 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Robust PCA: A Scalable Deep Unfolding Approach for High-Dimensional Outlier Detection
Oct 11, 2021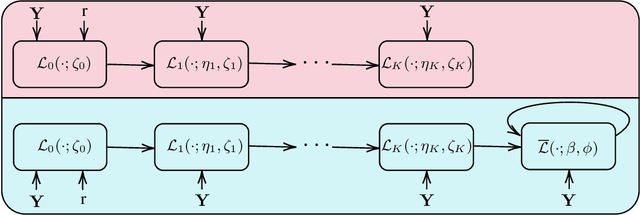

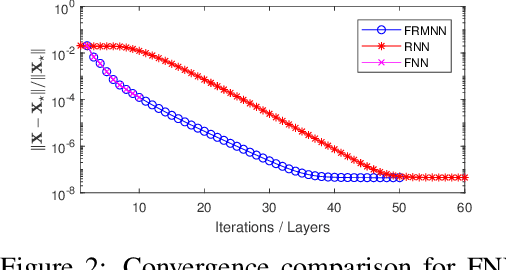
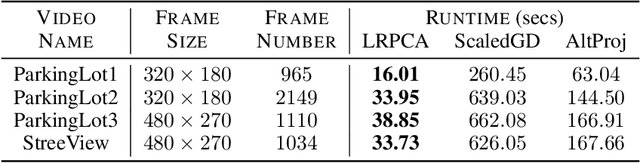
Robust principal component analysis (RPCA) is a critical tool in modern machine learning, which detects outliers in the task of low-rank matrix reconstruction. In this paper, we propose a scalable and learnable non-convex approach for high-dimensional RPCA problems, which we call Learned Robust PCA (LRPCA). LRPCA is highly efficient, and its free parameters can be effectively learned to optimize via deep unfolding. Moreover, we extend deep unfolding from finite iterations to infinite iterations via a novel feedforward-recurrent-mixed neural network model. We establish the recovery guarantee of LRPCA under mild assumptions for RPCA. Numerical experiments show that LRPCA outperforms the state-of-the-art RPCA algorithms, such as ScaledGD and AltProj, on both synthetic datasets and real-world applications.
Curvature-Aware Derivative-Free Optimization
Sep 27, 2021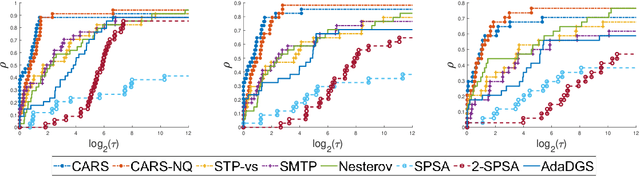
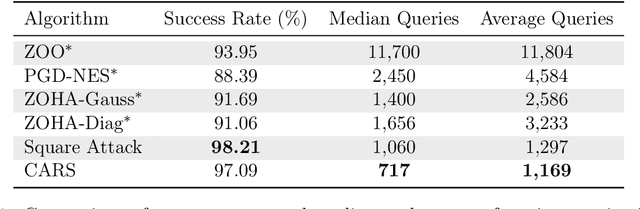
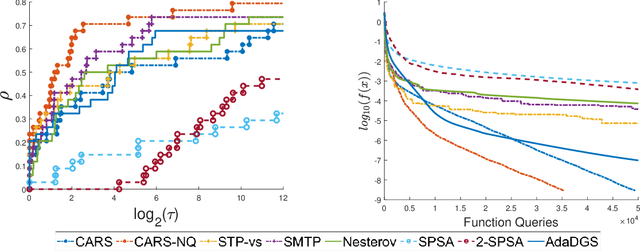

We propose a new line-search method, coined Curvature-Aware Random Search (CARS), for derivative-free optimization. CARS exploits approximate curvature information to estimate the optimal step-size given a search direction. We prove that for strongly convex objective functions, CARS converges linearly if the search direction is drawn from a distribution satisfying very mild conditions. We also explore a variant, CARS-NQ, which uses Numerical Quadrature instead of a Monte Carlo method when approximating curvature along the search direction. We show CARS-NQ is effective on highly non-convex problems of the form $f = f_{\mathrm{cvx}} + f_{\mathrm{osc}}$ where $f_{\mathrm{cvx}}$ is strongly convex and $f_{\mathrm{osc}}$ is rapidly oscillating. Experimental results show that CARS and CARS-NQ match or exceed the state-of-the-arts on benchmark problem sets.
Tighter Analysis of Alternating Stochastic Gradient Method for Stochastic Nested Problems
Jun 25, 2021
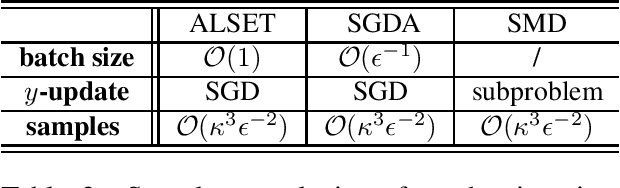
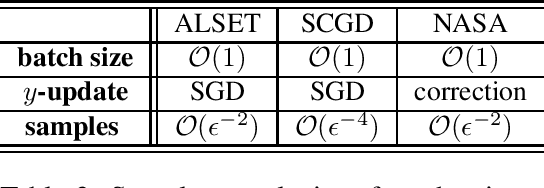
Stochastic nested optimization, including stochastic compositional, min-max and bilevel optimization, is gaining popularity in many machine learning applications. While the three problems share the nested structure, existing works often treat them separately, and thus develop problem-specific algorithms and their analyses. Among various exciting developments, simple SGD-type updates (potentially on multiple variables) are still prevalent in solving this class of nested problems, but they are believed to have slower convergence rate compared to that of the non-nested problems. This paper unifies several SGD-type updates for stochastic nested problems into a single SGD approach that we term ALternating Stochastic gradient dEscenT (ALSET) method. By leveraging the hidden smoothness of the problem, this paper presents a tighter analysis of ALSET for stochastic nested problems. Under the new analysis, to achieve an $\epsilon$-stationary point of the nested problem, it requires ${\cal O}(\epsilon^{-2})$ samples. Under certain regularity conditions, applying our results to stochastic compositional, min-max and reinforcement learning problems either improves or matches the best-known sample complexity in the respective cases. Our results explain why simple SGD-type algorithms in stochastic nested problems all work very well in practice without the need for further modifications.
Learn to Predict Equilibria via Fixed Point Networks
Jun 02, 2021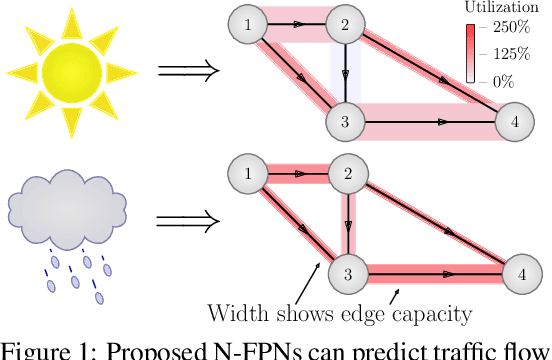

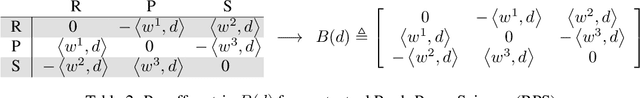
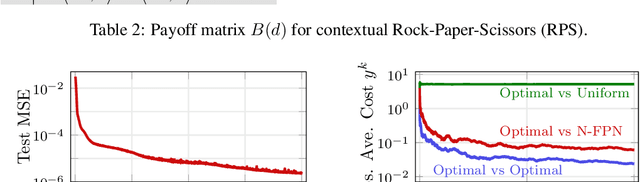
Systems of interacting agents can often be modeled as contextual games, where the context encodes additional information, beyond the control of any agent (e.g. weather for traffic and fiscal policy for market economies). In such systems, the most likely outcome is given by a Nash equilibrium. In many practical settings, only game equilibria are observed, while the optimal parameters for a game model are unknown. This work introduces Nash Fixed Point Networks (N-FPNs), a class of implicit-depth neural networks that output Nash equilibria of contextual games. The N-FPN architecture fuses data-driven modeling with provided constraints. Given equilibrium observations of a contextual game, N-FPN parameters are learnt to predict equilibria outcomes given only the context. We present an end-to-end training scheme for N-FPNs that is simple and memory efficient to implement with existing autodifferentiation tools. N-FPNs also exploit a novel constraint decoupling scheme to avoid costly projections. Provided numerical examples show the efficacy of N-FPNs on atomic and non-atomic games (e.g. traffic routing).
Accelerating Gossip SGD with Periodic Global Averaging
May 19, 2021
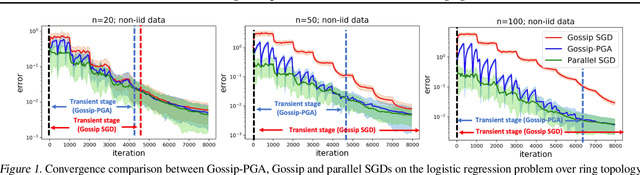

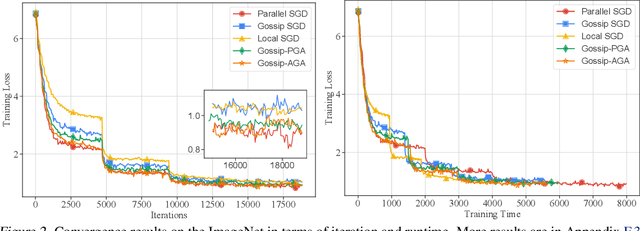
Communication overhead hinders the scalability of large-scale distributed training. Gossip SGD, where each node averages only with its neighbors, is more communication-efficient than the prevalent parallel SGD. However, its convergence rate is reversely proportional to quantity $1-\beta$ which measures the network connectivity. On large and sparse networks where $1-\beta \to 0$, Gossip SGD requires more iterations to converge, which offsets against its communication benefit. This paper introduces Gossip-PGA, which adds Periodic Global Averaging into Gossip SGD. Its transient stage, i.e., the iterations required to reach asymptotic linear speedup stage, improves from $\Omega(\beta^4 n^3/(1-\beta)^4)$ to $\Omega(\beta^4 n^3 H^4)$ for non-convex problems. The influence of network topology in Gossip-PGA can be controlled by the averaging period $H$. Its transient-stage complexity is also superior to Local SGD which has order $\Omega(n^3 H^4)$. Empirical results of large-scale training on image classification (ResNet50) and language modeling (BERT) validate our theoretical findings.
On Stochastic Moving-Average Estimators for Non-Convex Optimization
Apr 30, 2021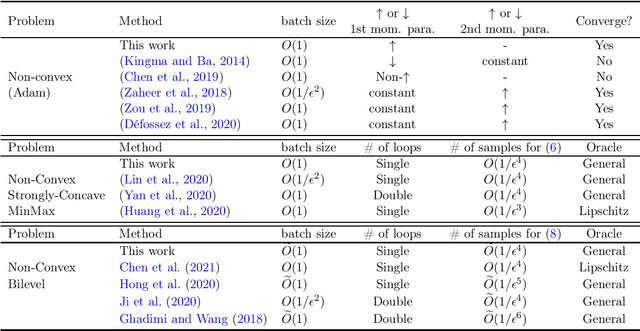
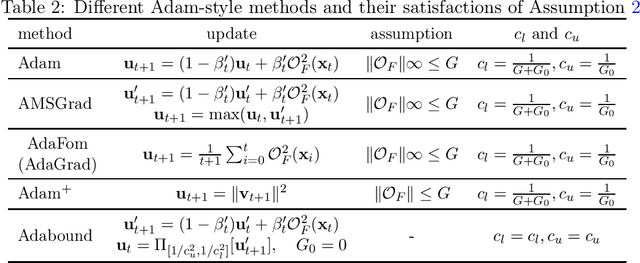
In this paper, we demonstrate the power of a widely used stochastic estimator based on moving average (SEMA) on a range of stochastic non-convex optimization problems, which only requires {\bf a general unbiased stochastic oracle}. We analyze various stochastic methods (existing or newly proposed) based on the {\bf variance recursion property} of SEMA for three families of non-convex optimization, namely standard stochastic non-convex minimization, stochastic non-convex strongly-concave min-max optimization, and stochastic bilevel optimization. Our contributions include: (i) for standard stochastic non-convex minimization, we present a simple and intuitive proof of convergence for a family Adam-style methods (including Adam) with an increasing or large "momentum" parameter for the first-order moment, which gives an alternative yet more natural way to guarantee Adam converge; (ii) for stochastic non-convex strongly-concave min-max optimization, we present a single-loop stochastic gradient descent ascent method based on the moving average estimators and establish its oracle complexity of $O(1/\epsilon^4)$ without using a large mini-batch size, addressing a gap in the literature; (iii) for stochastic bilevel optimization, we present a single-loop stochastic method based on the moving average estimators and establish its oracle complexity of $\widetilde O(1/\epsilon^4)$ without computing the inverse or SVD of the Hessian matrix, improving state-of-the-art results. For all these problems, we also establish a variance diminishing result for the used stochastic gradient estimators.
Feasibility-based Fixed Point Networks
Apr 29, 2021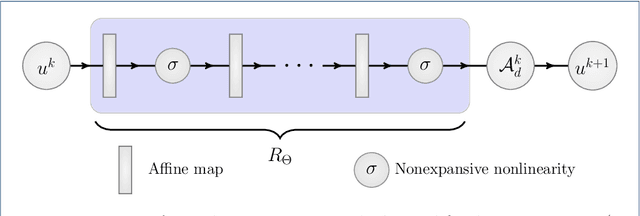
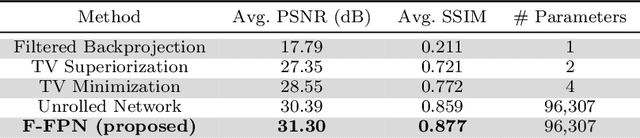

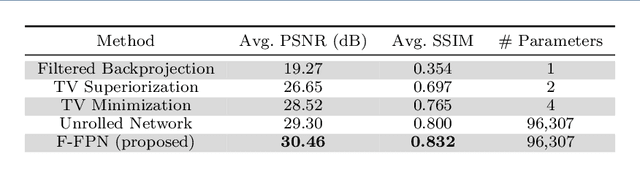
Inverse problems consist of recovering a signal from a collection of noisy measurements. These problems can often be cast as feasibility problems; however, additional regularization is typically necessary to ensure accurate and stable recovery with respect to data perturbations. Hand-chosen analytic regularization can yield desirable theoretical guarantees, but such approaches have limited effectiveness recovering signals due to their inability to leverage large amounts of available data. To this end, this work fuses data-driven regularization and convex feasibility in a theoretically sound manner. This is accomplished using feasibility-based fixed point networks (F-FPNs). Each F-FPN defines a collection of nonexpansive operators, each of which is the composition of a projection-based operator and a data-driven regularization operator. Fixed point iteration is used to compute fixed points of these operators, and weights of the operators are tuned so that the fixed points closely represent available data. Numerical examples demonstrate performance increases by F-FPNs when compared to standard TV-based recovery methods for CT reconstruction and a comparable neural network based on algorithm unrolling.
On the Comparison between Cyclic Sampling and Random Reshuffling
Apr 25, 2021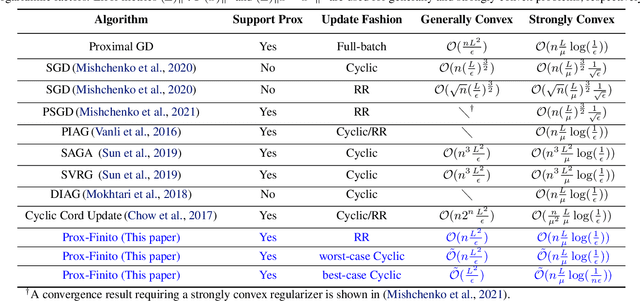
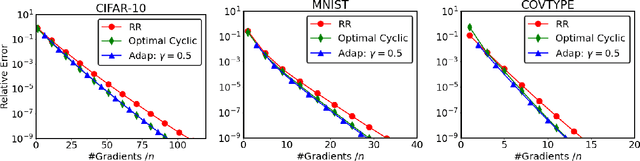
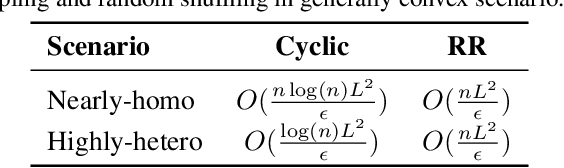

When applying a stochastic/incremental algorithm, one must choose the order to draw samples. Among the most popular approaches are cyclic sampling and random reshuffling, which are empirically faster and more cache-friendly than uniform-iid-sampling. Cyclic sampling draws the samples in a fixed, cyclic order, which is less robust than reshuffling the samples periodically. Indeed, existing works have established worst case convergence rates for cyclic sampling, which are generally worse than that of random reshuffling. In this paper, however, we found a certain cyclic order can be much faster than reshuffling and one can discover it at a low cost! Studying and comparing different sampling orders typically require new analytic techniques. In this paper, we introduce a norm, which is defined based on the sampling order, to measure the distance to solution. Applying this technique on proximal Finito/MISO algorithm allows us to identify the optimal fixed ordering, which can beat random reshuffling by a factor up to log(n)/n in terms of the best-known upper bounds. We also propose a strategy to discover the optimal fixed ordering numerically. The established rates are state-of-the-art compared to previous works.
DecentLaM: Decentralized Momentum SGD for Large-batch Deep Training
Apr 24, 2021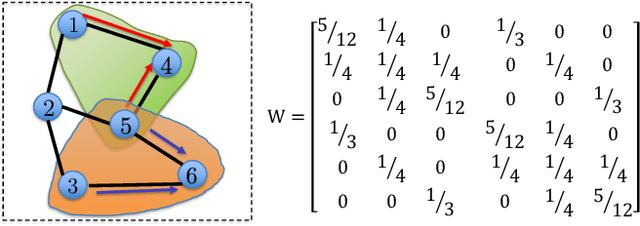
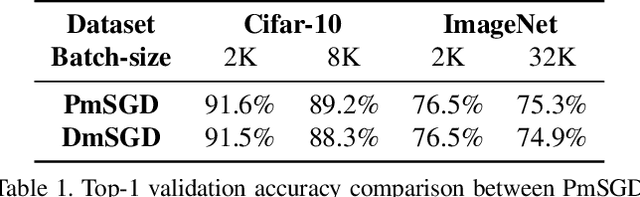
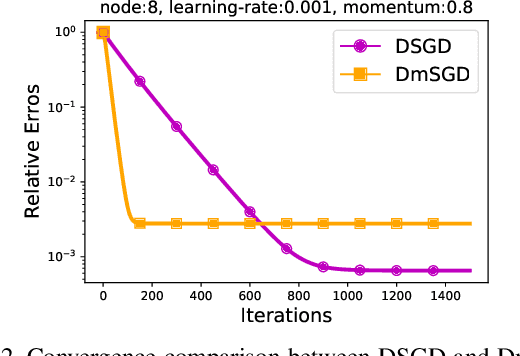
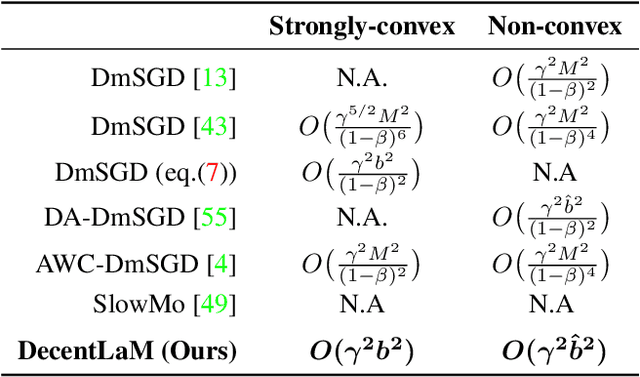
The scale of deep learning nowadays calls for efficient distributed training algorithms. Decentralized momentum SGD (DmSGD), in which each node averages only with its neighbors, is more communication efficient than vanilla Parallel momentum SGD that incurs global average across all computing nodes. On the other hand, the large-batch training has been demonstrated critical to achieve runtime speedup. This motivates us to investigate how DmSGD performs in the large-batch scenario. In this work, we find the momentum term can amplify the inconsistency bias in DmSGD. Such bias becomes more evident as batch-size grows large and hence results in severe performance degradation. We next propose DecentLaM, a novel decentralized large-batch momentum SGD to remove the momentum-incurred bias. The convergence rate for both non-convex and strongly-convex scenarios is established. Our theoretical results justify the superiority of DecentLaM to DmSGD especially in the large-batch scenario. Experimental results on a variety of computer vision tasks and models demonstrate that DecentLaM promises both efficient and high-quality training.
Learning to Optimize: A Primer and A Benchmark
Mar 23, 2021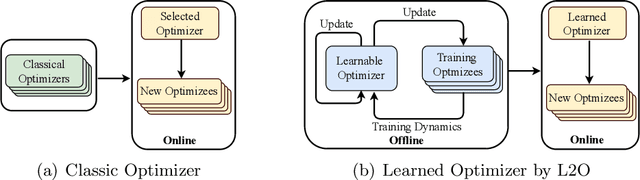
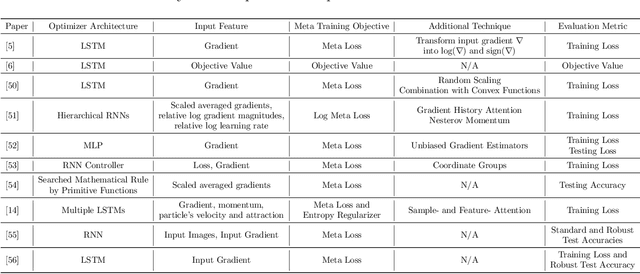
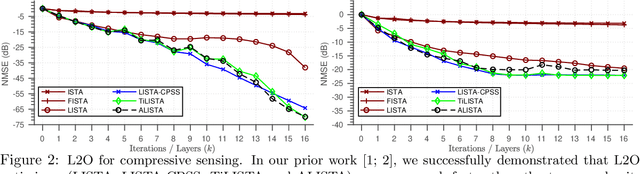
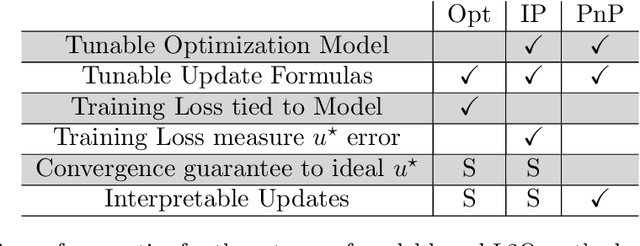
Learning to optimize (L2O) is an emerging approach that leverages machine learning to develop optimization methods, aiming at reducing the laborious iterations of hand engineering. It automates the design of an optimization method based on its performance on a set of training problems. This data-driven procedure generates methods that can efficiently solve problems similar to those in the training. In sharp contrast, the typical and traditional designs of optimization methods are theory-driven, so they obtain performance guarantees over the classes of problems specified by the theory. The difference makes L2O suitable for repeatedly solving a certain type of optimization problems over a specific distribution of data, while it typically fails on out-of-distribution problems. The practicality of L2O depends on the type of target optimization, the chosen architecture of the method to learn, and the training procedure. This new paradigm has motivated a community of researchers to explore L2O and report their findings. This article is poised to be the first comprehensive survey and benchmark of L2O for continuous optimization. We set up taxonomies, categorize existing works and research directions, present insights, and identify open challenges. We also benchmarked many existing L2O approaches on a few but representative optimization problems. For reproducible research and fair benchmarking purposes, we released our software implementation and data in the package Open-L2O at https://github.com/VITA-Group/Open-L2O.