 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Omnidirectional Locomotion for a Salamander-Like Quadruped Robot
Nov 11, 2025Salamander-like quadruped robots are designed inspired by the skeletal structure of their biological counterparts. However, existing controllers cannot fully exploit these morphological features and largely rely on predefined gait patterns or joint trajectories, which prevents the generation of diverse and flexible locomotion and limits their applicability in real-world scenarios. In this paper, we propose a learning framework that enables the robot to acquire a diverse repertoire of omnidirectional gaits without reference motions. Each body part is controlled by a phase variable capable of forward and backward evolution, with a phase coverage reward to promote the exploration of the leg phase space. Additionally, morphological symmetry of the robot is incorporated via data augmentation, improving sample efficiency and enforcing both motion-level and task-level symmetry in learned behaviors. Extensive experiments show that the robot successfully acquires 22 omnidirectional gaits exhibiting both dynamic and symmetric movements, demonstrating the effectiveness of the proposed learning framework.
SMILE: SeMantic Ids Enhanced CoLd Item Representation for Click-through Rate Prediction in E-commerce SEarch
Oct 14, 2025



With the rise of modern search and recommendation platforms, insufficient collaborative information of cold-start items exacerbates the Matthew effect of existing platform items, challenging platform diversity and becoming a longstanding issue. Existing methods align items' side content with collaborative information to transfer collaborative signals from high-popularity items to cold-start items. However, these methods fail to account for the asymmetry between collaboration and content, nor the fine-grained differences among items. To address these issues, we propose SMILE, an item representation enhancement approach based on fused alignment of semantic IDs. Specifically, we use RQ-OPQ encoding to quantize item content and collaborative information, followed by a two-step alignment: RQ encoding transfers shared collaborative signals across items, while OPQ encoding learns differentiated information of items. Comprehensive offline experiments on large-scale industrial datasets demonstrate superiority of SMILE, and rigorous online A/B tests confirm statistically significant improvements: item CTR +1.66%, buyers +1.57%, and order volume +2.17%.
OneSug: The Unified End-to-End Generative Framework for E-commerce Query Suggestion
Jun 07, 2025



Query suggestion plays a crucial role in enhancing user experience in e-commerce search systems by providing relevant query recommendations that align with users' initial input. This module helps users navigate towards personalized preference needs and reduces typing effort, thereby improving search experience. Traditional query suggestion modules usually adopt multi-stage cascading architectures, for making a well trade-off between system response time and business conversion. But they often suffer from inefficiencies and suboptimal performance due to inconsistent optimization objectives across stages. To address these, we propose OneSug, the first end-to-end generative framework for e-commerce query suggestion. OneSug incorporates a prefix2query representation enhancement module to enrich prefixes using semantically and interactively related queries to bridge content and business characteristics, an encoder-decoder generative model that unifies the query suggestion process, and a reward-weighted ranking strategy with behavior-level weights to capture fine-grained user preferences. Extensive evaluations on large-scale industry datasets demonstrate OneSug's ability for effective and efficient query suggestion. Furthermore, OneSug has been successfully deployed for the entire traffic on the e-commerce search engine in Kuaishou platform for over 1 month, with statistically significant improvements in user top click position (-9.33%), CTR (+2.01%), Order (+2.04%), and Revenue (+1.69%) over the online multi-stage strategy, showing great potential in e-commercial conversion.
Retrieval Augmented Learning: A Retrial-based Large Language Model Self-Supervised Learning and Autonomous Knowledge Generation
May 02, 2025



The lack of domain-specific data in the pre-training of Large Language Models (LLMs) severely limits LLM-based decision systems in specialized applications, while post-training a model in the scenarios requires significant computational resources. In this paper, we present Retrial-Augmented Learning (RAL), a reward-free self-supervised learning framework for LLMs that operates without model training. By developing Retrieval-Augmented Generation (RAG) into a module for organizing intermediate data, we realized a three-stage autonomous knowledge generation of proposing a hypothesis, validating the hypothesis, and generating the knowledge. The method is evaluated in the LLM-PySC2 environment, a representative decision-making platform that combines sufficient complexity with domain-specific knowledge requirements. Experiments demonstrate that the proposed method effectively reduces hallucination by generating and utilizing validated knowledge, and increases decision-making performance at an extremely low cost. Meanwhile, the approach exhibits potential in out-of-distribution(OOD) tasks, robustness, and transferability, making it a cost-friendly but effective solution for decision-making problems and autonomous knowledge generation.
Reflection of Episodes: Learning to Play Game from Expert and Self Experiences
Feb 19, 2025



StarCraft II is a complex and dynamic real-time strategy (RTS) game environment, which is very suitable for artificial intelligence and reinforcement learning research. To address the problem of Large Language Model(LLM) learning in complex environments through self-reflection, we propose a Reflection of Episodes(ROE) framework based on expert experience and self-experience. This framework first obtains key information in the game through a keyframe selection method, then makes decisions based on expert experience and self-experience. After a game is completed, it reflects on the previous experience to obtain new self-experience. Finally, in the experiment, our method beat the robot under the Very Hard difficulty in TextStarCraft II. We analyze the data of the LLM in the process of the game in detail, verified its effectiveness.
LLM-PySC2: Starcraft II learning environment for Large Language Models
Nov 08, 2024



This paper introduces a new environment LLM-PySC2 (the Large Language Model StarCraft II Learning Environment), a platform derived from DeepMind's StarCraft II Learning Environment that serves to develop Large Language Models (LLMs) based decision-making methodologies. This environment is the first to offer the complete StarCraft II action space, multi-modal observation interfaces, and a structured game knowledge database, which are seamlessly connected with various LLMs to facilitate the research of LLMs-based decision-making. To further support multi-agent research, we developed an LLM collaborative framework that supports multi-agent concurrent queries and multi-agent communication. In our experiments, the LLM-PySC2 environment is adapted to be compatible with the StarCraft Multi-Agent Challenge (SMAC) task group and provided eight new scenarios focused on macro-decision abilities. We evaluated nine mainstream LLMs in the experiments, and results show that sufficient parameters are necessary for LLMs to make decisions, but improving reasoning ability does not directly lead to better decision-making outcomes. Our findings further indicate the importance of enabling large models to learn autonomously in the deployment environment through parameter training or train-free learning techniques. Ultimately, we expect that the LLM-PySC2 environment can promote research on learning methods for LLMs, helping LLM-based methods better adapt to task scenarios.
Critic PI2: Master Continuous Planning via Policy Improvement with Path Integrals and Deep Actor-Critic Reinforcement Learning
Nov 13, 2020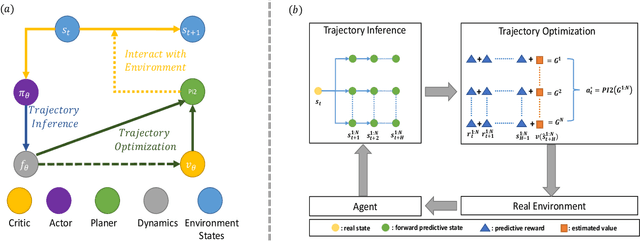
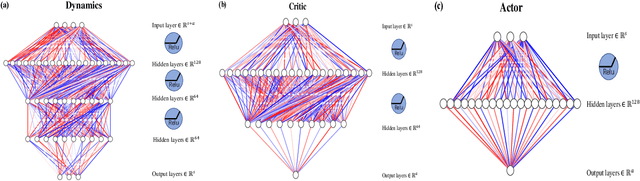
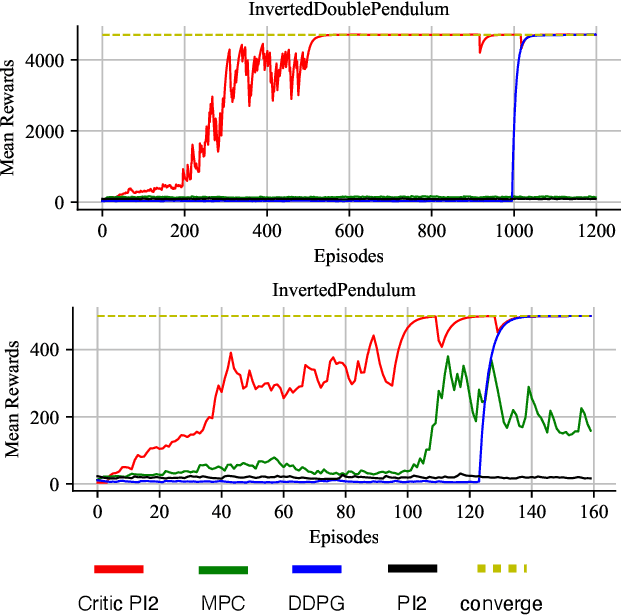
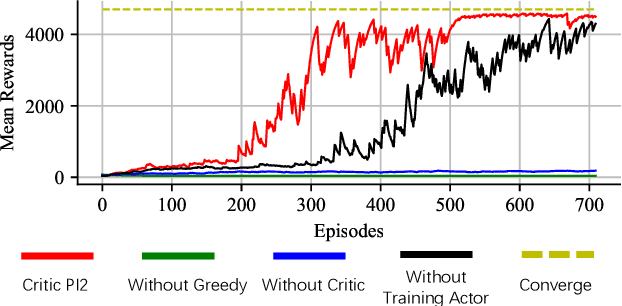
Constructing agents with planning capabilities has long been one of the main challenges in the pursuit of artificial intelligence. Tree-based planning methods from AlphaGo to Muzero have enjoyed huge success in discrete domains, such as chess and Go. Unfortunately, in real-world applications like robot control and inverted pendulum, whose action space is normally continuous, those tree-based planning techniques will be struggling. To address those limitations, in this paper, we present a novel model-based reinforcement learning frameworks called Critic PI2, which combines the benefits from trajectory optimization, deep actor-critic learning, and model-based reinforcement learning. Our method is evaluated for inverted pendulum models with applicability to many continuous control systems. Extensive experiments demonstrate that Critic PI2 achieved a new state of the art in a range of challenging continuous domains. Furthermore, we show that planning with a critic significantly increases the sample efficiency and real-time performance. Our work opens a new direction toward learning the components of a model-based planning system and how to use them.