 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Versatile Cataract Fundus Image Restoration Model Utilizing Unpaired Cataract and High-quality Images
Nov 19, 2024



Cataract is one of the most common blinding eye diseases and can be treated by surgery. However, because cataract patients may also suffer from other blinding eye diseases, ophthalmologists must diagnose them before surgery. The cloudy lens of cataract patients forms a hazy degeneration in the fundus images, making it challenging to observe the patient's fundus vessels, which brings difficulties to the diagnosis process. To address this issue, this paper establishes a new cataract image restoration method named Catintell. It contains a cataract image synthesizing model, Catintell-Syn, and a restoration model, Catintell-Res. Catintell-Syn uses GAN architecture with fully unsupervised data to generate paired cataract-like images with realistic style and texture rather than the conventional Gaussian degradation algorithm. Meanwhile, Catintell-Res is an image restoration network that can improve the quality of real cataract fundus images using the knowledge learned from synthetic cataract images. Extensive experiments show that Catintell-Res outperforms other cataract image restoration methods in PSNR with 39.03 and SSIM with 0.9476. Furthermore, the universal restoration ability that Catintell-Res gained from unpaired cataract images can process cataract images from various datasets. We hope the models can help ophthalmologists identify other blinding eye diseases of cataract patients and inspire more medical image restoration methods in the future.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Vitruvion: A Generative Model of Parametric CAD Sketches
Sep 29, 2021
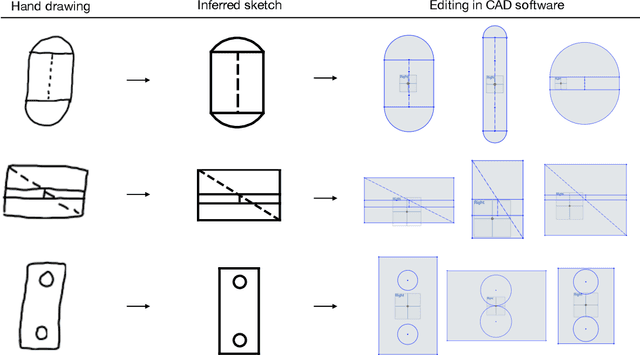
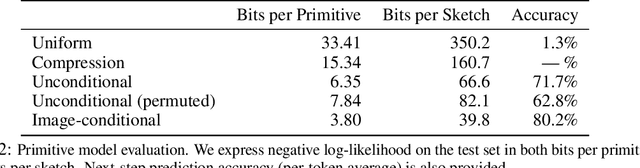
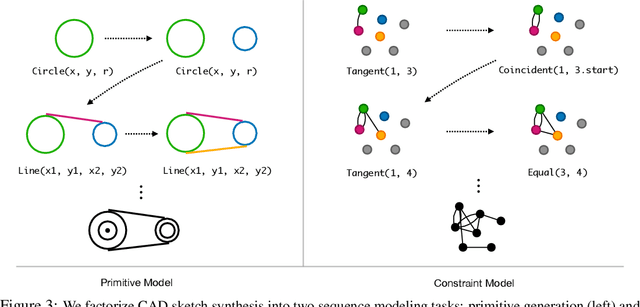
Parametric computer-aided design (CAD) tools are the predominant way that engineers specify physical structures, from bicycle pedals to airplanes to printed circuit boards. The key characteristic of parametric CAD is that design intent is encoded not only via geometric primitives, but also by parameterized constraints between the elements. This relational specification can be viewed as the construction of a constraint program, allowing edits to coherently propagate to other parts of the design. Machine learning offers the intriguing possibility of accelerating the design process via generative modeling of these structures, enabling new tools such as autocompletion, constraint inference, and conditional synthesis. In this work, we present such an approach to generative modeling of parametric CAD sketches, which constitute the basic computational building blocks of modern mechanical design. Our model, trained on real-world designs from the SketchGraphs dataset, autoregressively synthesizes sketches as sequences of primitives, with initial coordinates, and constraints that reference back to the sampled primitives. As samples from the model match the constraint graph representation used in standard CAD software, they may be directly imported, solved, and edited according to downstream design tasks. In addition, we condition the model on various contexts, including partial sketches (primers) and images of hand-drawn sketches. Evaluation of the proposed approach demonstrates its ability to synthesize realistic CAD sketches and its potential to aid the mechanical design workflow.
Autobahn: Automorphism-based Graph Neural Nets
Mar 02, 2021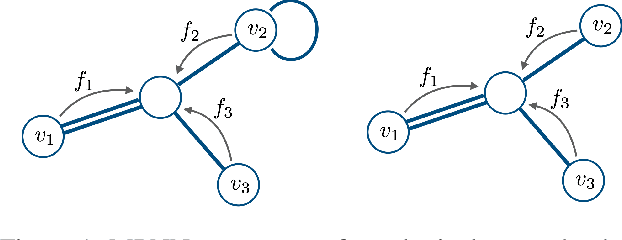
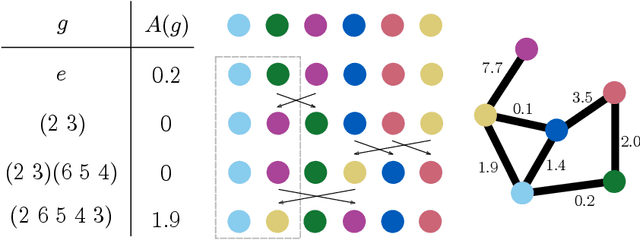

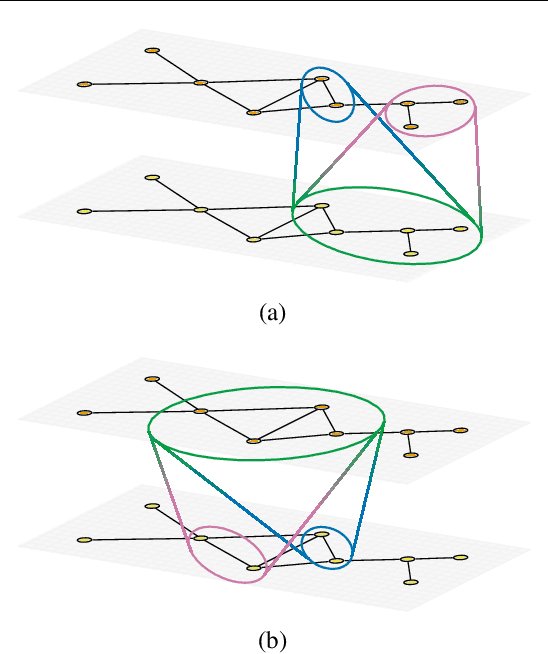
We introduce Automorphism-based graph neural networks (Autobahn), a new family of graph neural networks. In an Autobahn, we decompose the graph into a collection of subgraphs and applying local convolutions that are equivariant to each subgraph's automorphism group. Specific choices of local neighborhoods and subgraphs recover existing architectures such as message passing neural networks. However, our formalism also encompasses novel architectures: as an example, we introduce a graph neural network that decomposes the graph into paths and cycles. The resulting convolutions reflect the natural way that parts of the graph can transform, preserving the intuitive meaning of convolution without sacrificing global permutation equivariance. We validate our approach by applying Autobahn to molecular graphs, where it achieves state-of-the-art results.
SketchGraphs: A Large-Scale Dataset for Modeling Relational Geometry in Computer-Aided Design
Jul 16, 2020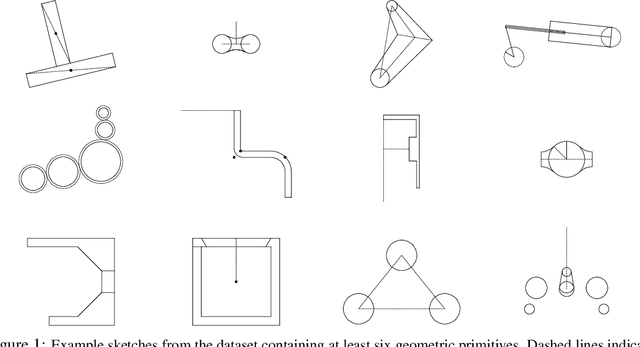
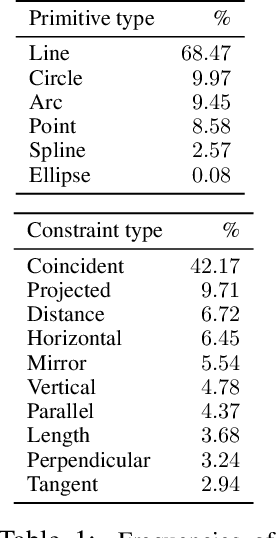
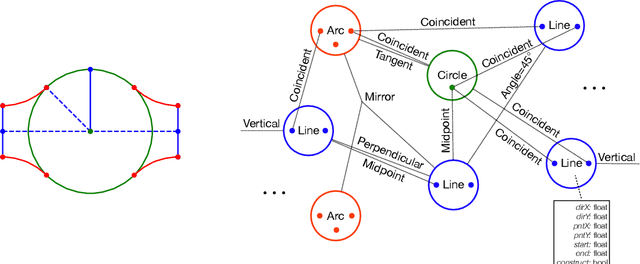
Parametric computer-aided design (CAD) is the dominant paradigm in mechanical engineering for physical design. Distinguished by relational geometry, parametric CAD models begin as two-dimensional sketches consisting of geometric primitives (e.g., line segments, arcs) and explicit constraints between them (e.g., coincidence, perpendicularity) that form the basis for three-dimensional construction operations. Training machine learning models to reason about and synthesize parametric CAD designs has the potential to reduce design time and enable new design workflows. Additionally, parametric CAD designs can be viewed as instances of constraint programming and they offer a well-scoped test bed for exploring ideas in program synthesis and induction. To facilitate this research, we introduce SketchGraphs, a collection of 15 million sketches extracted from real-world CAD models coupled with an open-source data processing pipeline. Each sketch is represented as a geometric constraint graph where edges denote designer-imposed geometric relationships between primitives, the nodes of the graph. We demonstrate and establish benchmarks for two use cases of the dataset: generative modeling of sketches and conditional generation of likely constraints given unconstrained geometry.
Error bounds in estimating the out-of-sample prediction error using leave-one-out cross validation in high-dimensions
Mar 03, 2020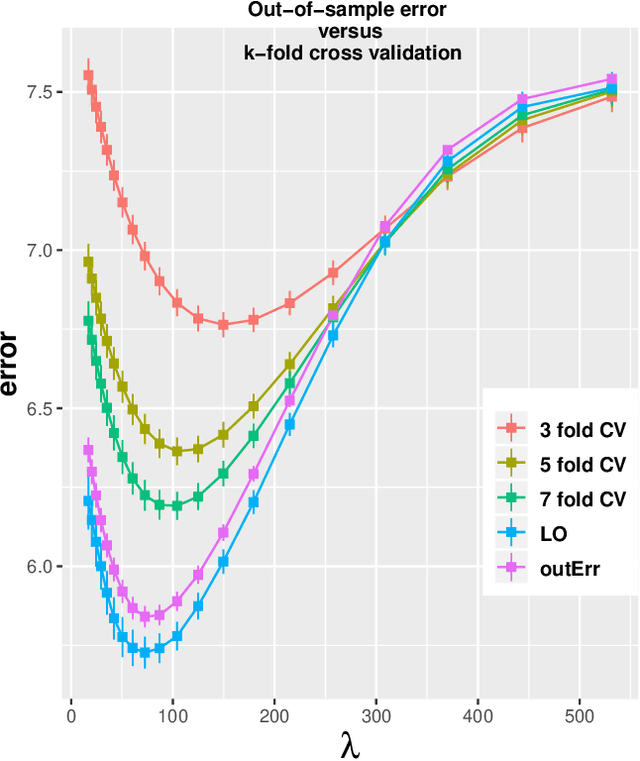
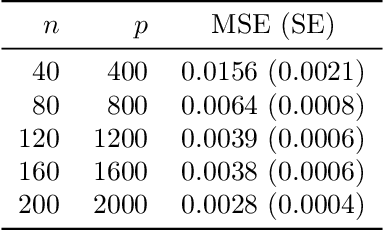
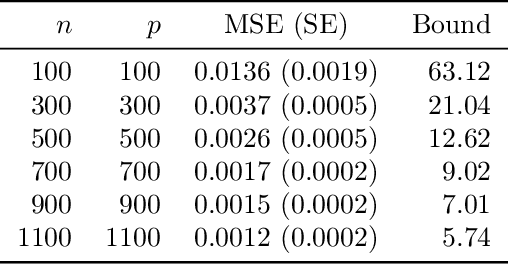
We study the problem of out-of-sample risk estimation in the high dimensional regime where both the sample size $n$ and number of features $p$ are large, and $n/p$ can be less than one. Extensive empirical evidence confirms the accuracy of leave-one-out cross validation (LO) for out-of-sample risk estimation. Yet, a unifying theoretical evaluation of the accuracy of LO in high-dimensional problems has remained an open problem. This paper aims to fill this gap for penalized regression in the generalized linear family. With minor assumptions about the data generating process, and without any sparsity assumptions on the regression coefficients, our theoretical analysis obtains finite sample upper bounds on the expected squared error of LO in estimating the out-of-sample error. Our bounds show that the error goes to zero as $n,p \rightarrow \infty$, even when the dimension $p$ of the feature vectors is comparable with or greater than the sample size $n$. One technical advantage of the theory is that it can be used to clarify and connect some results from the recent literature on scalable approximate LO.
Discrete Object Generation with Reversible Inductive Construction
Jul 18, 2019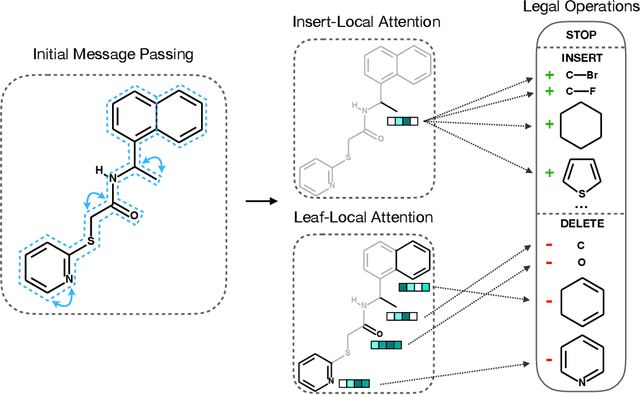
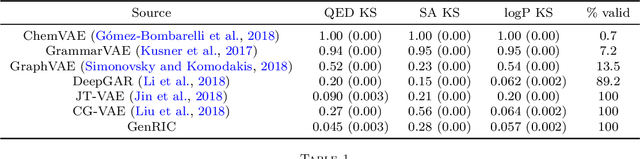

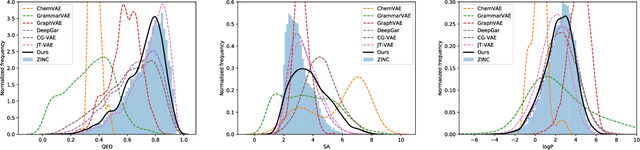
The success of generative modeling in continuous domains has led to a surge of interest in generating discrete data such as molecules, source code, and graphs. However, construction histories for these discrete objects are typically not unique and so generative models must reason about intractably large spaces in order to learn. Additionally, structured discrete domains are often characterized by strict constraints on what constitutes a valid object and generative models must respect these requirements in order to produce useful novel samples. Here, we present a generative model for discrete objects employing a Markov chain where transitions are restricted to a set of local operations that preserve validity. Building off of generative interpretations of denoising autoencoders, the Markov chain alternates between producing 1) a sequence of corrupted objects that are valid but not from the data distribution, and 2) a learned reconstruction distribution that attempts to fix the corruptions while also preserving validity. This approach constrains the generative model to only produce valid objects, requires the learner to only discover local modifications to the objects, and avoids marginalization over an unknown and potentially large space of construction histories. We evaluate the proposed approach on two highly structured discrete domains, molecules and Laman graphs, and find that it compares favorably to alternative methods at capturing distributional statistics for a host of semantically relevant metrics.
Approximate Leave-One-Out for Fast Parameter Tuning in High Dimensions
Jul 07, 2018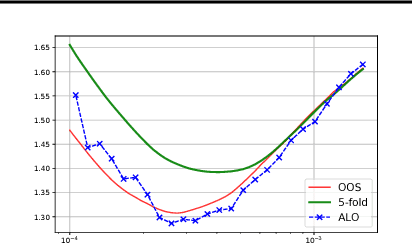
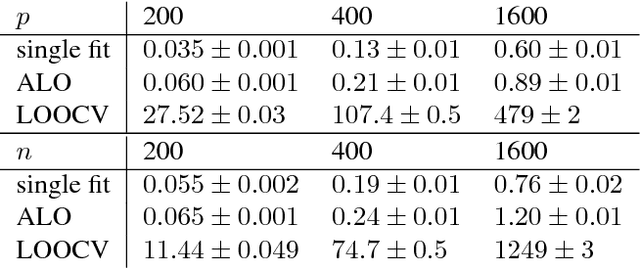
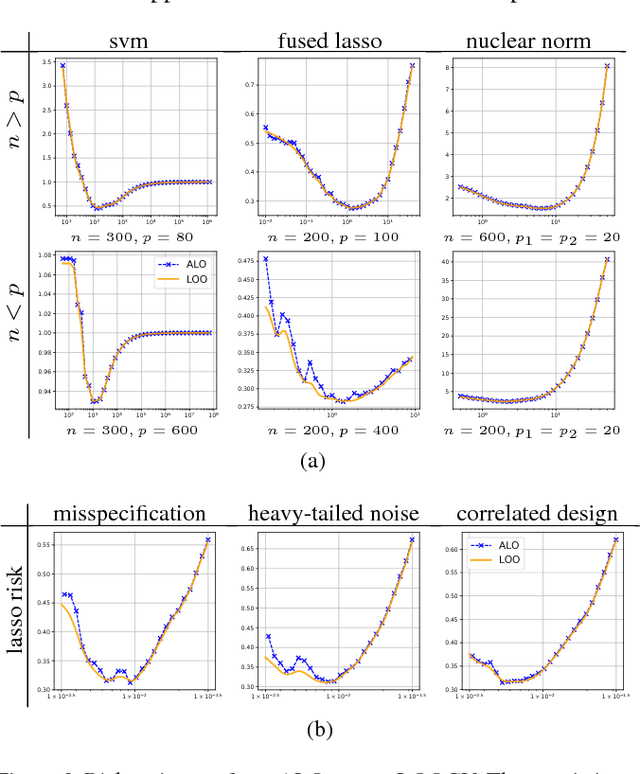
Consider the following class of learning schemes: $$\hat{\boldsymbol{\beta}} := \arg\min_{\boldsymbol{\beta}}\;\sum_{j=1}^n \ell(\boldsymbol{x}_j^\top\boldsymbol{\beta}; y_j) + \lambda R(\boldsymbol{\beta}),\qquad\qquad (1) $$ where $\boldsymbol{x}_i \in \mathbb{R}^p$ and $y_i \in \mathbb{R}$ denote the $i^{\text{th}}$ feature and response variable respectively. Let $\ell$ and $R$ be the loss function and regularizer, $\boldsymbol{\beta}$ denote the unknown weights, and $\lambda$ be a regularization parameter. Finding the optimal choice of $\lambda$ is a challenging problem in high-dimensional regimes where both $n$ and $p$ are large. We propose two frameworks to obtain a computationally efficient approximation ALO of the leave-one-out cross validation (LOOCV) risk for nonsmooth losses and regularizers. Our two frameworks are based on the primal and dual formulations of (1). We prove the equivalence of the two approaches under smoothness conditions. This equivalence enables us to justify the accuracy of both methods under such conditions. We use our approaches to obtain a risk estimate for several standard problems, including generalized LASSO, nuclear norm regularization, and support vector machines. We empirically demonstrate the effectiveness of our results for non-differentiable cases.