 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScreenplay Quality Assessment: Can We Predict Who Gets Nominated?
May 13, 2020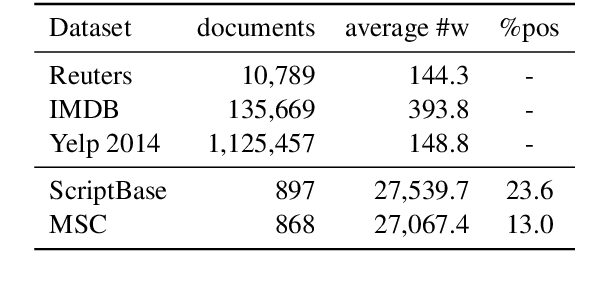
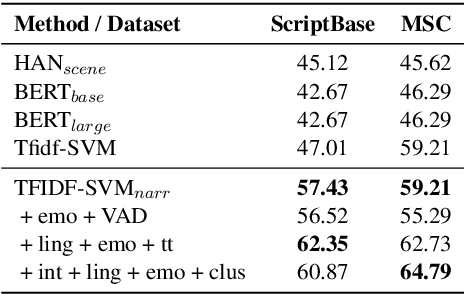
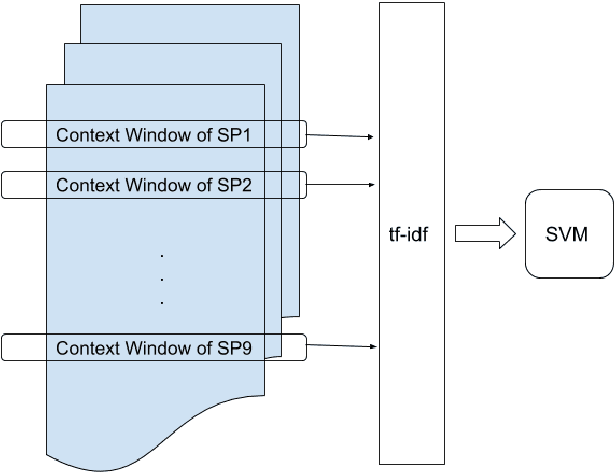
Deciding which scripts to turn into movies is a costly and time-consuming process for filmmakers. Thus, building a tool to aid script selection, an initial phase in movie production, can be very beneficial. Toward that goal, in this work, we present a method to evaluate the quality of a screenplay based on linguistic cues. We address this in a two-fold approach: (1) we define the task as predicting nominations of scripts at major film awards with the hypothesis that the peer-recognized scripts should have a greater chance to succeed. (2) based on industry opinions and narratology, we extract and integrate domain-specific features into common classification techniques. We face two challenges (1) scripts are much longer than other document datasets (2) nominated scripts are limited and thus difficult to collect. However, with narratology-inspired modeling and domain features, our approach offers clear improvements over strong baselines. Our work provides a new approach for future work in screenplay analysis.
Contextualizing Hate Speech Classifiers with Post-hoc Explanation
May 05, 2020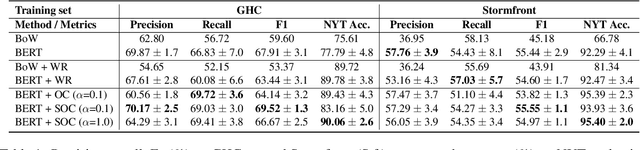
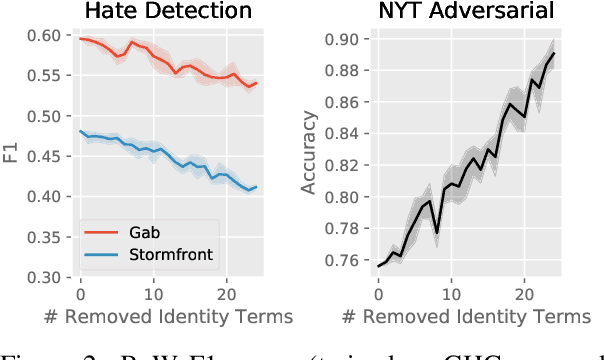
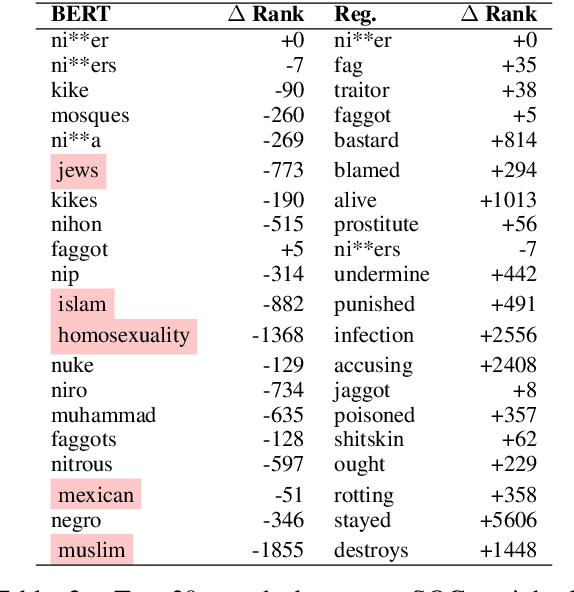

Hate speech classifiers trained on imbalanced datasets struggle to determine if group identifiers like "gay" or "black" are used in offensive or prejudiced ways. Such biases manifest in false positives when these identifiers are present, due to models' inability to learn the contexts which constitute a hateful usage of identifiers. We extract post-hoc explanations from fine-tuned BERT classifiers to detect bias towards identity terms. Then, we propose a novel regularization technique based on these explanations that encourages models to learn from the context of group identifiers in addition to the identifiers themselves. Our approach improved over baselines in limiting false positives on out-of-domain data while maintaining or improving in-domain performance.
Teaching Machine Comprehension with Compositional Explanations
May 02, 2020


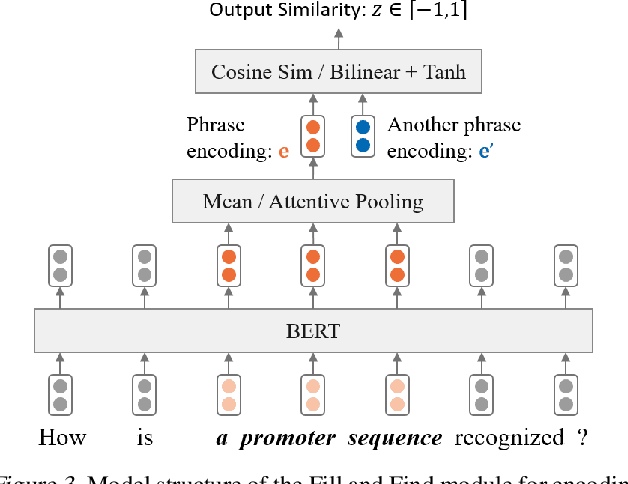
Advances in extractive machine reading comprehension (MRC) rely heavily on the collection of large scale human-annotated training data (in the form of "question-paragraph-answer span"). A single question-answer example provides limited supervision, while an explanation in natural language describing human's deduction process may generalize to many other questions that share similar solution patterns. In this paper, we focus on "teaching" machines on reading comprehension with (a small number of) natural language explanations. We propose a data augmentation framework that exploits the compositional nature of explanations to rapidly create pseudo-labeled data for training downstream MRC models. Structured variables and rules are extracted from each explanation and formulated into neural module teacher, which employs softened neural modules and combinatorial search to handle linguistic variations and overcome sparse coverage. The proposed work is particularly effective when limited annotation effort is available, and achieved a practicable F1 score of 59.80% with supervision from 52 explanations on the SQuAD dataset.
IsoBN: Fine-Tuning BERT with Isotropic Batch Normalization
May 02, 2020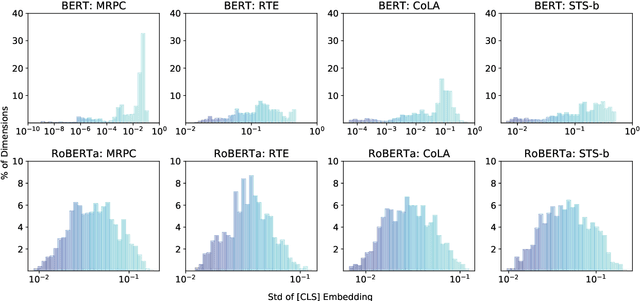

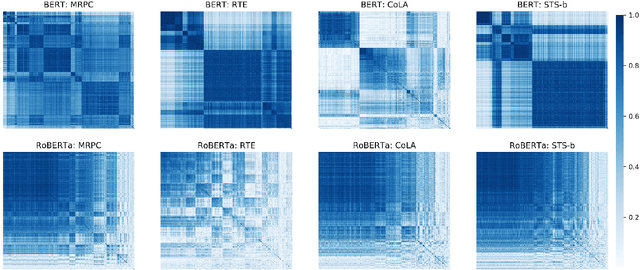
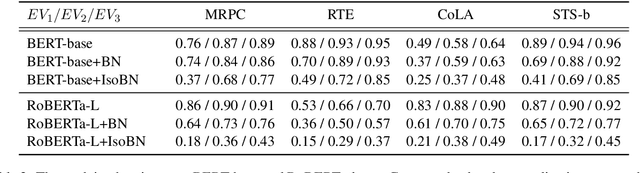
Fine-tuning pre-trained language models (PTLMs), such as BERT and its better variant RoBERTa, has been a common practice for advancing performance in natural language understanding (NLU) tasks. Recent advance in representation learning shows that isotropic (i.e., unit-variance and uncorrelated) embeddings can significantly improve performance on downstream tasks with faster convergence and better generalization. The isotropy of the pre-trained embeddings in PTLMs, however, is relatively under-explored. In this paper, we analyze the isotropy of the pre-trained [CLS] embeddings of PTLMs with straightforward visualization, and point out two major issues: high variance in their standard deviation, and high correlation between different dimensions. We also propose a new network regularization method, isotropic batch normalization (IsoBN) to address the issues, towards learning more isotropic representations in fine-tuning. This simple yet effective fine-tuning method yields about 1.0 absolute increment on the average of seven benchmark NLU tasks.
ForecastQA: Machine Comprehension of Temporal Text for Answering Forecasting Questions
May 02, 2020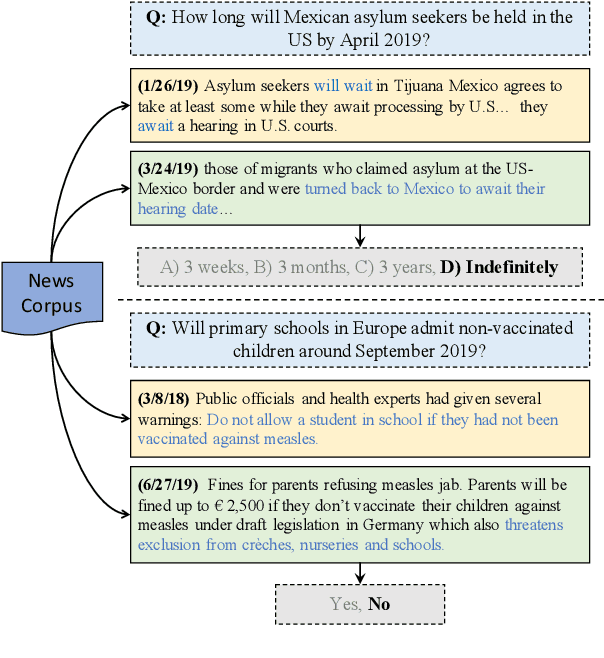
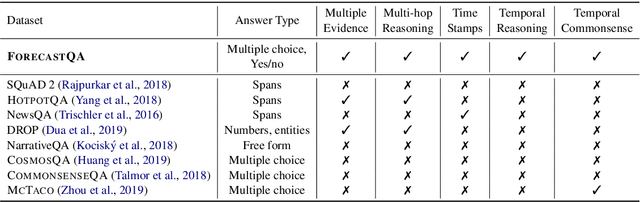

Textual data are often accompanied by time information (e.g., dates in news articles), but the information is easily overlooked on existing question answering datasets. In this paper, we introduce ForecastQA, a new open-domain question answering dataset consisting of 10k questions which requires temporal reasoning. ForecastQA is collected via a crowdsourcing effort based on news articles, where workers were asked to come up with yes-no or multiple-choice questions. We also present baseline models for our dataset, which is based on a pre-trained language model. In our study, our baseline model achieves 61.6% accuracy on the ForecastQA dataset. We expect that our new data will support future research efforts. Our data and code are publicly available at https://inklab.usc.edu/ForecastQA/.
Visually Grounded Continual Learning of Compositional Semantics
May 02, 2020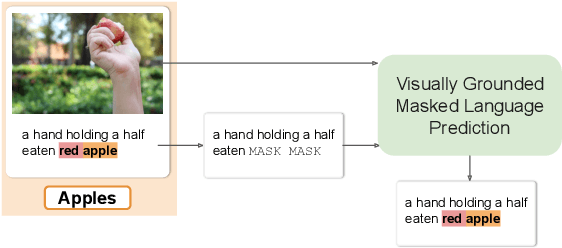
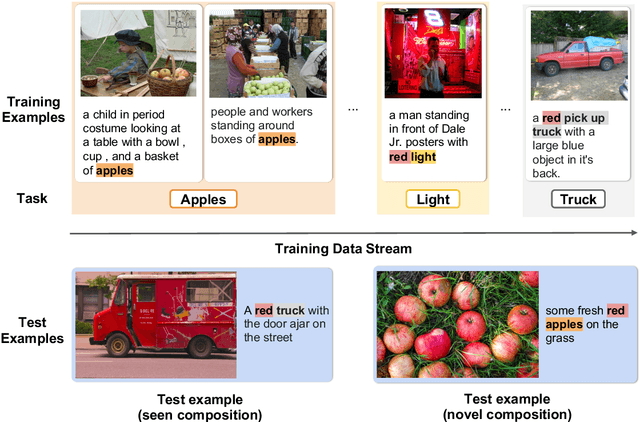
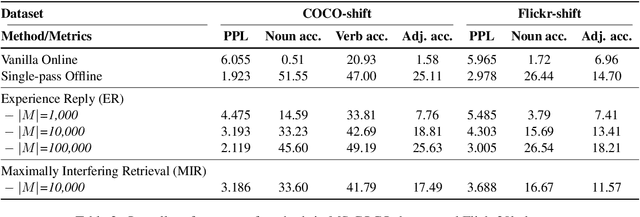
Children's language acquisition from the visual world is a real-world example of continual learning from dynamic and evolving environments; yet we lack a realistic setup to study neural networks' capability in human-like language acquisition. In this paper, we propose a realistic setup by simulating children's language acquisition process. We formulate language acquisition as a masked language modeling task where the model visits a stream of data with continuously shifting distribution. Our training and evaluation encode two important challenges in human's language learning, namely the continual learning and the compositionality. We show the performance of existing continual learning algorithms is far from satisfactory. We also study the interactions between memory based continual learning algorithms and compositional generalization and conclude that overcoming overfitting and compositional overfitting may be crucial for a good performance in our problem setup. Our code and data can be found at https://github.com/INK-USC/VG-CCL.
Can BERT Reason? Logically Equivalent Probes for Evaluating the Inference Capabilities of Language Models
May 02, 2020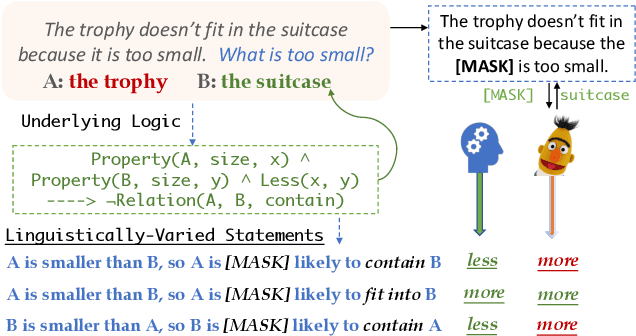

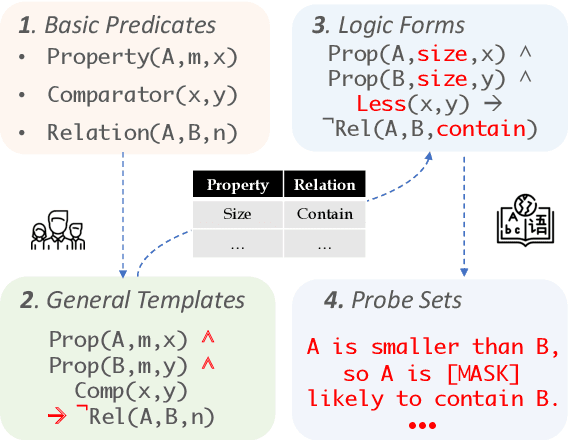

Pre-trained language models (PTLM) have greatly improved performance on commonsense inference benchmarks, however, it remains unclear whether they share a human's ability to consistently make correct inferences under perturbations. Prior studies of PTLMs have found inference deficits, but have failed to provide a systematic means of understanding whether these deficits are due to low inference abilities or poor inference robustness. In this work, we address this gap by developing a procedure that allows for the systematized probing of both PTLMs' inference abilities and robustness. Our procedure centers around the methodical creation of logically-equivalent, but syntactically-different sets of probes, of which we create a corpus of 14,400 probes coming from 60 logically-equivalent sets that can be used to probe PTLMs in three task settings. We find that despite the recent success of large PTLMs on commonsense benchmarks, their performances on our probes are no better than random guessing (even with fine-tuning) and are heavily dependent on biases--the poor overall performance, unfortunately, inhibits us from studying robustness. We hope our approach and initial probe set will assist future work in improving PTLMs' inference abilities, while also providing a probing set to test robustness under several linguistic variations--code and data will be released.
Connecting the Dots: A Knowledgeable Path Generator for Commonsense Question Answering
May 02, 2020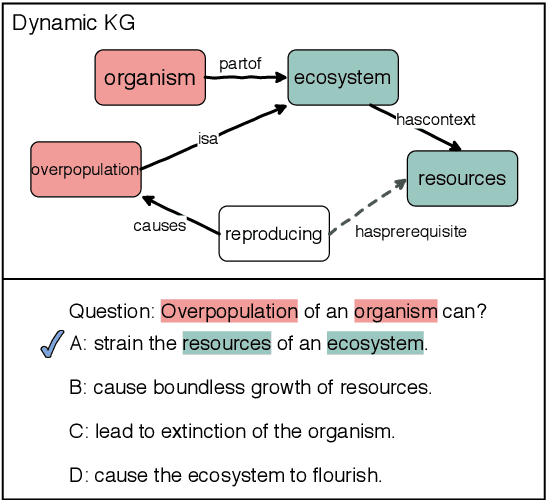

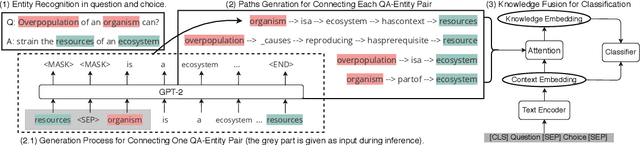

Commonsense question answering (QA) requires the modeling of general background knowledge about how the world operates and how entities interact with each other. Prior works leveraged manually curated commonsense knowledge graphs to help commonsense reasoning and demonstrated their effectiveness. However, these knowledge graphs are incomplete and thus may not contain the necessary knowledge for answering the questions. In this paper, we propose to learn a multi-hop knowledge path generator to generate structured evidence dynamically according to the questions. Our generator uses a pre-trained language model as the backbone, leveraging a large amount of unstructured knowledge stored in the language model to supplement the incompleteness of the knowledge base. The experiments on two commonsense QA datasets demonstrate the effectiveness of our method, which improves over strong baselines significantly and also provides human interpretable explanations for the predictions.
Birds have four legs?! NumerSense: Probing Numerical Commonsense Knowledge of Pre-trained Language Models
May 02, 2020
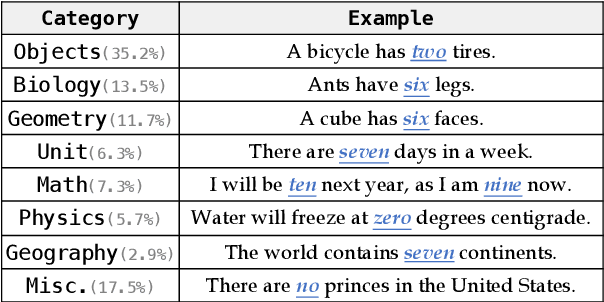
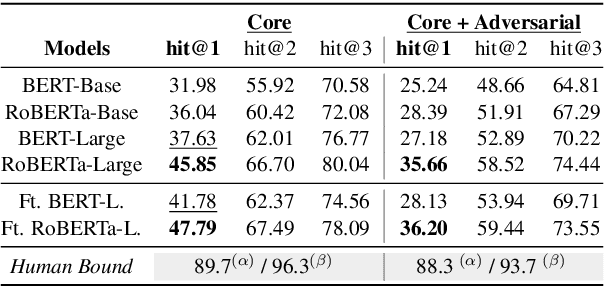
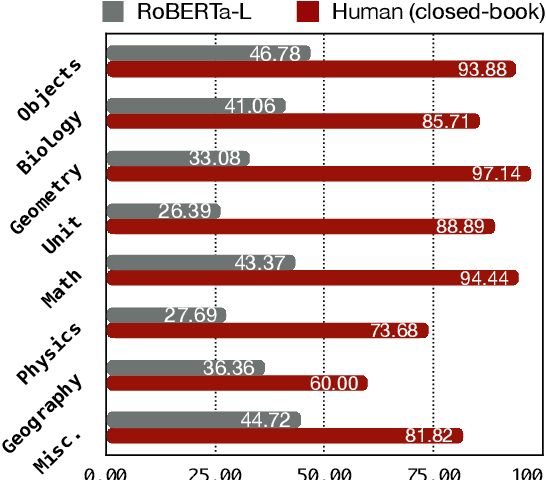
Recent works show that pre-trained masked language models, such as BERT, possess certain linguistic and commonsense knowledge. However, it remains to be seen what types of commonsense knowledge these models have access to. In this vein, we propose to study whether numerical commonsense knowledge -- commonsense knowledge that provides an understanding of the numeric relation between entities -- can be induced from pre-trained masked language models and to what extent is this access to knowledge robust against adversarial examples? To study this, we introduce a probing task with a diagnostic dataset, NumerSense, containing 3,145 masked-word-prediction probes. Surprisingly, our experiments and analysis reveal that: (1) BERT and its stronger variant RoBERTa perform poorly on our dataset prior to any fine-tuning; (2) fine-tuning with distant supervision does improve performance; (3) the best distantly supervised model still performs poorly when compared to humans (47.8% vs 96.3%).
Scalable Multi-Hop Relational Reasoning for Knowledge-Aware Question Answering
May 01, 2020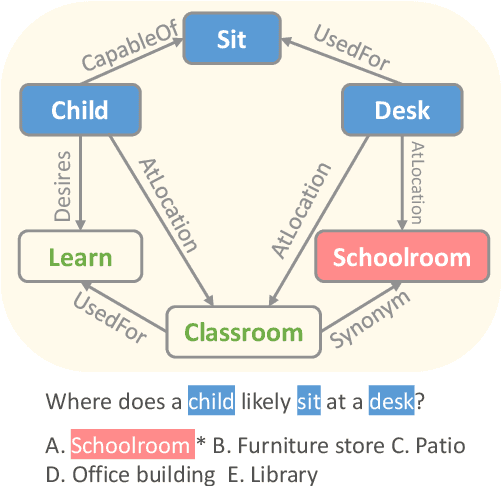

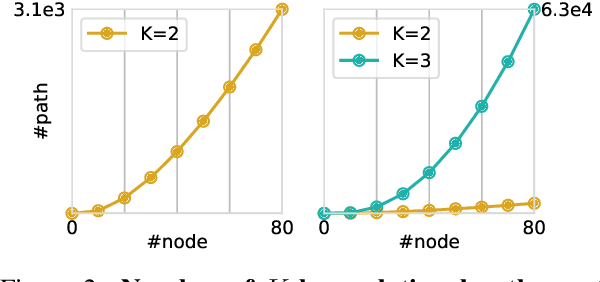

While fine-tuning pre-trained language models (PTLMs) has yielded strong results on a range of question answering (QA) benchmarks, these methods still suffer in cases when external knowledge are needed to infer the right answer. Existing work on augmenting QA models with external knowledge (e.g., knowledge graphs) either struggle to model multi-hop relations efficiently, or lack transparency into the model's prediction rationale. In this paper, we propose a novel knowledge-aware approach that equips PTLMs with a multi-hop relational reasoning module, named multi-hop graph relation networks (MHGRN). It performs multi-hop, multi-relational reasoning over subgraphs extracted from external knowledge graphs. The proposed reasoning module unifies path-based reasoning methods and graph neural networks to achieve better interpretability and scalability. We also empirically show its effectiveness and scalability on CommonsenseQA and OpenbookQA datasets, and interpret its behaviors with case studies. In particular, MHGRN achieves the state-of-the-art performance (76.5\% accuracy) on the CommonsenseQA official test set.