 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification for Forward and Inverse Problems of PDEs via Latent Global Evolution
Feb 13, 2024Deep learning-based surrogate models have demonstrated remarkable advantages over classical solvers in terms of speed, often achieving speedups of 10 to 1000 times over traditional partial differential equation (PDE) solvers. However, a significant challenge hindering their widespread adoption in both scientific and industrial domains is the lack of understanding about their prediction uncertainties, particularly in scenarios that involve critical decision making. To address this limitation, we propose a method that integrates efficient and precise uncertainty quantification into a deep learning-based surrogate model. Our method, termed Latent Evolution of PDEs with Uncertainty Quantification (LE-PDE-UQ), endows deep learning-based surrogate models with robust and efficient uncertainty quantification capabilities for both forward and inverse problems. LE-PDE-UQ leverages latent vectors within a latent space to evolve both the system's state and its corresponding uncertainty estimation. The latent vectors are decoded to provide predictions for the system's state as well as estimates of its uncertainty. In extensive experiments, we demonstrate the accurate uncertainty quantification performance of our approach, surpassing that of strong baselines including deep ensembles, Bayesian neural network layers, and dropout. Our method excels at propagating uncertainty over extended auto-regressive rollouts, making it suitable for scenarios involving long-term predictions. Our code is available at: https://github.com/AI4Science-WestlakeU/le-pde-uq.
DeLLMa: A Framework for Decision Making Under Uncertainty with Large Language Models
Feb 04, 2024



Large language models (LLMs) are increasingly used across society, including in domains like business, engineering, and medicine. These fields often grapple with decision-making under uncertainty, a critical yet challenging task. In this paper, we show that directly prompting LLMs on these types of decision-making problems yields poor results, especially as the problem complexity increases. To overcome this limitation, we propose DeLLMa (Decision-making Large Language Model assistant), a framework designed to enhance decision-making accuracy in uncertain environments. DeLLMa involves a multi-step scaffolding procedure, drawing upon principles from decision theory and utility theory, to provide an optimal and human-auditable decision-making process. We validate our framework on decision-making environments involving real agriculture and finance data. Our results show that DeLLMa can significantly improve LLM decision-making performance, achieving up to a 40% increase in accuracy over competing methods.
LLM360: Towards Fully Transparent Open-Source LLMs
Dec 11, 2023



The recent surge in open-source Large Language Models (LLMs), such as LLaMA, Falcon, and Mistral, provides diverse options for AI practitioners and researchers. However, most LLMs have only released partial artifacts, such as the final model weights or inference code, and technical reports increasingly limit their scope to high-level design choices and surface statistics. These choices hinder progress in the field by degrading transparency into the training of LLMs and forcing teams to rediscover many details in the training process. We present LLM360, an initiative to fully open-source LLMs, which advocates for all training code and data, model checkpoints, and intermediate results to be made available to the community. The goal of LLM360 is to support open and collaborative AI research by making the end-to-end LLM training process transparent and reproducible by everyone. As a first step of LLM360, we release two 7B parameter LLMs pre-trained from scratch, Amber and CrystalCoder, including their training code, data, intermediate checkpoints, and analyses (at https://www.llm360.ai). We are committed to continually pushing the boundaries of LLMs through this open-source effort. More large-scale and stronger models are underway and will be released in the future.
Sample Efficient Reinforcement Learning from Human Feedback via Active Exploration
Dec 01, 2023Preference-based feedback is important for many applications in reinforcement learning where direct evaluation of a reward function is not feasible. A notable recent example arises in reinforcement learning from human feedback (RLHF) on large language models. For many applications of RLHF, the cost of acquiring the human feedback can be substantial. In this work, we take advantage of the fact that one can often choose contexts at which to obtain human feedback in order to most efficiently identify a good policy, and formalize this as an offline contextual dueling bandit problem. We give an upper-confidence-bound style algorithm for this problem and prove a polynomial worst-case regret bound. We then provide empirical confirmation in a synthetic setting that our approach outperforms existing methods. After, we extend the setting and methodology for practical use in RLHF training of large language models. Here, our method is able to reach better performance with fewer samples of human preferences than multiple baselines on three real-world datasets.
Making Scalable Meta Learning Practical
Oct 23, 2023



Despite its flexibility to learn diverse inductive biases in machine learning programs, meta learning (i.e., learning to learn) has long been recognized to suffer from poor scalability due to its tremendous compute/memory costs, training instability, and a lack of efficient distributed training support. In this work, we focus on making scalable meta learning practical by introducing SAMA, which combines advances in both implicit differentiation algorithms and systems. Specifically, SAMA is designed to flexibly support a broad range of adaptive optimizers in the base level of meta learning programs, while reducing computational burden by avoiding explicit computation of second-order gradient information, and exploiting efficient distributed training techniques implemented for first-order gradients. Evaluated on multiple large-scale meta learning benchmarks, SAMA showcases up to 1.7/4.8x increase in throughput and 2.0/3.8x decrease in memory consumption respectively on single-/multi-GPU setups compared to other baseline meta learning algorithms. Furthermore, we show that SAMA-based data optimization leads to consistent improvements in text classification accuracy with BERT and RoBERTa large language models, and achieves state-of-the-art results in both small- and large-scale data pruning on image classification tasks, demonstrating the practical applicability of scalable meta learning across language and vision domains.
SlimPajama-DC: Understanding Data Combinations for LLM Training
Sep 19, 2023



This paper aims to understand the impacts of various data combinations (e.g., web text, wikipedia, github, books) on the training of large language models using SlimPajama. SlimPajama is a rigorously deduplicated, multi-source dataset, which has been refined and further deduplicated to 627B tokens from the extensive 1.2T tokens RedPajama dataset contributed by Together. We've termed our research as SlimPajama-DC, an empirical analysis designed to uncover fundamental characteristics and best practices associated with employing SlimPajama in the training of large language models. During our research with SlimPajama, two pivotal observations emerged: (1) Global deduplication vs. local deduplication. We analyze and discuss how global (across different sources of datasets) and local (within the single source of dataset) deduplications affect the performance of trained models. (2) Proportions of high-quality/highly-deduplicated multi-source datasets in the combination. To study this, we construct six configurations of SlimPajama dataset and train individual ones using 1.3B Cerebras-GPT model with Alibi and SwiGLU. Our best configuration outperforms the 1.3B model trained on RedPajama using the same number of training tokens by a significant margin. All our 1.3B models are trained on Cerebras 16$\times$ CS-2 cluster with a total of 80 PFLOP/s in bf16 mixed precision. We further extend our discoveries (such as increasing data diversity is crucial after global deduplication) on a 7B model with large batch-size training. Our models and the separate SlimPajama-DC datasets are available at: https://huggingface.co/MBZUAI-LLM and https://huggingface.co/datasets/cerebras/SlimPajama-627B.
Kernelized Offline Contextual Dueling Bandits
Jul 21, 2023Preference-based feedback is important for many applications where direct evaluation of a reward function is not feasible. A notable recent example arises in reinforcement learning from human feedback on large language models. For many of these applications, the cost of acquiring the human feedback can be substantial or even prohibitive. In this work, we take advantage of the fact that often the agent can choose contexts at which to obtain human feedback in order to most efficiently identify a good policy, and introduce the offline contextual dueling bandit setting. We give an upper-confidence-bound style algorithm for this setting and prove a regret bound. We also give empirical confirmation that this method outperforms a similar strategy that uses uniformly sampled contexts.
Offline Imitation Learning with Suboptimal Demonstrations via Relaxed Distribution Matching
Mar 05, 2023



Offline imitation learning (IL) promises the ability to learn performant policies from pre-collected demonstrations without interactions with the environment. However, imitating behaviors fully offline typically requires numerous expert data. To tackle this issue, we study the setting where we have limited expert data and supplementary suboptimal data. In this case, a well-known issue is the distribution shift between the learned policy and the behavior policy that collects the offline data. Prior works mitigate this issue by regularizing the KL divergence between the stationary state-action distributions of the learned policy and the behavior policy. We argue that such constraints based on exact distribution matching can be overly conservative and hamper policy learning, especially when the imperfect offline data is highly suboptimal. To resolve this issue, we present RelaxDICE, which employs an asymmetrically-relaxed f-divergence for explicit support regularization. Specifically, instead of driving the learned policy to exactly match the behavior policy, we impose little penalty whenever the density ratio between their stationary state-action distributions is upper bounded by a constant. Note that such formulation leads to a nested min-max optimization problem, which causes instability in practice. RelaxDICE addresses this challenge by supporting a closed-form solution for the inner maximization problem. Extensive empirical study shows that our method significantly outperforms the best prior offline IL method in six standard continuous control environments with over 30% performance gain on average, across 22 settings where the imperfect dataset is highly suboptimal.
Near-optimal Policy Identification in Active Reinforcement Learning
Dec 19, 2022



Many real-world reinforcement learning tasks require control of complex dynamical systems that involve both costly data acquisition processes and large state spaces. In cases where the transition dynamics can be readily evaluated at specified states (e.g., via a simulator), agents can operate in what is often referred to as planning with a \emph{generative model}. We propose the AE-LSVI algorithm for best-policy identification, a novel variant of the kernelized least-squares value iteration (LSVI) algorithm that combines optimism with pessimism for active exploration (AE). AE-LSVI provably identifies a near-optimal policy \emph{uniformly} over an entire state space and achieves polynomial sample complexity guarantees that are independent of the number of states. When specialized to the recently introduced offline contextual Bayesian optimization setting, our algorithm achieves improved sample complexity bounds. Experimentally, we demonstrate that AE-LSVI outperforms other RL algorithms in a variety of environments when robustness to the initial state is required.
Uncertainty Quantification with Pre-trained Language Models: A Large-Scale Empirical Analysis
Oct 10, 2022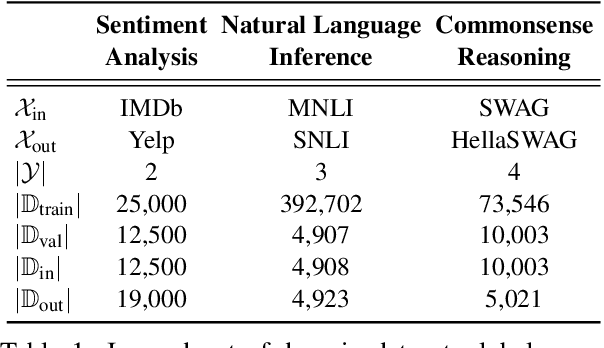
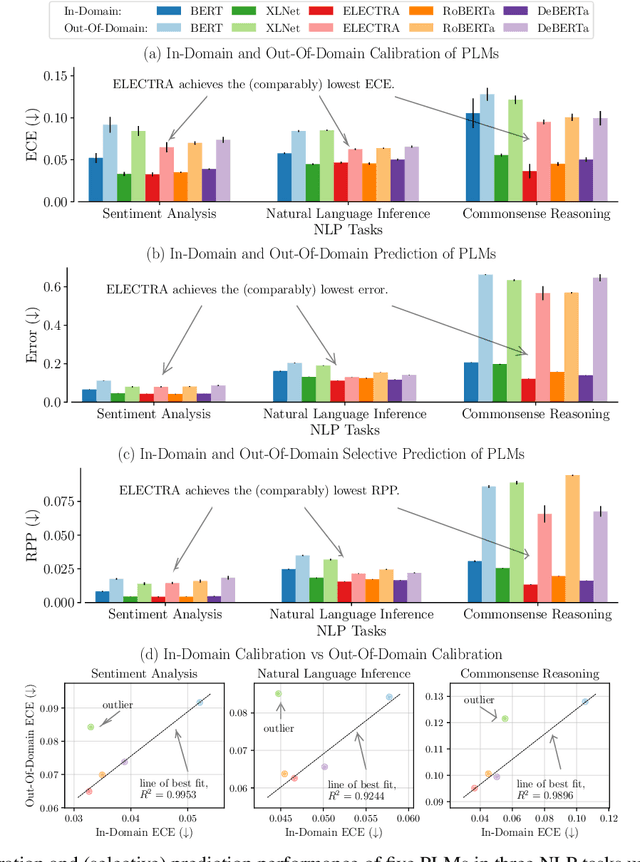
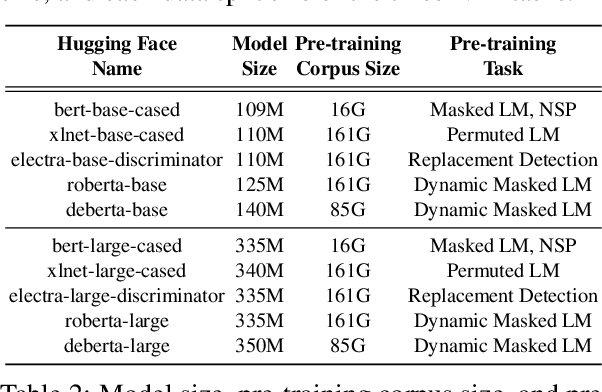
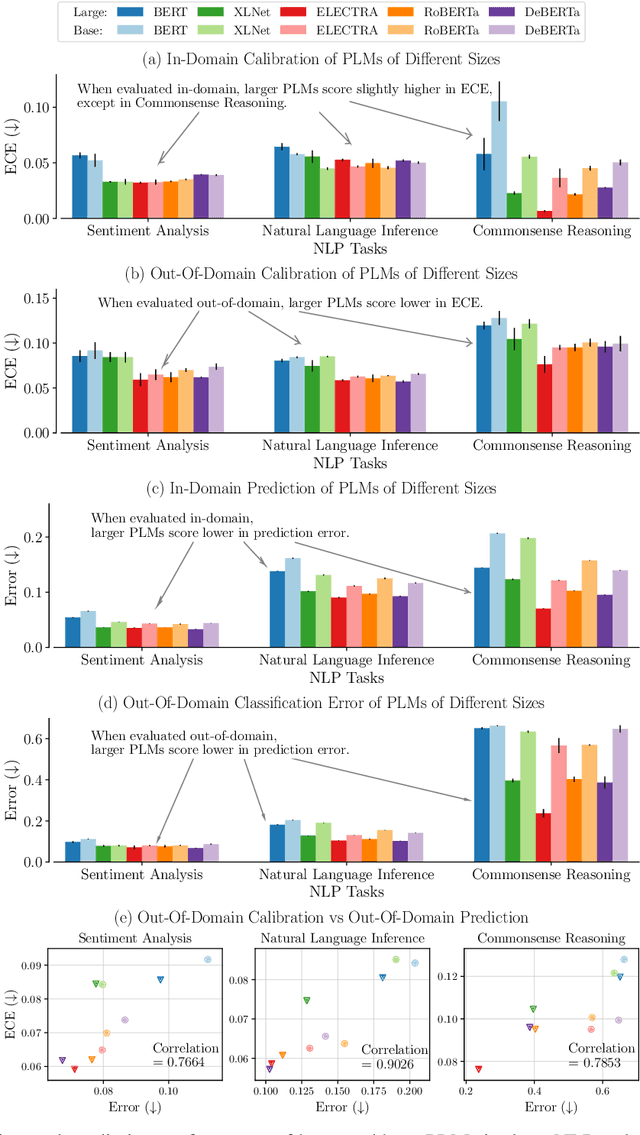
Pre-trained language models (PLMs) have gained increasing popularity due to their compelling prediction performance in diverse natural language processing (NLP) tasks. When formulating a PLM-based prediction pipeline for NLP tasks, it is also crucial for the pipeline to minimize the calibration error, especially in safety-critical applications. That is, the pipeline should reliably indicate when we can trust its predictions. In particular, there are various considerations behind the pipeline: (1) the choice and (2) the size of PLM, (3) the choice of uncertainty quantifier, (4) the choice of fine-tuning loss, and many more. Although prior work has looked into some of these considerations, they usually draw conclusions based on a limited scope of empirical studies. There still lacks a holistic analysis on how to compose a well-calibrated PLM-based prediction pipeline. To fill this void, we compare a wide range of popular options for each consideration based on three prevalent NLP classification tasks and the setting of domain shift. In response, we recommend the following: (1) use ELECTRA for PLM encoding, (2) use larger PLMs if possible, (3) use Temp Scaling as the uncertainty quantifier, and (4) use Focal Loss for fine-tuning.