 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning
Oct 14, 2021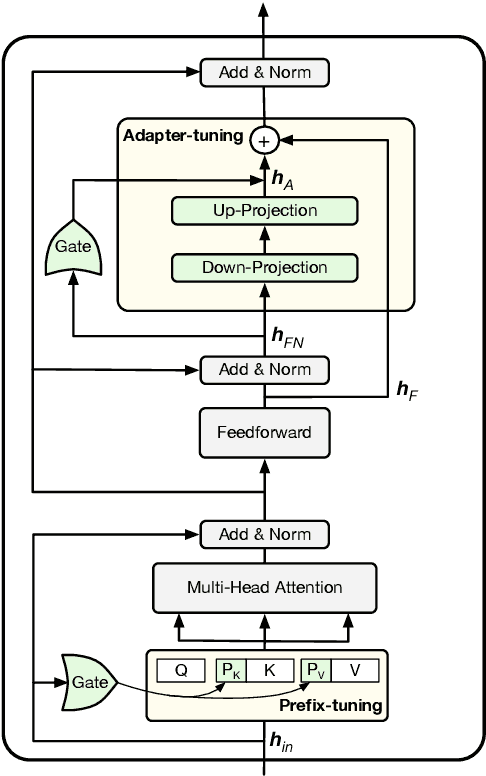
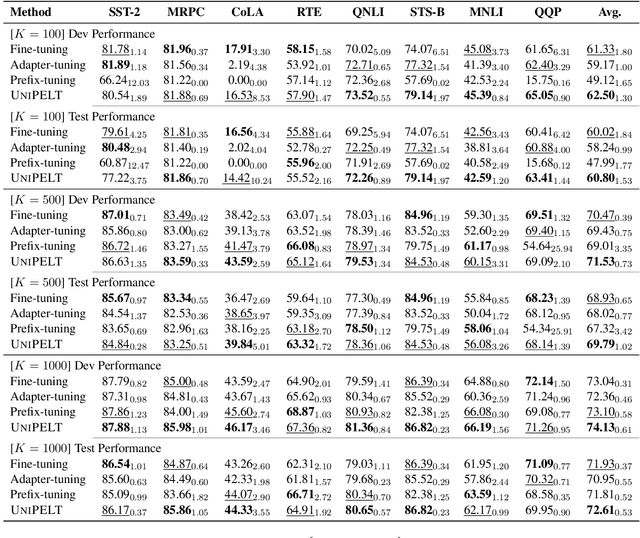
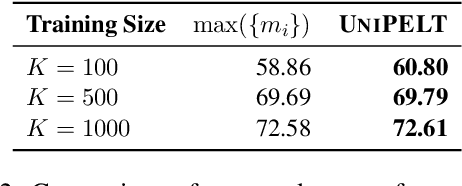
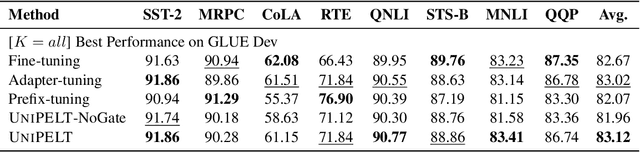
Conventional fine-tuning of pre-trained language models tunes all model parameters and stores a full model copy for each downstream task, which has become increasingly infeasible as the model size grows larger. Recent parameter-efficient language model tuning (PELT) methods manage to match the performance of fine-tuning with much fewer trainable parameters and perform especially well when the training data is limited. However, different PELT methods may perform rather differently on the same task, making it nontrivial to select the most appropriate method for a specific task, especially considering the fast-growing number of new PELT methods and downstream tasks. In light of model diversity and the difficulty of model selection, we propose a unified framework, UniPELT, which incorporates different PELT methods as submodules and learns to activate the ones that best suit the current data or task setup. Remarkably, on the GLUE benchmark, UniPELT consistently achieves 1~3pt gains compared to the best individual PELT method that it incorporates and even outperforms fine-tuning under different setups. Moreover, UniPELT often surpasses the upper bound when taking the best performance of all its submodules used individually on each task, indicating that a mixture of multiple PELT methods may be inherently more effective than single methods.
Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?
Oct 13, 2021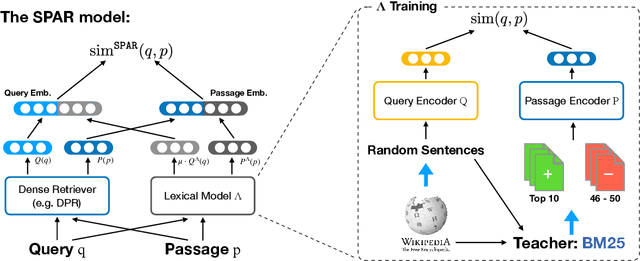
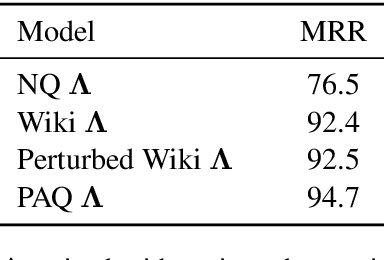
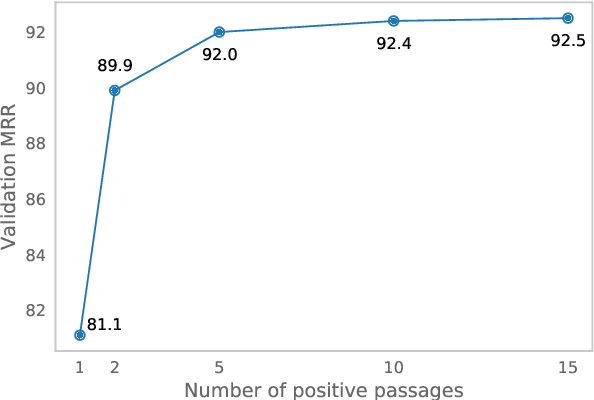
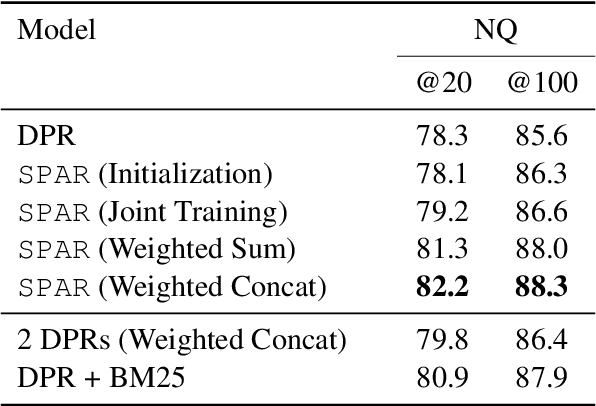
Despite their recent popularity and well known advantages, dense retrievers still lag behind sparse methods such as BM25 in their ability to reliably match salient phrases and rare entities in the query. It has been argued that this is an inherent limitation of dense models. We disprove this claim by introducing the Salient Phrase Aware Retriever (SPAR), a dense retriever with the lexical matching capacity of a sparse model. In particular, we show that a dense retriever {\Lambda} can be trained to imitate a sparse one, and SPAR is built by augmenting a standard dense retriever with {\Lambda}. When evaluated on five open-domain question answering datasets and the MS MARCO passage retrieval task, SPAR sets a new state of the art for dense and sparse retrievers and can match or exceed the performance of more complicated dense-sparse hybrid systems.
Domain-matched Pre-training Tasks for Dense Retrieval
Jul 28, 2021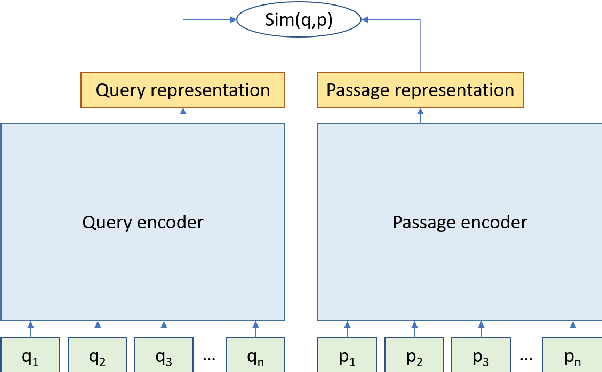
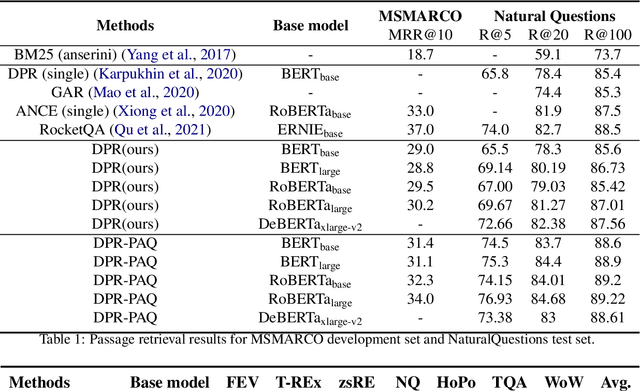
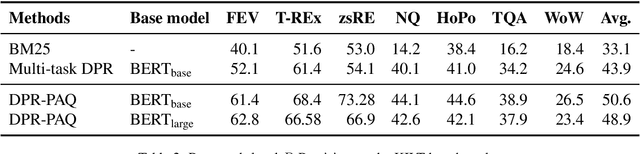
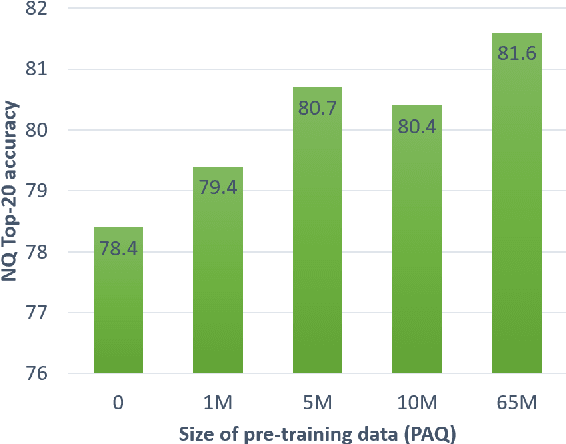
Pre-training on larger datasets with ever increasing model size is now a proven recipe for increased performance across almost all NLP tasks. A notable exception is information retrieval, where additional pre-training has so far failed to produce convincing results. We show that, with the right pre-training setup, this barrier can be overcome. We demonstrate this by pre-training large bi-encoder models on 1) a recently released set of 65 million synthetically generated questions, and 2) 200 million post-comment pairs from a preexisting dataset of Reddit conversations made available by pushshift.io. We evaluate on a set of information retrieval and dialogue retrieval benchmarks, showing substantial improvements over supervised baselines.
On the Efficacy of Adversarial Data Collection for Question Answering: Results from a Large-Scale Randomized Study
Jun 02, 2021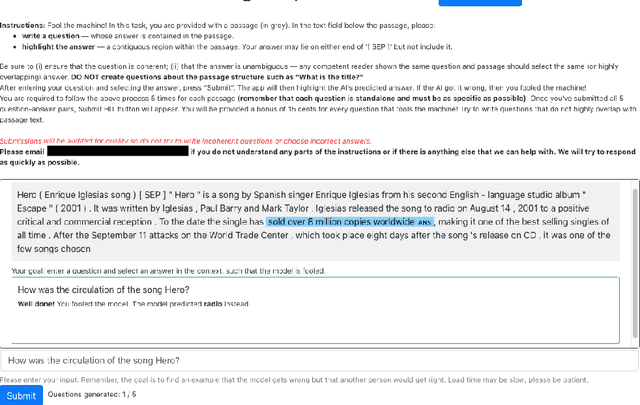


In adversarial data collection (ADC), a human workforce interacts with a model in real time, attempting to produce examples that elicit incorrect predictions. Researchers hope that models trained on these more challenging datasets will rely less on superficial patterns, and thus be less brittle. However, despite ADC's intuitive appeal, it remains unclear when training on adversarial datasets produces more robust models. In this paper, we conduct a large-scale controlled study focused on question answering, assigning workers at random to compose questions either (i) adversarially (with a model in the loop); or (ii) in the standard fashion (without a model). Across a variety of models and datasets, we find that models trained on adversarial data usually perform better on other adversarial datasets but worse on a diverse collection of out-of-domain evaluation sets. Finally, we provide a qualitative analysis of adversarial (vs standard) data, identifying key differences and offering guidance for future research.
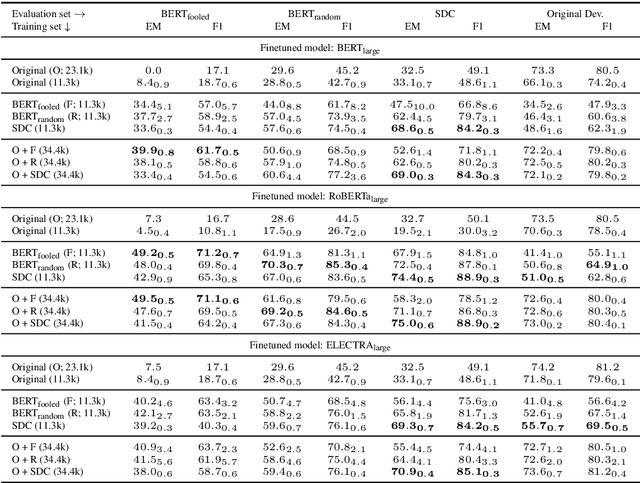
On the Influence of Masking Policies in Intermediate Pre-training
Apr 18, 2021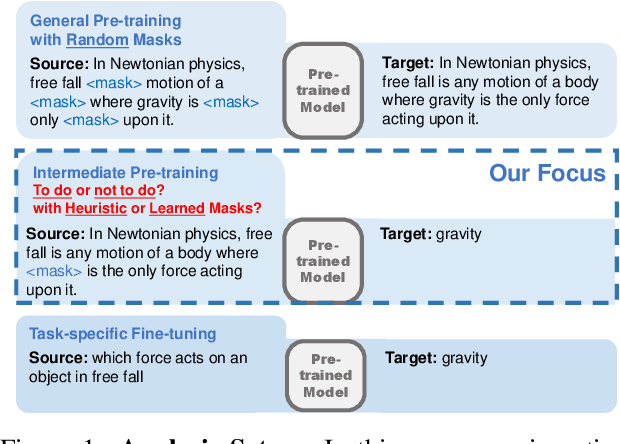
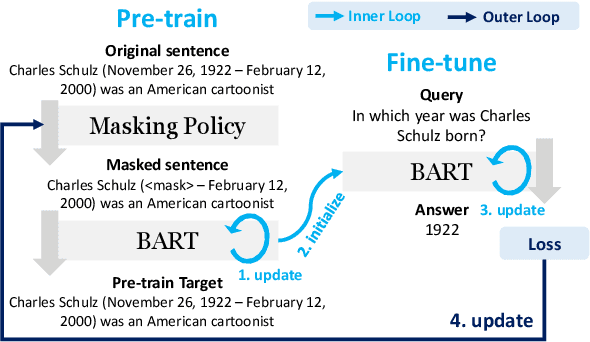
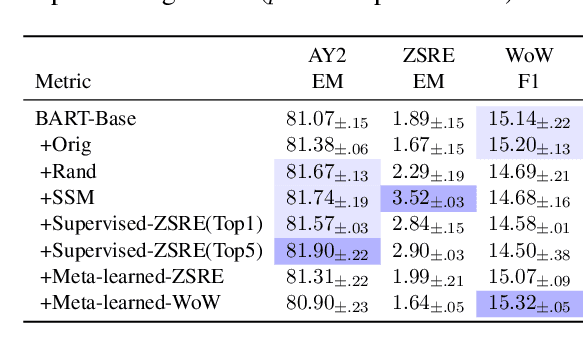
Current NLP models are predominantly trained through a pretrain-then-finetune pipeline, where models are first pretrained on a large text corpus with a masked-language-modelling (MLM) objective, then finetuned on the downstream task. Prior work has shown that inserting an intermediate pre-training phase, with heuristic MLM objectives that resemble downstream tasks, can significantly improve final performance. However, it is still unclear (1) in what cases such intermediate pre-training is helpful, (2) whether hand-crafted heuristic objectives are optimal for a given task, and (3) whether a MLM policy designed for one task is generalizable beyond that task. In this paper, we perform a large-scale empirical study to investigate the effect of various MLM policies in intermediate pre-training. Crucially, we introduce methods to automate discovery of optimal MLM policies, by learning a masking model through either direct supervision or meta-learning on the downstream task. We investigate the effects of using heuristic, directly supervised, and meta-learned MLM policies for intermediate pretraining, on eight selected tasks across three categories (closed-book QA, knowledge-intensive language tasks, and abstractive summarization). Most notably, we show that learned masking policies outperform the heuristic of masking named entities on TriviaQA, and masking policies learned on one task can positively transfer to other tasks in certain cases.
On Unifying Misinformation Detection
Apr 12, 2021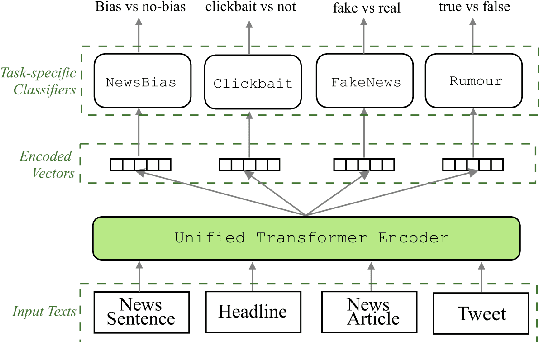

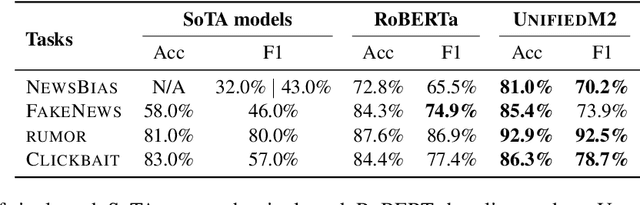
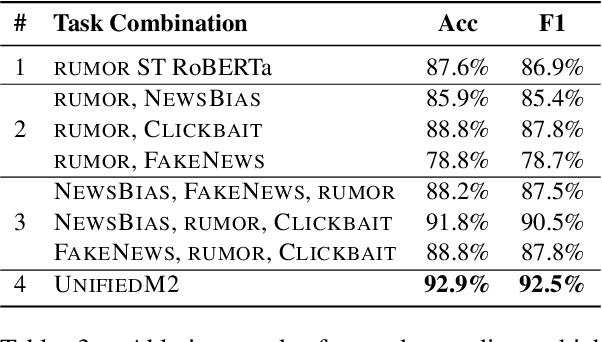
In this paper, we introduce UnifiedM2, a general-purpose misinformation model that jointly models multiple domains of misinformation with a single, unified setup. The model is trained to handle four tasks: detecting news bias, clickbait, fake news, and verifying rumors. By grouping these tasks together, UnifiedM2learns a richer representation of misinformation, which leads to state-of-the-art or comparable performance across all tasks. Furthermore, we demonstrate that UnifiedM2's learned representation is helpful for few-shot learning of unseen misinformation tasks/datasets and model's generalizability to unseen events.
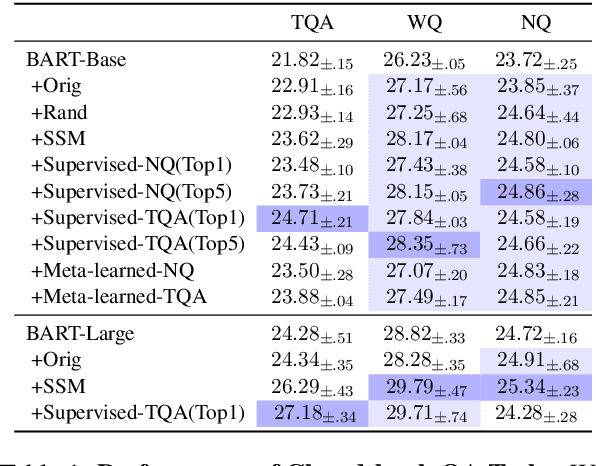
Studying Strategically: Learning to Mask for Closed-book QA
Jan 01, 2021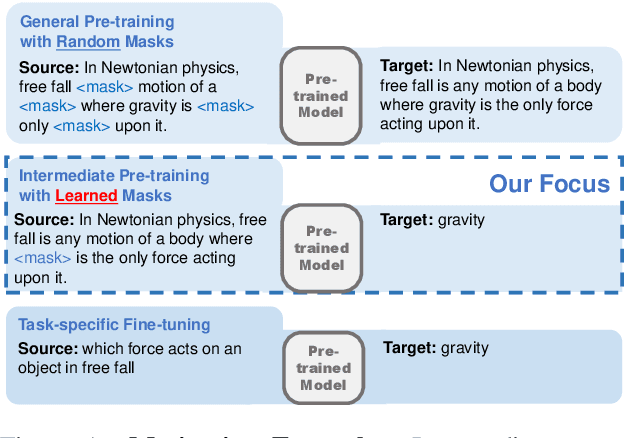

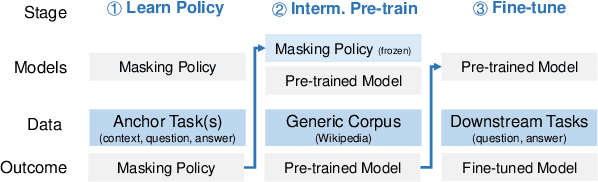

Closed-book question-answering (QA) is a challenging task that requires a model to directly answer questions without access to external knowledge. It has been shown that directly fine-tuning pre-trained language models with (question, answer) examples yields surprisingly competitive performance, which is further improved upon through adding an intermediate pre-training stage between general pre-training and fine-tuning. Prior work used a heuristic during this intermediate stage, whereby named entities and dates are masked, and the model is trained to recover these tokens. In this paper, we aim to learn the optimal masking strategy for the intermediate pre-training stage. We first train our masking policy to extract spans that are likely to be tested, using supervision from the downstream task itself, then deploy the learned policy during intermediate pre-training. Thus, our policy packs task-relevant knowledge into the parameters of a language model. Our approach is particularly effective on TriviaQA, outperforming strong heuristics when used to pre-train BART.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021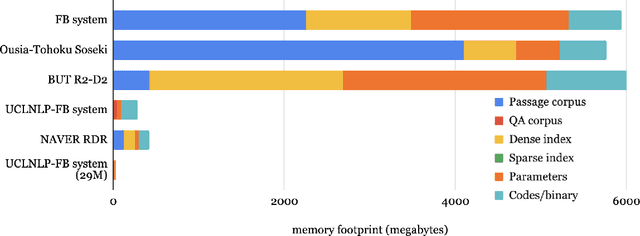
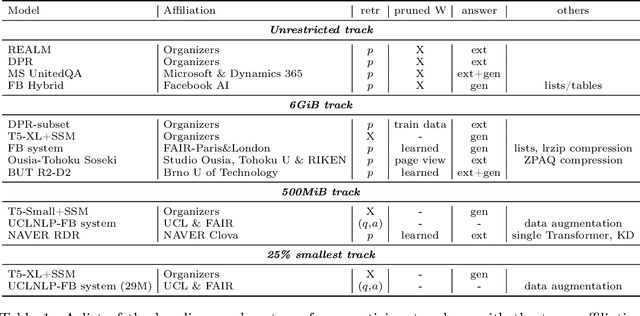
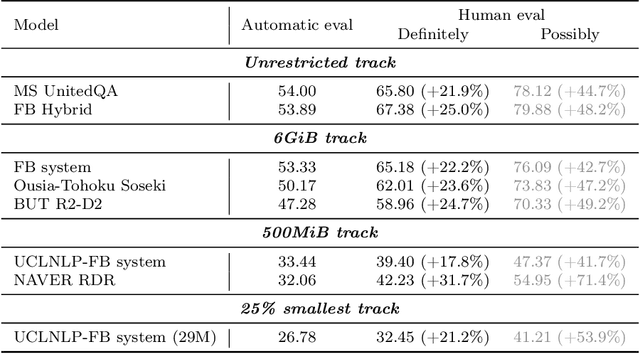
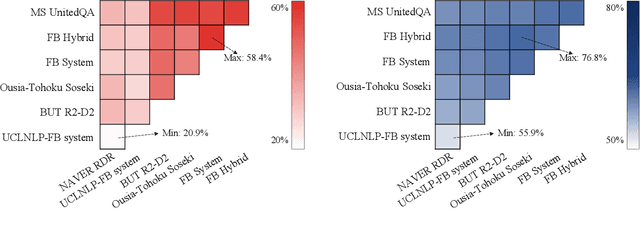
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Multi-task Retrieval for Knowledge-Intensive Tasks
Jan 01, 2021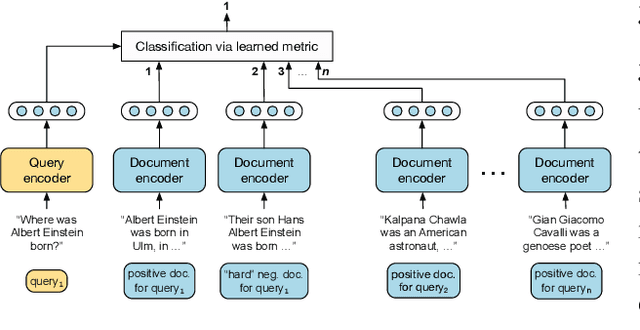

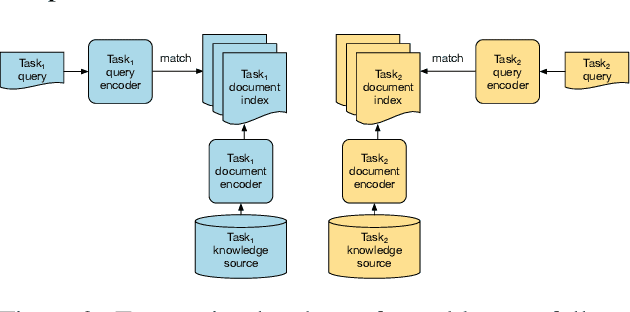
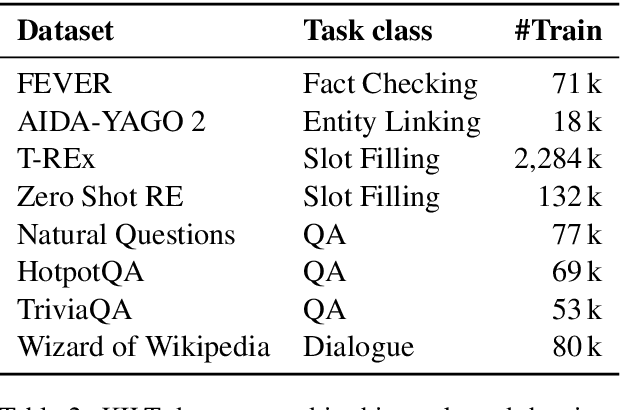
Retrieving relevant contexts from a large corpus is a crucial step for tasks such as open-domain question answering and fact checking. Although neural retrieval outperforms traditional methods like tf-idf and BM25, its performance degrades considerably when applied to out-of-domain data. Driven by the question of whether a neural retrieval model can be universal and perform robustly on a wide variety of problems, we propose a multi-task trained model. Our approach not only outperforms previous methods in the few-shot setting, but also rivals specialised neural retrievers, even when in-domain training data is abundant. With the help of our retriever, we improve existing models for downstream tasks and closely match or improve the state of the art on multiple benchmarks.
FiD-Ex: Improving Sequence-to-Sequence Models for Extractive Rationale Generation
Dec 31, 2020
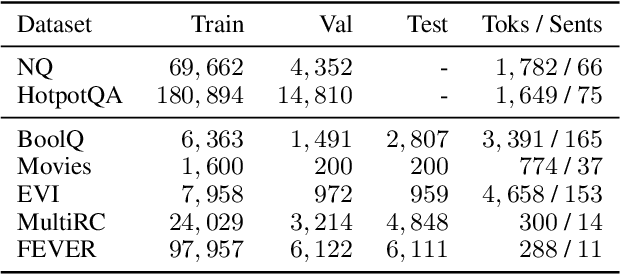
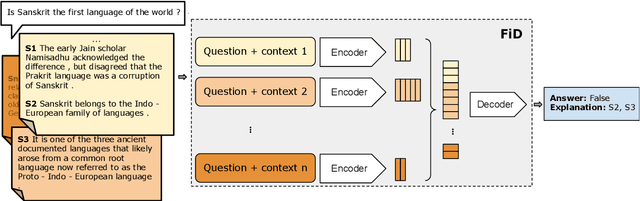
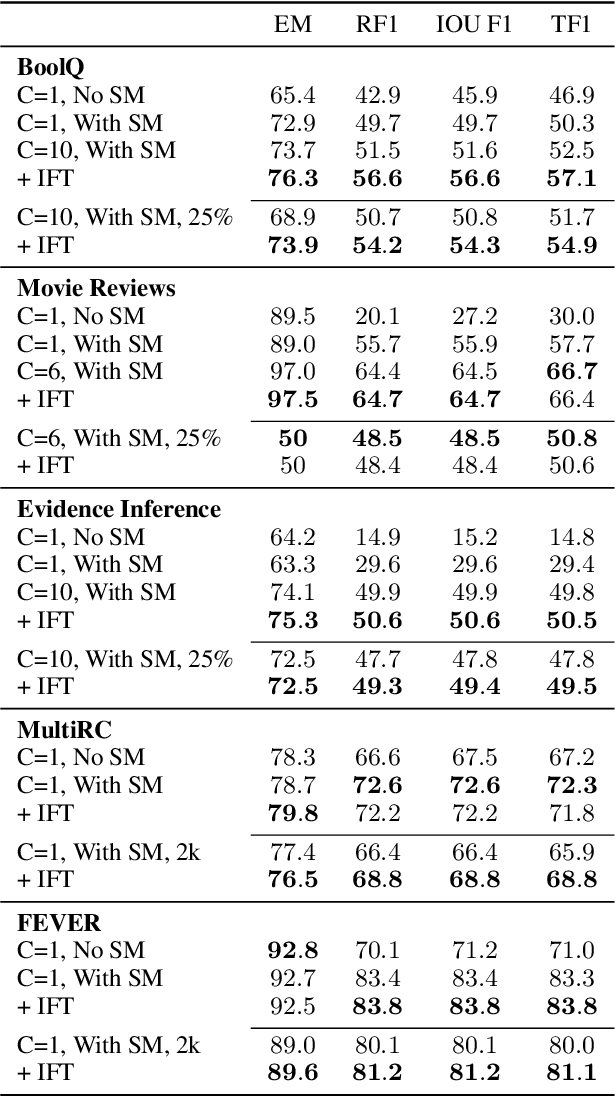
Natural language (NL) explanations of model predictions are gaining popularity as a means to understand and verify decisions made by large black-box pre-trained models, for NLP tasks such as Question Answering (QA) and Fact Verification. Recently, pre-trained sequence to sequence (seq2seq) models have proven to be very effective in jointly making predictions, as well as generating NL explanations. However, these models have many shortcomings; they can fabricate explanations even for incorrect predictions, they are difficult to adapt to long input documents, and their training requires a large amount of labeled data. In this paper, we develop FiD-Ex, which addresses these shortcomings for seq2seq models by: 1) introducing sentence markers to eliminate explanation fabrication by encouraging extractive generation, 2) using the fusion-in-decoder architecture to handle long input contexts, and 3) intermediate fine-tuning on re-structured open domain QA datasets to improve few-shot performance. FiD-Ex significantly improves over prior work in terms of explanation metrics and task accuracy, on multiple tasks from the ERASER explainability benchmark, both in the fully supervised and in the few-shot settings.