 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBGR: Multi-Business Prediction for Generative Recommendation at Meituan
Apr 03, 2026Generative recommendation (GR) has recently emerged as a promising paradigm for industrial recommendations. GR leverages Semantic IDs (SIDs) to reduce the encoding-decoding space and employs the Next Token Prediction (NTP) framework to explore scaling laws. However, existing GR methods suffer from two critical issues: (1) a \textbf{seesaw phenomenon} in multi-business scenarios arises due to NTP's inability to capture complex cross-business behavioral patterns; and (2) a unified SID space causes \textbf{representation confusion} by failing to distinguish distinct semantic information across businesses. To address these issues, we propose Multi-Business Generative Recommendation (MBGR), the first GR framework tailored for multi-business scenarios. Our framework comprises three key components. First, we design a Business-aware semantic ID (BID) module that preserves semantic integrity via domain-aware tokenization. Then, we introduce a Multi-Business Prediction (MBP) structure to provide business-specific prediction capabilities. Furthermore, we develop a Label Dynamic Routing (LDR) module that transforms sparse multi-business labels into dense labels to further enhance the multi-business generation capability. Extensive offline and online experiments on Meituan's food delivery platform validate MBGR's effectiveness, and we have successfully deployed it in production.
NLGR: Utilizing Neighbor Lists for Generative Rerank in Personalized Recommendation Systems
Feb 10, 2025



Reranking plays a crucial role in modern multi-stage recommender systems by rearranging the initial ranking list. Due to the inherent challenges of combinatorial search spaces, some current research adopts an evaluator-generator paradigm, with a generator generating feasible sequences and an evaluator selecting the best sequence based on the estimated list utility. However, these methods still face two issues. Firstly, due to the goal inconsistency problem between the evaluator and generator, the generator tends to fit the local optimal solution of exposure distribution rather than combinatorial space optimization. Secondly, the strategy of generating target items one by one is difficult to achieve optimality because it ignores the information of subsequent items. To address these issues, we propose a utilizing Neighbor Lists model for Generative Reranking (NLGR), which aims to improve the performance of the generator in the combinatorial space. NLGR follows the evaluator-generator paradigm and improves the generator's training and generating methods. Specifically, we use neighbor lists in combination space to enhance the training process, making the generator perceive the relative scores and find the optimization direction. Furthermore, we propose a novel sampling-based non-autoregressive generation method, which allows the generator to jump flexibly from the current list to any neighbor list. Extensive experiments on public and industrial datasets validate NLGR's effectiveness and we have successfully deployed NLGR on the Meituan food delivery platform.
Complex Scene Classification of PolSAR Imagery based on a Self-paced Learning Approach
Mar 18, 2019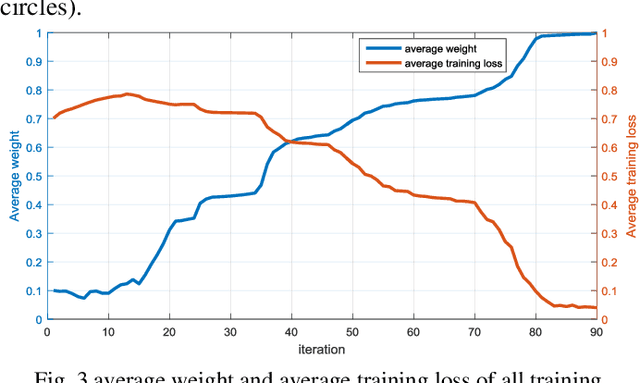
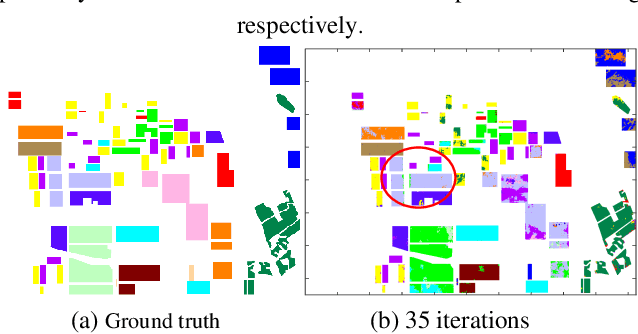
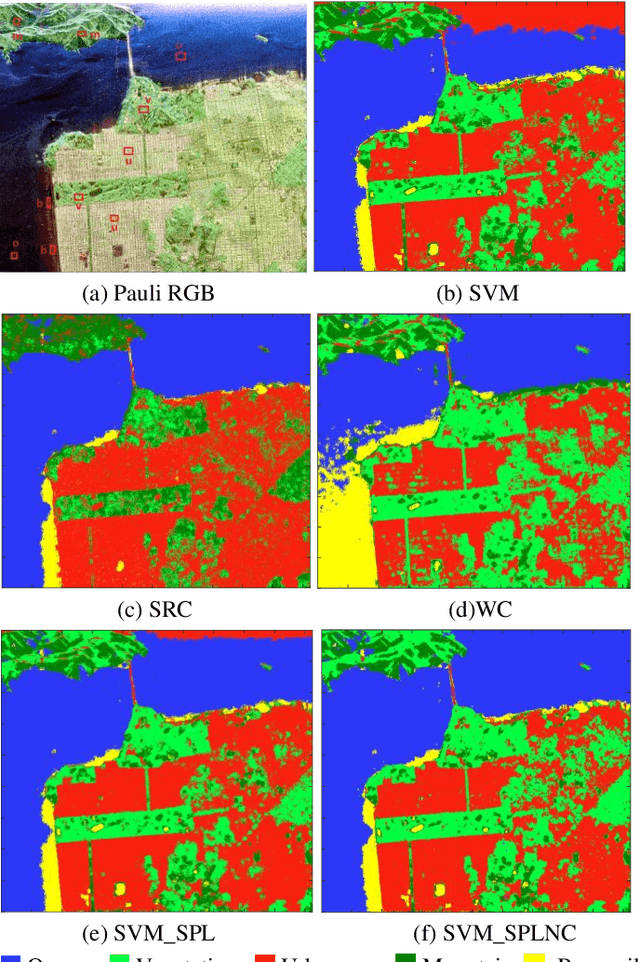
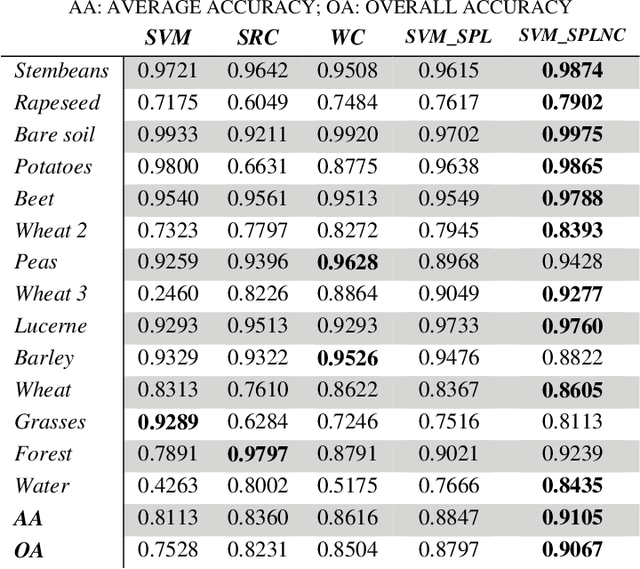
Existing polarimetric synthetic aperture radar (PolSAR) image classification methods cannot achieve satisfactory performance on complex scenes characterized by several types of land cover with significant levels of noise or similar scattering properties across land cover types. Hence, we propose a supervised classification method aimed at constructing a classifier based on self-paced learning (SPL). SPL has been demonstrated to be effective at dealing with complex data while providing classifier. In this paper, a novel Support Vector Machine (SVM) algorithm based on SPL with neighborhood constraints (SVM_SPLNC) is proposed. The proposed method leverages the easiest samples first to obtain an initial parameter vector. Then, more complex samples are gradually incorporated to update the parameter vector iteratively. Moreover, neighborhood constraints are introduced during the training process to further improve performance. Experimental results on three real PolSAR images show that the proposed method performs well on complex scenes.