 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-efficient Segmentation of High-resolution Volumetric MicroCT Images
May 31, 2022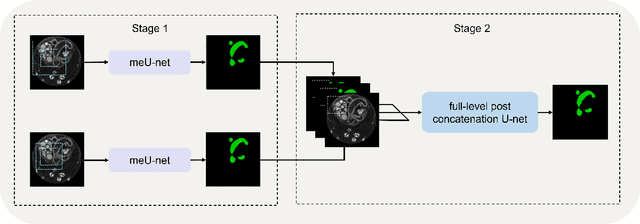
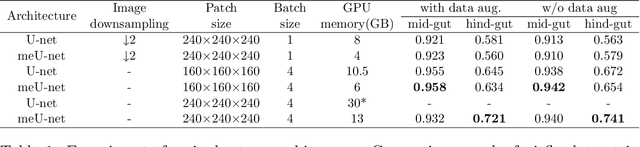
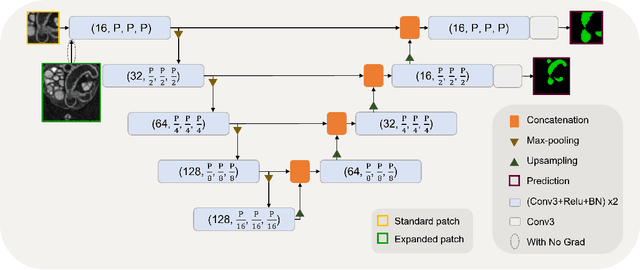

In recent years, 3D convolutional neural networks have become the dominant approach for volumetric medical image segmentation. However, compared to their 2D counterparts, 3D networks introduce substantially more training parameters and higher requirement for the GPU memory. This has become a major limiting factor for designing and training 3D networks for high-resolution volumetric images. In this work, we propose a novel memory-efficient network architecture for 3D high-resolution image segmentation. The network incorporates both global and local features via a two-stage U-net-based cascaded framework and at the first stage, a memory-efficient U-net (meU-net) is developed. The features learnt at the two stages are connected via post-concatenation, which further improves the information flow. The proposed segmentation method is evaluated on an ultra high-resolution microCT dataset with typically 250 million voxels per volume. Experiments show that it outperforms state-of-the-art 3D segmentation methods in terms of both segmentation accuracy and memory efficiency.
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021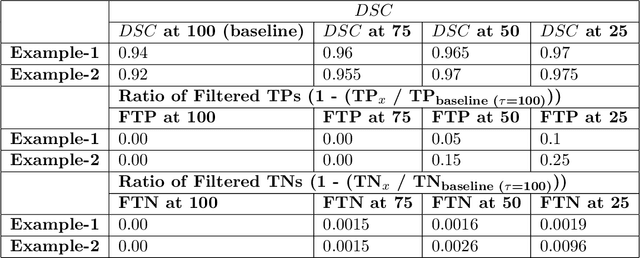
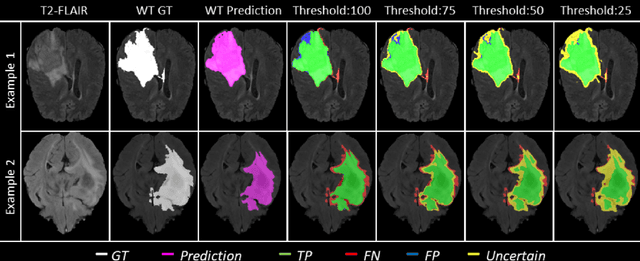
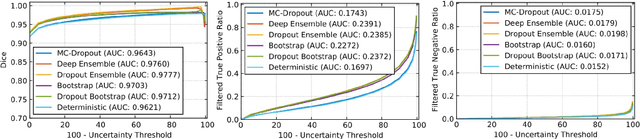
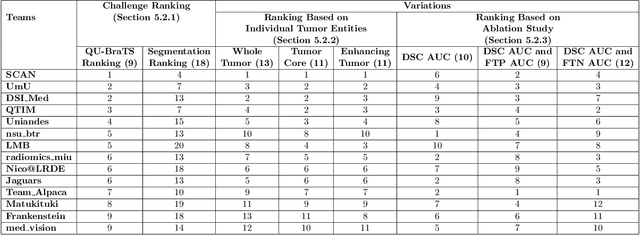
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
Causality-inspired Single-source Domain Generalization for Medical Image Segmentation
Dec 06, 2021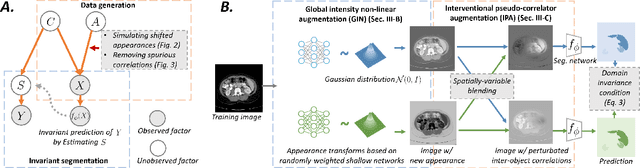
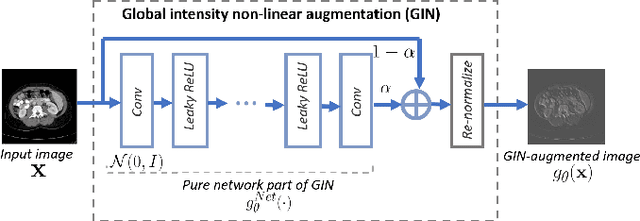
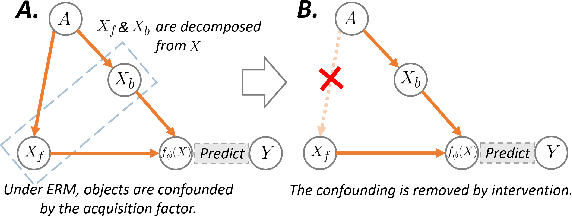
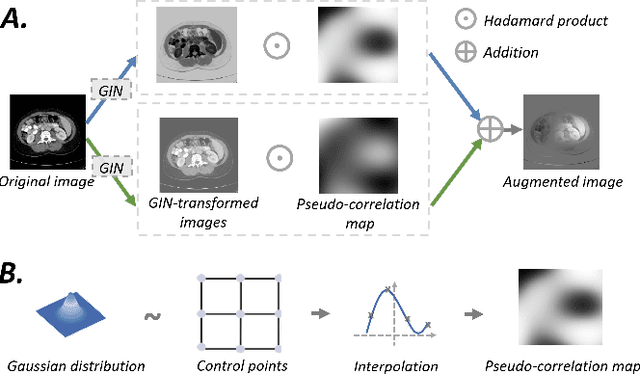
Deep learning models usually suffer from domain shift issues, where models trained on one source domain do not generalize well to other unseen domains. In this work, we investigate the single-source domain generalization problem: training a deep network that is robust to unseen domains, under the condition that training data is only available from one source domain, which is common in medical imaging applications. We tackle this problem in the context of cross-domain medical image segmentation. Under this scenario, domain shifts are mainly caused by different acquisition processes. We propose a simple causality-inspired data augmentation approach to expose a segmentation model to synthesized domain-shifted training examples. Specifically, 1) to make the deep model robust to discrepancies in image intensities and textures, we employ a family of randomly-weighted shallow networks. They augment training images using diverse appearance transformations. 2) Further we show that spurious correlations among objects in an image are detrimental to domain robustness. These correlations might be taken by the network as domain-specific clues for making predictions, and they may break on unseen domains. We remove these spurious correlations via causal intervention. This is achieved by resampling the appearances of potentially correlated objects independently. The proposed approach is validated on three cross-domain segmentation tasks: cross-modality (CT-MRI) abdominal image segmentation, cross-sequence (bSSFP-LGE) cardiac MRI segmentation, and cross-center prostate MRI segmentation. The proposed approach yields consistent performance gains compared with competitive methods when tested on unseen domains.
DeepMCAT: Large-Scale Deep Clustering for Medical Image Categorization
Sep 30, 2021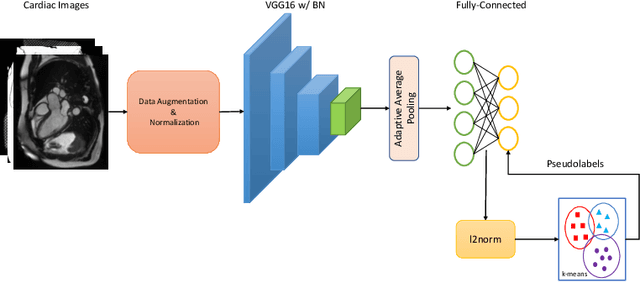

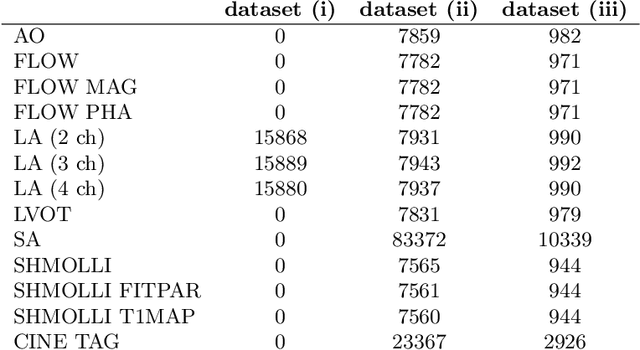
In recent years, the research landscape of machine learning in medical imaging has changed drastically from supervised to semi-, weakly- or unsupervised methods. This is mainly due to the fact that ground-truth labels are time-consuming and expensive to obtain manually. Generating labels from patient metadata might be feasible but it suffers from user-originated errors which introduce biases. In this work, we propose an unsupervised approach for automatically clustering and categorizing large-scale medical image datasets, with a focus on cardiac MR images, and without using any labels. We investigated the end-to-end training using both class-balanced and imbalanced large-scale datasets. Our method was able to create clusters with high purity and achieved over 0.99 cluster purity on these datasets. The results demonstrate the potential of the proposed method for categorizing unstructured large medical databases, such as organizing clinical PACS systems in hospitals.
Enhancing MR Image Segmentation with Realistic Adversarial Data Augmentation
Aug 07, 2021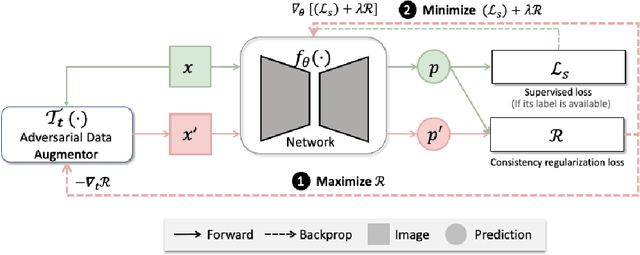

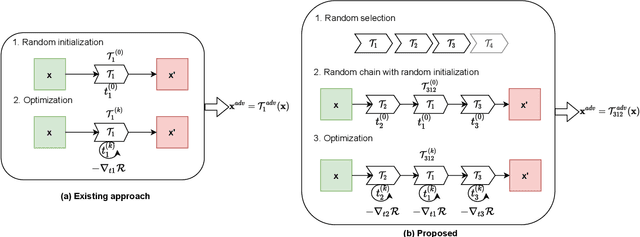
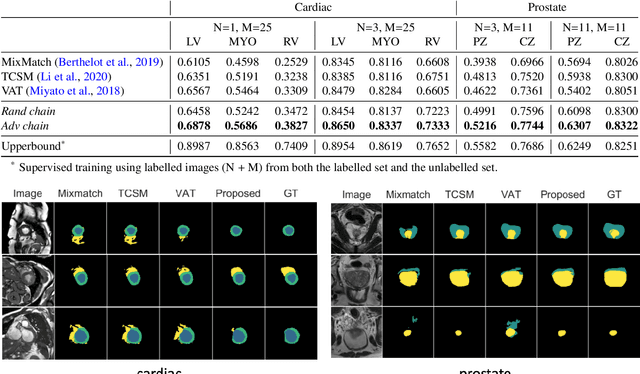
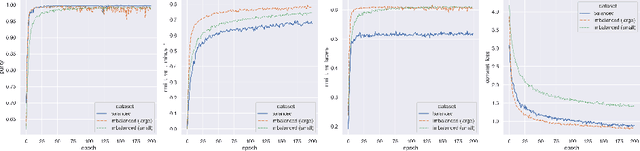
The success of neural networks on medical image segmentation tasks typically relies on large labeled datasets for model training. However, acquiring and manually labeling a large medical image set is resource-intensive, expensive, and sometimes impractical due to data sharing and privacy issues. To address this challenge, we propose an adversarial data augmentation approach to improve the efficiency in utilizing training data and to enlarge the dataset via simulated but realistic transformations. Specifically, we present a generic task-driven learning framework, which jointly optimizes a data augmentation model and a segmentation network during training, generating informative examples to enhance network generalizability for the downstream task. The data augmentation model utilizes a set of photometric and geometric image transformations and chains them to simulate realistic complex imaging variations that could exist in magnetic resonance (MR) imaging. The proposed adversarial data augmentation does not rely on generative networks and can be used as a plug-in module in general segmentation networks. It is computationally efficient and applicable for both supervised and semi-supervised learning. We analyze and evaluate the method on two MR image segmentation tasks: cardiac segmentation and prostate segmentation. Results show that the proposed approach can alleviate the need for labeled data while improving model generalization ability, indicating its practical value in medical imaging applications.
Joint Semi-supervised 3D Super-Resolution and Segmentation with Mixed Adversarial Gaussian Domain Adaptation
Jul 16, 2021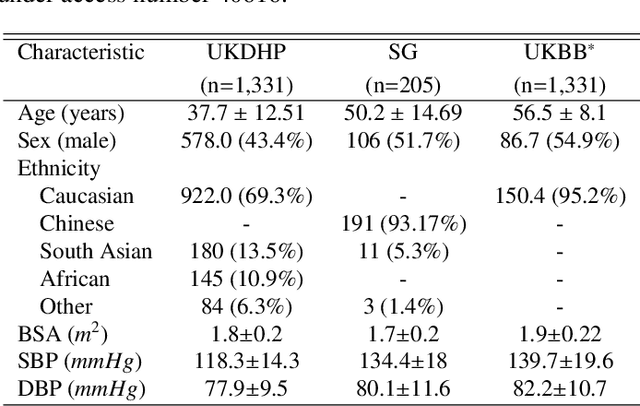
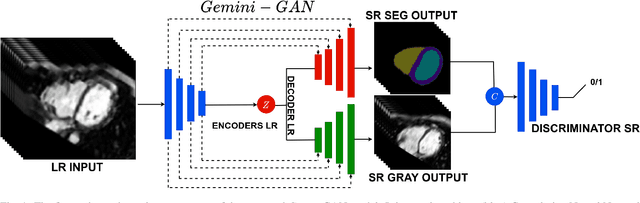
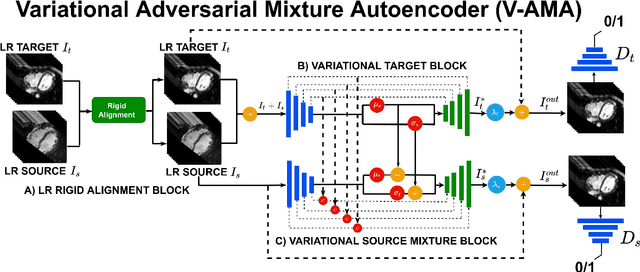

Optimising the analysis of cardiac structure and function requires accurate 3D representations of shape and motion. However, techniques such as cardiac magnetic resonance imaging are conventionally limited to acquiring contiguous cross-sectional slices with low through-plane resolution and potential inter-slice spatial misalignment. Super-resolution in medical imaging aims to increase the resolution of images but is conventionally trained on features from low resolution datasets and does not super-resolve corresponding segmentations. Here we propose a semi-supervised multi-task generative adversarial network (Gemini-GAN) that performs joint super-resolution of the images and their labels using a ground truth of high resolution 3D cines and segmentations, while an unsupervised variational adversarial mixture autoencoder (V-AMA) is used for continuous domain adaptation. Our proposed approach is extensively evaluated on two transnational multi-ethnic populations of 1,331 and 205 adults respectively, delivering an improvement on state of the art methods in terms of Dice index, peak signal to noise ratio, and structural similarity index measure. This framework also exceeds the performance of state of the art generative domain adaptation models on external validation (Dice index 0.81 vs 0.74 for the left ventricle). This demonstrates how joint super-resolution and segmentation, trained on 3D ground-truth data with cross-domain generalization, enables robust precision phenotyping in diverse populations.
Joint Motion Correction and Super Resolution for Cardiac Segmentation via Latent Optimisation
Jul 08, 2021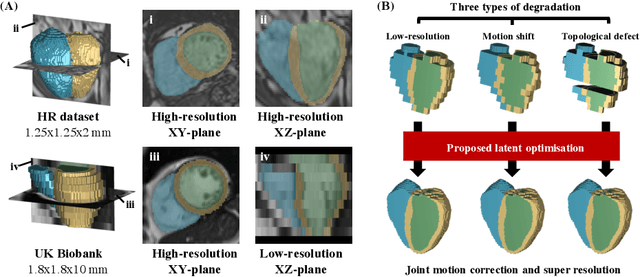

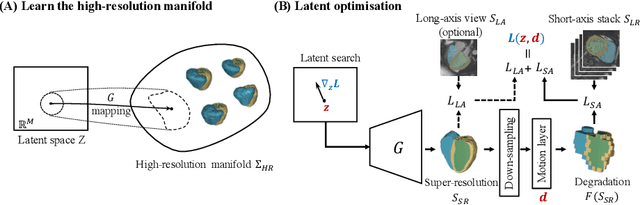
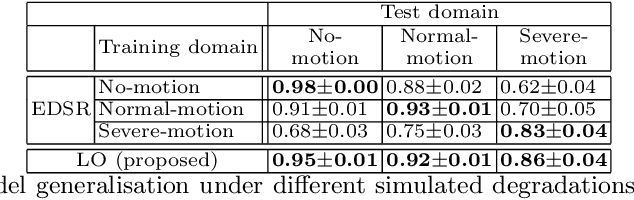
In cardiac magnetic resonance (CMR) imaging, a 3D high-resolution segmentation of the heart is essential for detailed description of its anatomical structures. However, due to the limit of acquisition duration and respiratory/cardiac motion, stacks of multi-slice 2D images are acquired in clinical routine. The segmentation of these images provides a low-resolution representation of cardiac anatomy, which may contain artefacts caused by motion. Here we propose a novel latent optimisation framework that jointly performs motion correction and super resolution for cardiac image segmentations. Given a low-resolution segmentation as input, the framework accounts for inter-slice motion in cardiac MR imaging and super-resolves the input into a high-resolution segmentation consistent with input. A multi-view loss is incorporated to leverage information from both short-axis view and long-axis view of cardiac imaging. To solve the inverse problem, iterative optimisation is performed in a latent space, which ensures the anatomical plausibility. This alleviates the need of paired low-resolution and high-resolution images for supervised learning. Experiments on two cardiac MR datasets show that the proposed framework achieves high performance, comparable to state-of-the-art super-resolution approaches and with better cross-domain generalisability and anatomical plausibility.
Cooperative Training and Latent Space Data Augmentation for Robust Medical Image Segmentation
Jul 02, 2021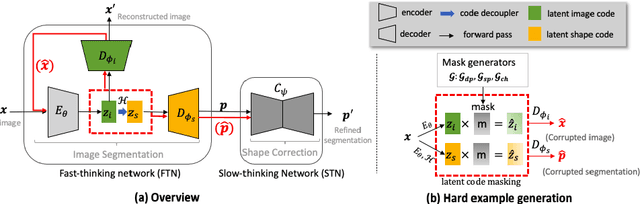
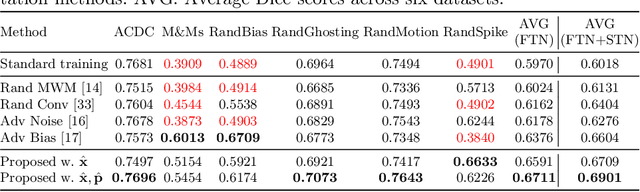
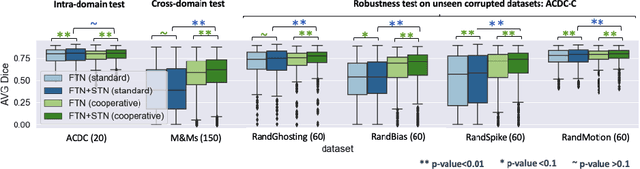
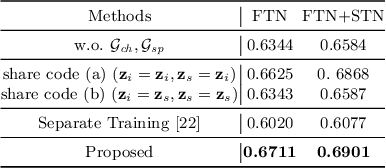
Deep learning-based segmentation methods are vulnerable to unforeseen data distribution shifts during deployment, e.g. change of image appearances or contrasts caused by different scanners, unexpected imaging artifacts etc. In this paper, we present a cooperative framework for training image segmentation models and a latent space augmentation method for generating hard examples. Both contributions improve model generalization and robustness with limited data. The cooperative training framework consists of a fast-thinking network (FTN) and a slow-thinking network (STN). The FTN learns decoupled image features and shape features for image reconstruction and segmentation tasks. The STN learns shape priors for segmentation correction and refinement. The two networks are trained in a cooperative manner. The latent space augmentation generates challenging examples for training by masking the decoupled latent space in both channel-wise and spatial-wise manners. We performed extensive experiments on public cardiac imaging datasets. Using only 10 subjects from a single site for training, we demonstrated improved cross-site segmentation performance and increased robustness against various unforeseen imaging artifacts compared to strong baseline methods. Particularly, cooperative training with latent space data augmentation yields 15% improvement in terms of average Dice score when compared to a standard training method.
Biomechanics-informed Neural Networks for Myocardial Motion Tracking in MRI
Jul 04, 2020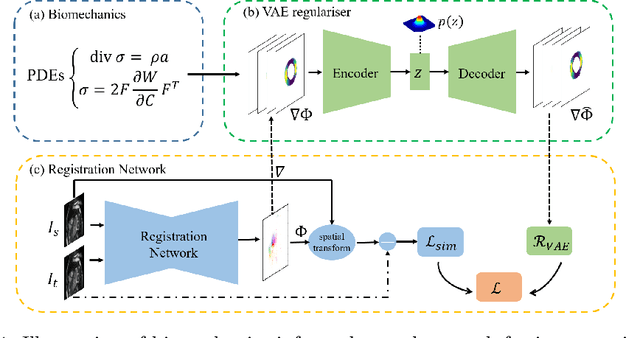
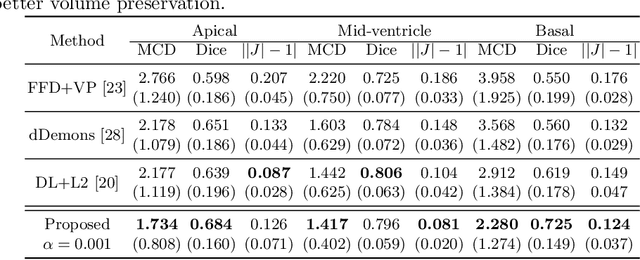
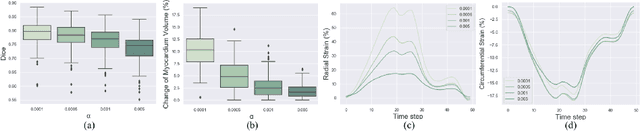
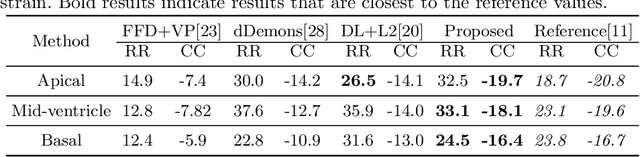
Image registration is an ill-posed inverse problem which often requires regularisation on the solution space. In contrast to most of the current approaches which impose explicit regularisation terms such as smoothness, in this paper we propose a novel method that can implicitly learn biomechanics-informed regularisation. Such an approach can incorporate application-specific prior knowledge into deep learning based registration. Particularly, the proposed biomechanics-informed regularisation leverages a variational autoencoder (VAE) to learn a manifold for biomechanically plausible deformations and to implicitly capture their underlying properties via reconstructing biomechanical simulations. The learnt VAE regulariser then can be coupled with any deep learning based registration network to regularise the solution space to be biomechanically plausible. The proposed method is validated in the context of myocardial motion tracking on 2D stacks of cardiac MRI data from two different datasets. The results show that it can achieve better performance against other competing methods in terms of motion tracking accuracy and has the ability to learn biomechanical properties such as incompressibility and strains. The method has also been shown to have better generalisability to unseen domains compared with commonly used L2 regularisation schemes.
Suggestive Annotation of Brain Tumour Images with Gradient-guided Sampling
Jul 03, 2020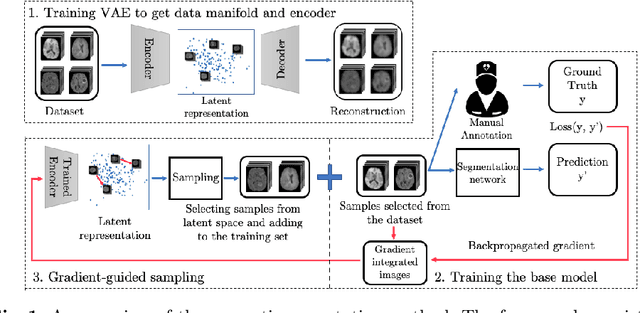
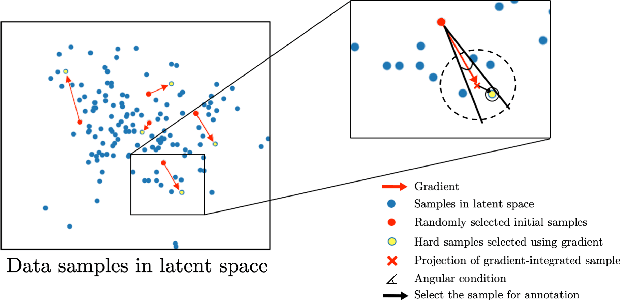
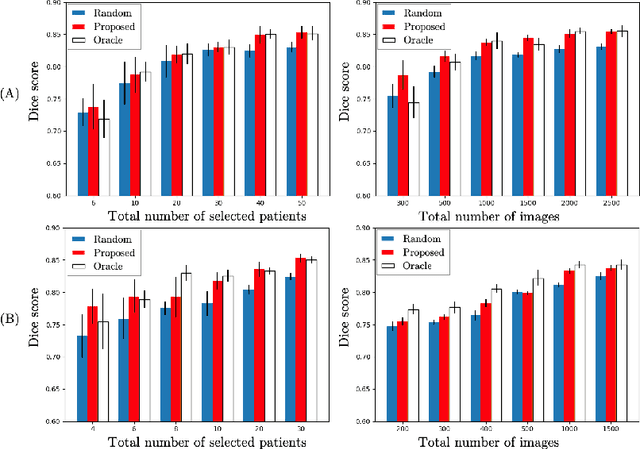
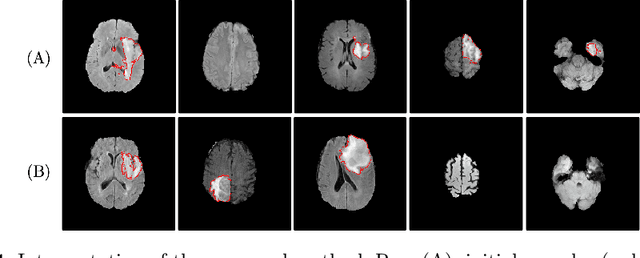
Machine learning has been widely adopted for medical image analysis in recent years given its promising performance in image segmentation and classification tasks. As a data-driven science, the success of machine learning, in particular supervised learning, largely depends on the availability of manually annotated datasets. For medical imaging applications, such annotated datasets are not easy to acquire. It takes a substantial amount of time and resource to curate an annotated medical image set. In this paper, we propose an efficient annotation framework for brain tumour images that is able to suggest informative sample images for human experts to annotate. Our experiments show that training a segmentation model with only 19% suggestively annotated patient scans from BraTS 2019 dataset can achieve a comparable performance to training a model on the full dataset for whole tumour segmentation task. It demonstrates a promising way to save manual annotation cost and improve data efficiency in medical imaging applications.