 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable In-the-Wild Video Quality Assessment: a Database and a Language-Prompted Approach
May 22, 2023



The proliferation of in-the-wild videos has greatly expanded the Video Quality Assessment (VQA) problem. Unlike early definitions that usually focus on limited distortion types, VQA on in-the-wild videos is especially challenging as it could be affected by complicated factors, including various distortions and diverse contents. Though subjective studies have collected overall quality scores for these videos, how the abstract quality scores relate with specific factors is still obscure, hindering VQA methods from more concrete quality evaluations (e.g. sharpness of a video). To solve this problem, we collect over two million opinions on 4,543 in-the-wild videos on 13 dimensions of quality-related factors, including in-capture authentic distortions (e.g. motion blur, noise, flicker), errors introduced by compression and transmission, and higher-level experiences on semantic contents and aesthetic issues (e.g. composition, camera trajectory), to establish the multi-dimensional Maxwell database. Specifically, we ask the subjects to label among a positive, a negative, and a neural choice for each dimension. These explanation-level opinions allow us to measure the relationships between specific quality factors and abstract subjective quality ratings, and to benchmark different categories of VQA algorithms on each dimension, so as to more comprehensively analyze their strengths and weaknesses. Furthermore, we propose the MaxVQA, a language-prompted VQA approach that modifies vision-language foundation model CLIP to better capture important quality issues as observed in our analyses. The MaxVQA can jointly evaluate various specific quality factors and final quality scores with state-of-the-art accuracy on all dimensions, and superb generalization ability on existing datasets. Code and data available at \url{https://github.com/VQAssessment/MaxVQA}.
Towards Robust Text-Prompted Semantic Criterion for In-the-Wild Video Quality Assessment
Apr 28, 2023



The proliferation of videos collected during in-the-wild natural settings has pushed the development of effective Video Quality Assessment (VQA) methodologies. Contemporary supervised opinion-driven VQA strategies predominantly hinge on training from expensive human annotations for quality scores, which limited the scale and distribution of VQA datasets and consequently led to unsatisfactory generalization capacity of methods driven by these data. On the other hand, although several handcrafted zero-shot quality indices do not require training from human opinions, they are unable to account for the semantics of videos, rendering them ineffective in comprehending complex authentic distortions (e.g., white balance, exposure) and assessing the quality of semantic content within videos. To address these challenges, we introduce the text-prompted Semantic Affinity Quality Index (SAQI) and its localized version (SAQI-Local) using Contrastive Language-Image Pre-training (CLIP) to ascertain the affinity between textual prompts and visual features, facilitating a comprehensive examination of semantic quality concerns without the reliance on human quality annotations. By amalgamating SAQI with existing low-level metrics, we propose the unified Blind Video Quality Index (BVQI) and its improved version, BVQI-Local, which demonstrates unprecedented performance, surpassing existing zero-shot indices by at least 24\% on all datasets. Moreover, we devise an efficient fine-tuning scheme for BVQI-Local that jointly optimizes text prompts and final fusion weights, resulting in state-of-the-art performance and superior generalization ability in comparison to prevalent opinion-driven VQA methods. We conduct comprehensive analyses to investigate different quality concerns of distinct indices, demonstrating the effectiveness and rationality of our design.
MIPI 2023 Challenge on RGB+ToF Depth Completion: Methods and Results
Apr 27, 2023



Depth completion from RGB images and sparse Time-of-Flight (ToF) measurements is an important problem in computer vision and robotics. While traditional methods for depth completion have relied on stereo vision or structured light techniques, recent advances in deep learning have enabled more accurate and efficient completion of depth maps from RGB images and sparse ToF measurements. To evaluate the performance of different depth completion methods, we organized an RGB+sparse ToF depth completion competition. The competition aimed to encourage research in this area by providing a standardized dataset and evaluation metrics to compare the accuracy of different approaches. In this report, we present the results of the competition and analyze the strengths and weaknesses of the top-performing methods. We also discuss the implications of our findings for future research in RGB+sparse ToF depth completion. We hope that this competition and report will help to advance the state-of-the-art in this important area of research. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023.
MIPI 2023 Challenge on RGBW Fusion: Methods and Results
Apr 24, 2023



Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for an in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). With the success of the 1st MIPI Workshop@ECCV 2022, we introduce the second MIPI challenge, including four tracks focusing on novel image sensors and imaging algorithms. This paper summarizes and reviews the RGBW Joint Fusion and Denoise track on MIPI 2023. In total, 69 participants were successfully registered, and 4 teams submitted results in the final testing phase. The final results are evaluated using objective metrics, including PSNR, SSIM, LPIPS, and KLD. A detailed description of the top three models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023/.
MIPI 2023 Challenge on RGBW Remosaic: Methods and Results
Apr 20, 2023



Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for an in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). With the success of the 1st MIPI Workshop@ECCV 2022, we introduce the second MIPI challenge, including four tracks focusing on novel image sensors and imaging algorithms. This paper summarizes and reviews the RGBW Joint Remosaic and Denoise track on MIPI 2023. In total, 81 participants were successfully registered, and 4 teams submitted results in the final testing phase. The final results are evaluated using objective metrics, including PSNR, SSIM, LPIPS, and KLD. A detailed description of the top three models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023/.
Exploring Opinion-unaware Video Quality Assessment with Semantic Affinity Criterion
Feb 26, 2023



Recent learning-based video quality assessment (VQA) algorithms are expensive to implement due to the cost of data collection of human quality opinions, and are less robust across various scenarios due to the biases of these opinions. This motivates our exploration on opinion-unaware (a.k.a zero-shot) VQA approaches. Existing approaches only considers low-level naturalness in spatial or temporal domain, without considering impacts from high-level semantics. In this work, we introduce an explicit semantic affinity index for opinion-unaware VQA using text-prompts in the contrastive language-image pre-training (CLIP) model. We also aggregate it with different traditional low-level naturalness indexes through gaussian normalization and sigmoid rescaling strategies. Composed of aggregated semantic and technical metrics, the proposed Blind Unified Opinion-Unaware Video Quality Index via Semantic and Technical Metric Aggregation (BUONA-VISTA) outperforms existing opinion-unaware VQA methods by at least 20% improvements, and is more robust than opinion-aware approaches.
Disentangling Aesthetic and Technical Effects for Video Quality Assessment of User Generated Content
Nov 16, 2022User-generated-content (UGC) videos have dominated the Internet during recent years. While it is well-recognized that the perceptual quality of these videos can be affected by diverse factors, few existing methods explicitly explore the effects of different factors in video quality assessment (VQA) for UGC videos, i.e. the UGC-VQA problem. In this work, we make the first attempt to disentangle the effects of aesthetic quality issues and technical quality issues risen by the complicated video generation processes in the UGC-VQA problem. To overcome the absence of respective supervisions during disentanglement, we propose the Limited View Biased Supervisions (LVBS) scheme where two separate evaluators are trained with decomposed views specifically designed for each issue. Composed of an Aesthetic Quality Evaluator (AQE) and a Technical Quality Evaluator (TQE) under the LVBS scheme, the proposed Disentangled Objective Video Quality Evaluator (DOVER) reach excellent performance (0.91 SRCC for KoNViD-1k, 0.89 SRCC for LSVQ, 0.88 SRCC for YouTube-UGC) in the UGC-VQA problem. More importantly, our blind subjective studies prove that the separate evaluators in DOVER can effectively match human perception on respective disentangled quality issues. Codes and demos are released in https://github.com/teowu/dover.
Neighbourhood Representative Sampling for Efficient End-to-end Video Quality Assessment
Oct 11, 2022
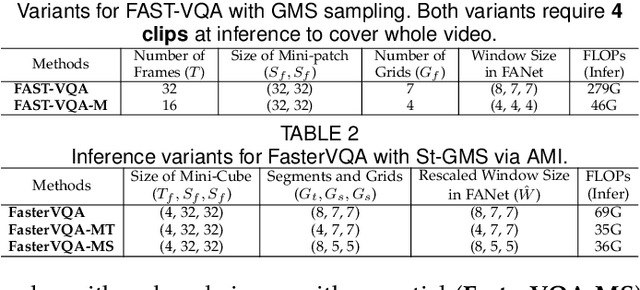
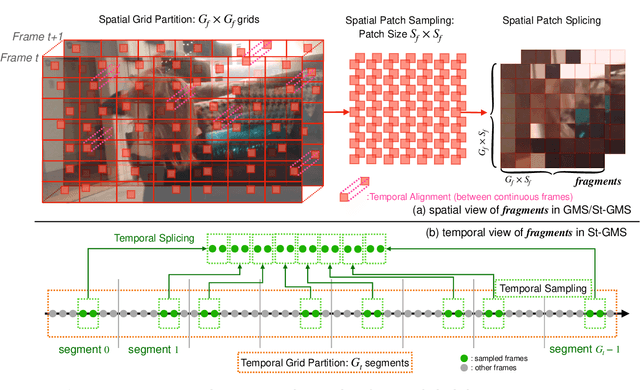
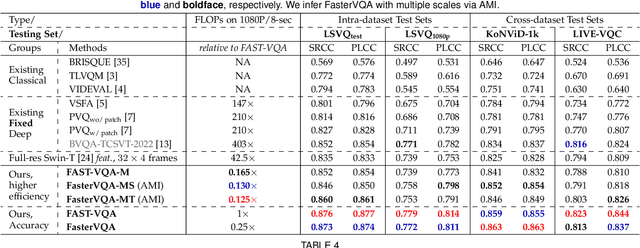
The increased resolution of real-world videos presents a dilemma between efficiency and accuracy for deep Video Quality Assessment (VQA). On the one hand, keeping the original resolution will lead to unacceptable computational costs. On the other hand, existing practices, such as resizing and cropping, will change the quality of original videos due to the loss of details and contents, and are therefore harmful to quality assessment. With the obtained insight from the study of spatial-temporal redundancy in the human visual system and visual coding theory, we observe that quality information around a neighbourhood is typically similar, motivating us to investigate an effective quality-sensitive neighbourhood representatives scheme for VQA. In this work, we propose a unified scheme, spatial-temporal grid mini-cube sampling (St-GMS) to get a novel type of sample, named fragments. Full-resolution videos are first divided into mini-cubes with preset spatial-temporal grids, then the temporal-aligned quality representatives are sampled to compose the fragments that serve as inputs for VQA. In addition, we design the Fragment Attention Network (FANet), a network architecture tailored specifically for fragments. With fragments and FANet, the proposed efficient end-to-end FAST-VQA and FasterVQA achieve significantly better performance than existing approaches on all VQA benchmarks while requiring only 1/1612 FLOPs compared to the current state-of-the-art. Codes, models and demos are available at https://github.com/timothyhtimothy/FAST-VQA-and-FasterVQA.
MIPI 2022 Challenge on RGBW Sensor Fusion: Dataset and Report
Sep 27, 2022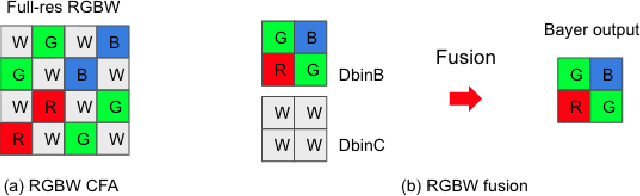
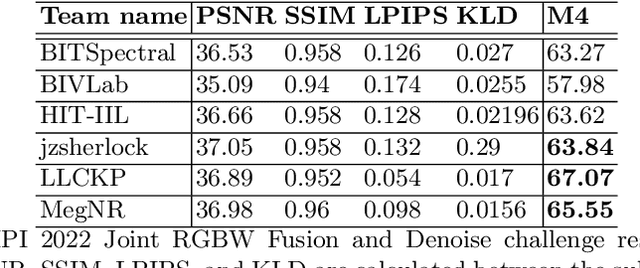


Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge, including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGBW Joint Fusion and Denoise, one of the five tracks, working on the fusion of binning-mode RGBW to Bayer, is introduced. The participants were provided with a new dataset including 70 (training) and 15 (validation) scenes of high-quality RGBW and Bayer pairs. In addition, for each scene, RGBW of different noise levels was provided at 24dB and 42dB. All the data were captured using an RGBW sensor in both outdoor and indoor conditions. The final results are evaluated using objective metrics, including PSNR, SSIM}, LPIPS, and KLD. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
MIPI 2022 Challenge on RGBW Sensor Re-mosaic: Dataset and Report
Sep 15, 2022


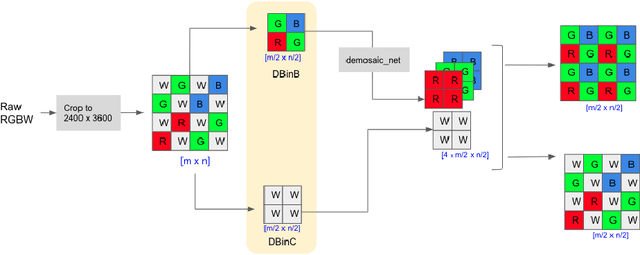
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGBW Joint Remosaic and Denoise, one of the five tracks, working on the interpolation of RGBW CFA to Bayer at full resolution, is introduced. The participants were provided with a new dataset including 70 (training) and 15 (validation) scenes of high-quality RGBW and Bayer pairs. In addition, for each scene, RGBW of different noise levels was provided at 0dB, 24dB, and 42dB. All the data were captured using an RGBW sensor in both outdoor and indoor conditions. The final results are evaluated using objective metrics including PSNR, SSIM, LPIPS, and KLD. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.