss landscape to improve the generalization performance in machine learning tasks, including fine-tuning. However, its extra parameter perturbation step doubles the computation cost, which becomes the bottleneck of SAM in the practical implementation. In this work, we propose an approach SL-SAM to break this bottleneck by introducing the sparse technique to layers. Our key innovation is to frame the dynamic selection of layers for both the gradient ascent (perturbation) and descent (update) steps as a multi-armed bandit problem. At the beginning of each iteration, SL-SAM samples a part of the layers of the model according to the gradient norm to participate in the backpropagation of the following parameter perturbation and update steps, thereby reducing the computation complexity. We then provide the analysis to guarantee the convergence of SL-SAM. In the experiments of fine-tuning models in several tasks, SL-SAM achieves the performances comparable to the state-of-the-art baselines, including a \#1 rank on LLM fine-tuning. Meanwhile, SL-SAM significantly reduces the ratio of active parameters in backpropagation compared to vanilla SAM (SL-SAM activates 47\%, 22\% and 21\% parameters on the vision, moderate and large language model respectively while vanilla SAM always activates 100\%), verifying the efficiency of our proposed algorithm.
Enhancing Model Defense Against Jailbreaks with Proactive Safety Reasoning
Jan 31, 2025



Large language models (LLMs) are vital for a wide range of applications yet remain susceptible to jailbreak threats, which could lead to the generation of inappropriate responses. Conventional defenses, such as refusal and adversarial training, often fail to cover corner cases or rare domains, leaving LLMs still vulnerable to more sophisticated attacks. We propose a novel defense strategy, Safety Chain-of-Thought (SCoT), which harnesses the enhanced \textit{reasoning capabilities} of LLMs for proactive assessment of harmful inputs, rather than simply blocking them. SCoT augments any refusal training datasets to critically analyze the intent behind each request before generating answers. By employing proactive reasoning, SCoT enhances the generalization of LLMs across varied harmful queries and scenarios not covered in the safety alignment corpus. Additionally, it generates detailed refusals specifying the rules violated. Comparative evaluations show that SCoT significantly surpasses existing defenses, reducing vulnerability to out-of-distribution issues and adversarial manipulations while maintaining strong general capabilities.
Exploring the Evolution of Hidden Activations with Live-Update Visualization
May 24, 2024Monitoring the training of neural networks is essential for identifying potential data anomalies, enabling timely interventions and conserving significant computational resources. Apart from the commonly used metrics such as losses and validation accuracies, the hidden representation could give more insight into the model progression. To this end, we introduce SentryCam, an automated, real-time visualization tool that reveals the progression of hidden representations during training. Our results show that this visualization offers a more comprehensive view of the learning dynamics compared to basic metrics such as loss and accuracy over various datasets. Furthermore, we show that SentryCam could facilitate detailed analysis such as task transfer and catastrophic forgetting to a continual learning setting. The code is available at https://github.com/xianglinyang/SentryCam.
DeepVisualInsight: Time-Travelling Visualization for Spatio-Temporal Causality of Deep Classification Training
Dec 31, 2021
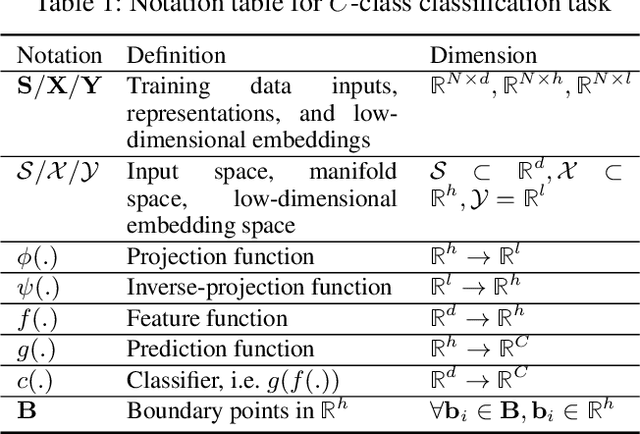
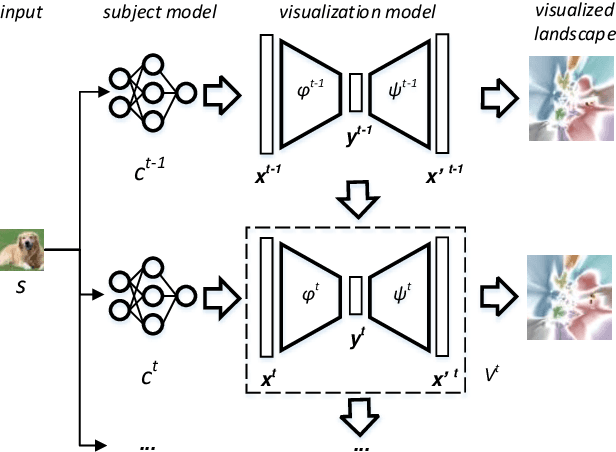
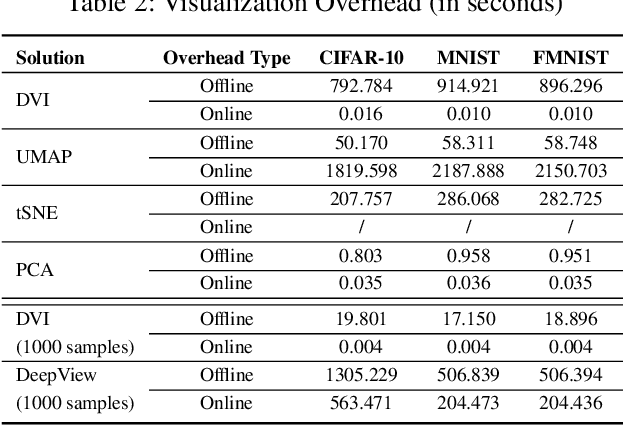
Understanding how the predictions of deep learning models are formed during the training process is crucial to improve model performance and fix model defects, especially when we need to investigate nontrivial training strategies such as active learning, and track the root cause of unexpected training results such as performance degeneration. In this work, we propose a time-travelling visual solution DeepVisualInsight (DVI), aiming to manifest the spatio-temporal causality while training a deep learning image classifier. The spatio-temporal causality demonstrates how the gradient-descent algorithm and various training data sampling techniques can influence and reshape the layout of learnt input representation and the classification boundaries in consecutive epochs. Such causality allows us to observe and analyze the whole learning process in the visible low dimensional space. Technically, we propose four spatial and temporal properties and design our visualization solution to satisfy them. These properties preserve the most important information when inverse-)projecting input samples between the visible low-dimensional and the invisible high-dimensional space, for causal analyses. Our extensive experiments show that, comparing to baseline approaches, we achieve the best visualization performance regarding the spatial/temporal properties and visualization efficiency. Moreover, our case study shows that our visual solution can well reflect the characteristics of various training scenarios, showing good potential of DVI as a debugging tool for analyzing deep learning training processes.