 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Alignment using Lip Images for Frame-based Electrolaryngeal Voice Conversion
Sep 08, 2021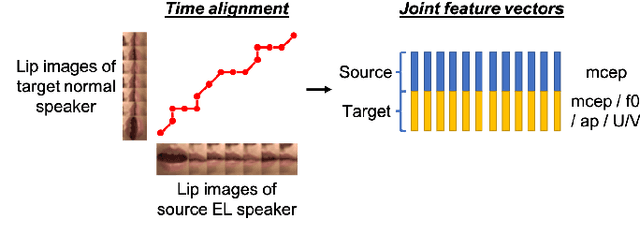
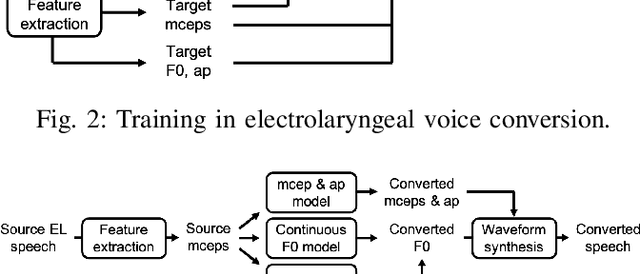
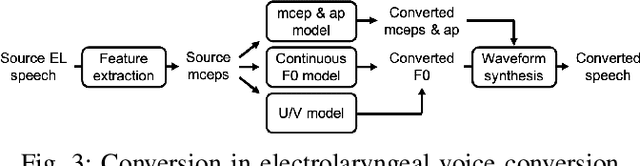
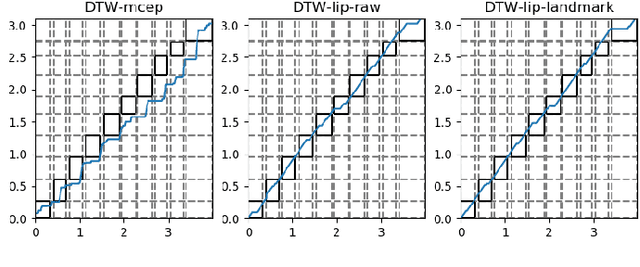
Voice conversion (VC) is an effective approach to electrolaryngeal (EL) speech enhancement, a task that aims to improve the quality of the artificial voice from an electrolarynx device. In frame-based VC methods, time alignment needs to be performed prior to model training, and the dynamic time warping (DTW) algorithm is widely adopted to compute the best time alignment between each utterance pair. The validity is based on the assumption that the same phonemes of the speakers have similar features and can be mapped by measuring a pre-defined distance between speech frames of the source and the target. However, the special characteristics of the EL speech can break the assumption, resulting in a sub-optimal DTW alignment. In this work, we propose to use lip images for time alignment, as we assume that the lip movements of laryngectomee remain normal compared to healthy people. We investigate two naive lip representations and distance metrics, and experimental results demonstrate that the proposed method can significantly outperform the audio-only alignment in terms of objective and subjective evaluations.
On Prosody Modeling for ASR+TTS based Voice Conversion
Jul 20, 2021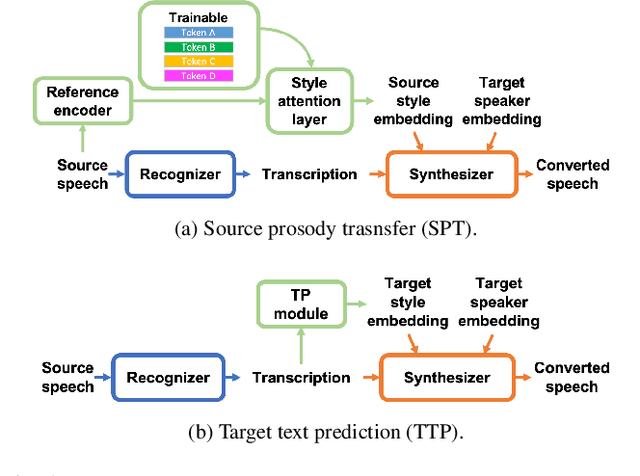

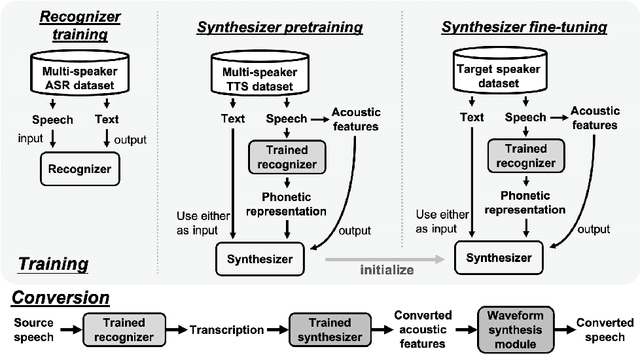

In voice conversion (VC), an approach showing promising results in the latest voice conversion challenge (VCC) 2020 is to first use an automatic speech recognition (ASR) model to transcribe the source speech into the underlying linguistic contents; these are then used as input by a text-to-speech (TTS) system to generate the converted speech. Such a paradigm, referred to as ASR+TTS, overlooks the modeling of prosody, which plays an important role in speech naturalness and conversion similarity. Although some researchers have considered transferring prosodic clues from the source speech, there arises a speaker mismatch during training and conversion. To address this issue, in this work, we propose to directly predict prosody from the linguistic representation in a target-speaker-dependent manner, referred to as target text prediction (TTP). We evaluate both methods on the VCC2020 benchmark and consider different linguistic representations. The results demonstrate the effectiveness of TTP in both objective and subjective evaluations.
Relational Data Selection for Data Augmentation of Speaker-dependent Multi-band MelGAN Vocoder
Jun 10, 2021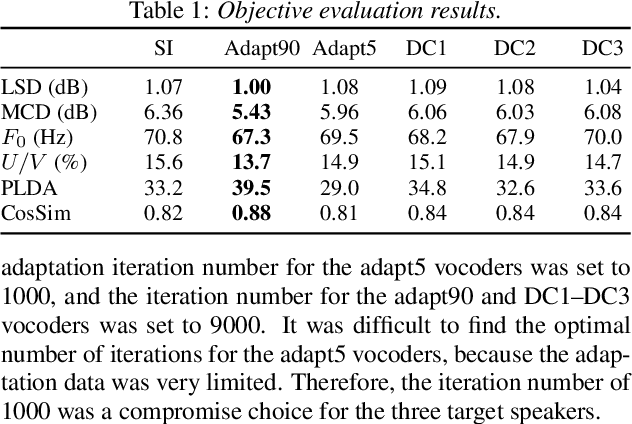
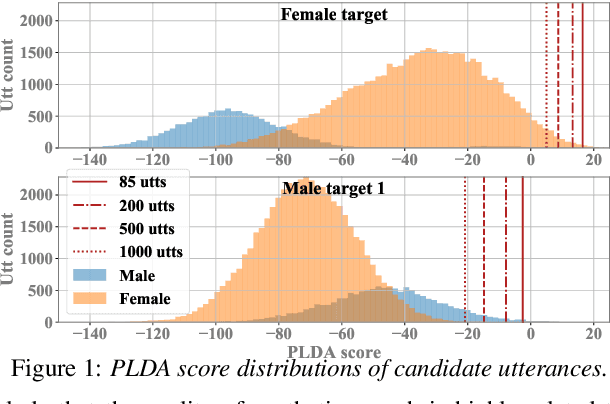
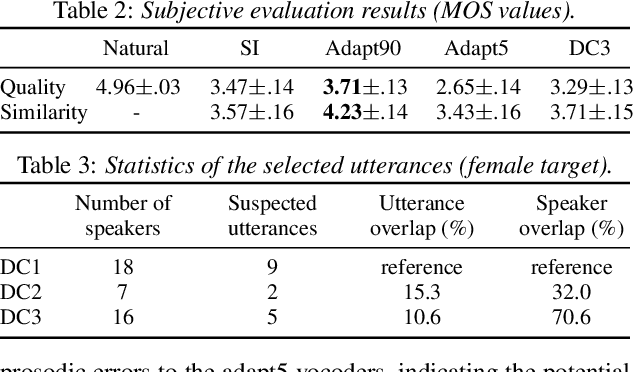
Nowadays, neural vocoders can generate very high-fidelity speech when a bunch of training data is available. Although a speaker-dependent (SD) vocoder usually outperforms a speaker-independent (SI) vocoder, it is impractical to collect a large amount of data of a specific target speaker for most real-world applications. To tackle the problem of limited target data, a data augmentation method based on speaker representation and similarity measurement of speaker verification is proposed in this paper. The proposed method selects utterances that have similar speaker identity to the target speaker from an external corpus, and then combines the selected utterances with the limited target data for SD vocoder adaptation. The evaluation results show that, compared with the vocoder adapted using only limited target data, the vocoder adapted using augmented data improves both the quality and similarity of synthesized speech.
A Preliminary Study of a Two-Stage Paradigm for Preserving Speaker Identity in Dysarthric Voice Conversion
Jun 02, 2021

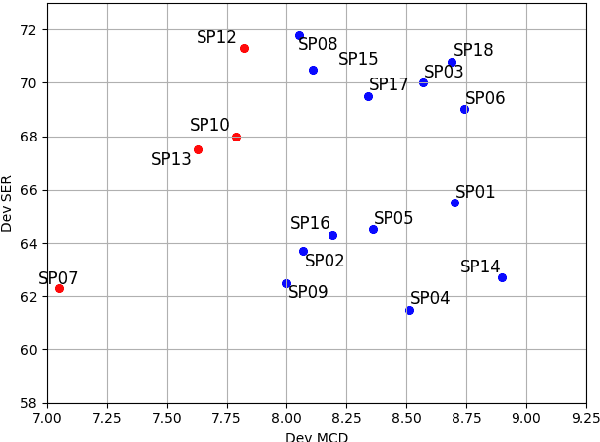
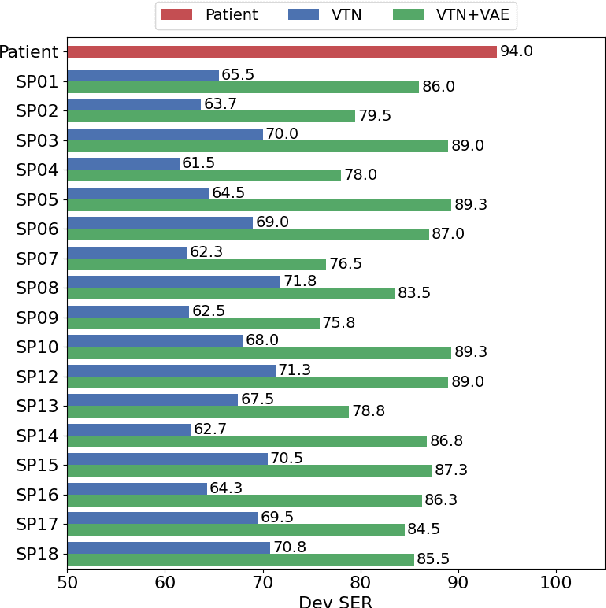
We propose a new paradigm for maintaining speaker identity in dysarthric voice conversion (DVC). The poor quality of dysarthric speech can be greatly improved by statistical VC, but as the normal speech utterances of a dysarthria patient are nearly impossible to collect, previous work failed to recover the individuality of the patient. In light of this, we suggest a novel, two-stage approach for DVC, which is highly flexible in that no normal speech of the patient is required. First, a powerful parallel sequence-to-sequence model converts the input dysarthric speech into a normal speech of a reference speaker as an intermediate product, and a nonparallel, frame-wise VC model realized with a variational autoencoder then converts the speaker identity of the reference speech back to that of the patient while assumed to be capable of preserving the enhanced quality. We investigate several design options. Experimental evaluation results demonstrate the potential of our approach to improving the quality of the dysarthric speech while maintaining the speaker identity.
Non-autoregressive sequence-to-sequence voice conversion
Apr 14, 2021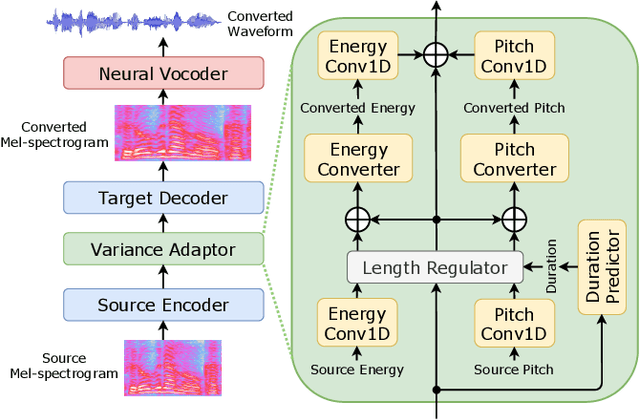
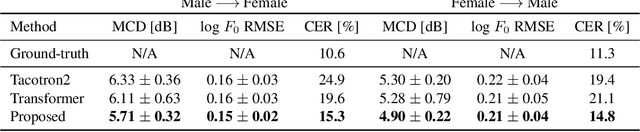
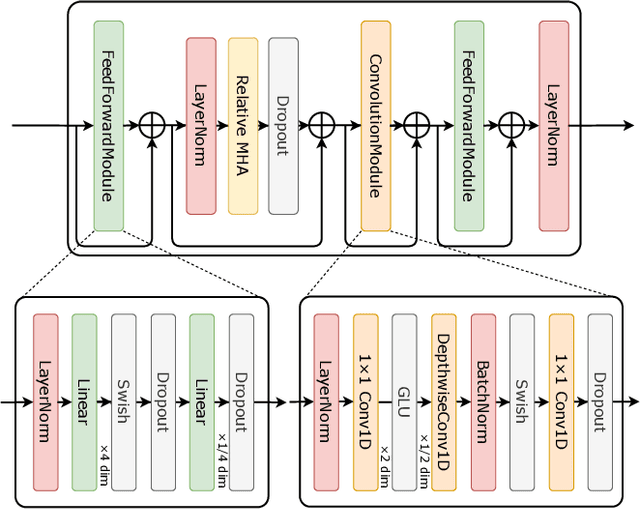

This paper proposes a novel voice conversion (VC) method based on non-autoregressive sequence-to-sequence (NAR-S2S) models. Inspired by the great success of NAR-S2S models such as FastSpeech in text-to-speech (TTS), we extend the FastSpeech2 model for the VC problem. We introduce the convolution-augmented Transformer (Conformer) instead of the Transformer, making it possible to capture both local and global context information from the input sequence. Furthermore, we extend variance predictors to variance converters to explicitly convert the source speaker's prosody components such as pitch and energy into the target speaker. The experimental evaluation with the Japanese speaker dataset, which consists of male and female speakers of 1,000 utterances, demonstrates that the proposed model enables us to perform more stable, faster, and better conversion than autoregressive S2S (AR-S2S) models such as Tacotron2 and Transformer.
The AS-NU System for the M2VoC Challenge
Apr 07, 2021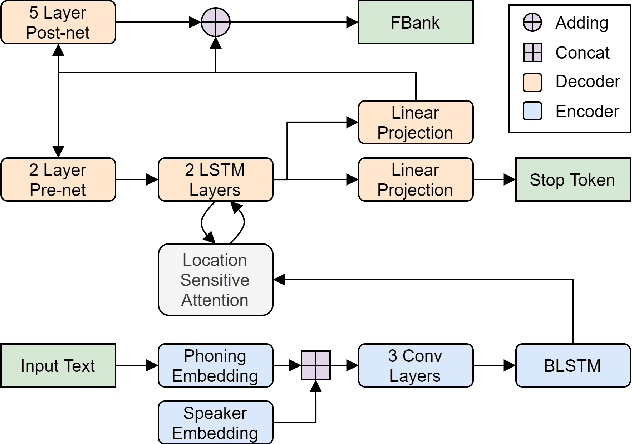
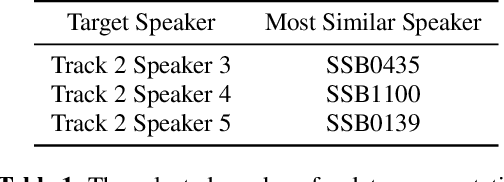
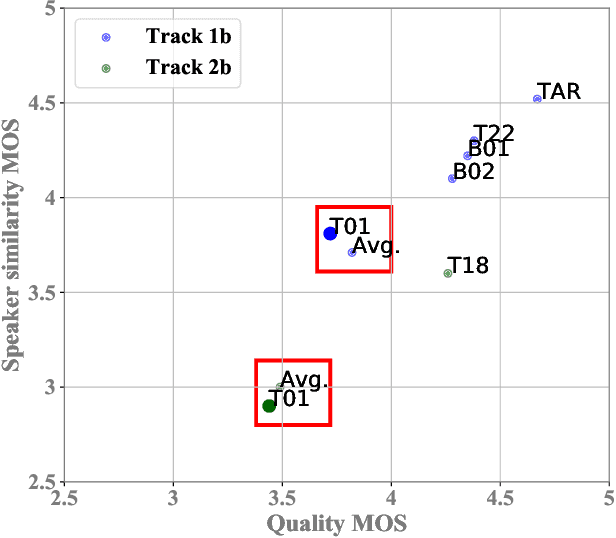
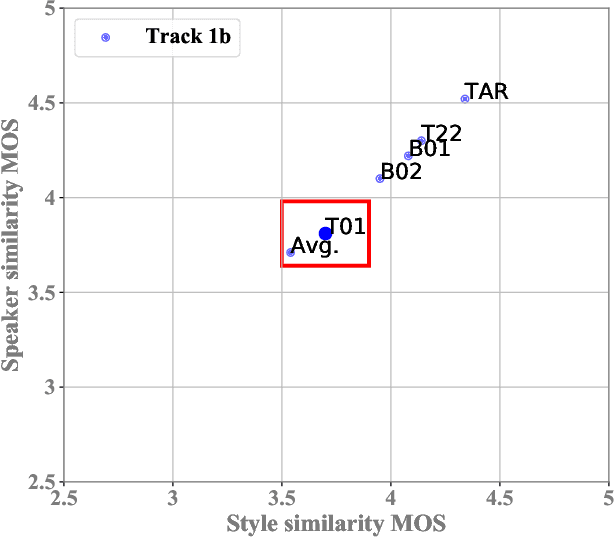
This paper describes the AS-NU systems for two tracks in MultiSpeaker Multi-Style Voice Cloning Challenge (M2VoC). The first track focuses on using a small number of 100 target utterances for voice cloning, while the second track focuses on using only 5 target utterances for voice cloning. Due to the serious lack of data in the second track, we selected the speaker most similar to the target speaker from the training data of the TTS system, and used the speaker's utterances and the given 5 target utterances to fine-tune our model. The evaluation results show that our systems on the two tracks perform similarly in terms of quality, but there is still a clear gap between the similarity score of the second track and the similarity score of the first track.
crank: An Open-Source Software for Nonparallel Voice Conversion Based on Vector-Quantized Variational Autoencoder
Mar 04, 2021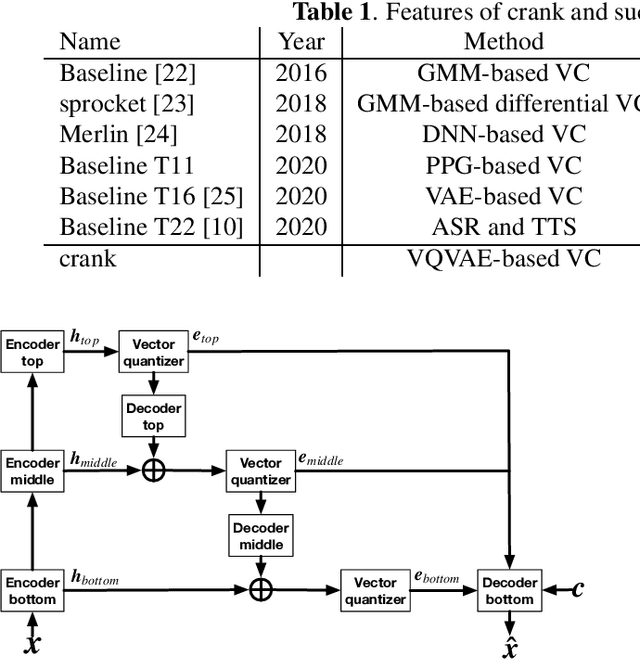
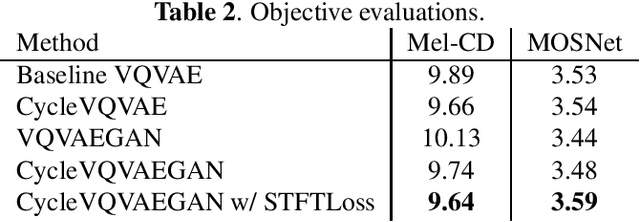
In this paper, we present an open-source software for developing a nonparallel voice conversion (VC) system named crank. Although we have released an open-source VC software based on the Gaussian mixture model named sprocket in the last VC Challenge, it is not straightforward to apply any speech corpus because it is necessary to prepare parallel utterances of source and target speakers to model a statistical conversion function. To address this issue, in this study, we developed a new open-source VC software that enables users to model the conversion function by using only a nonparallel speech corpus. For implementing the VC software, we used a vector-quantized variational autoencoder (VQVAE). To rapidly examine the effectiveness of recent technologies developed in this research field, crank also supports several representative works for autoencoder-based VC methods such as the use of hierarchical architectures, cyclic architectures, generative adversarial networks, speaker adversarial training, and neural vocoders. Moreover, it is possible to automatically estimate objective measures such as mel-cepstrum distortion and pseudo mean opinion score based on MOSNet. In this paper, we describe representative functions developed in crank and make brief comparisons by objective evaluations.
EMA2S: An End-to-End Multimodal Articulatory-to-Speech System
Feb 07, 2021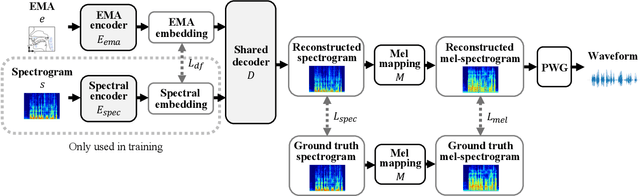
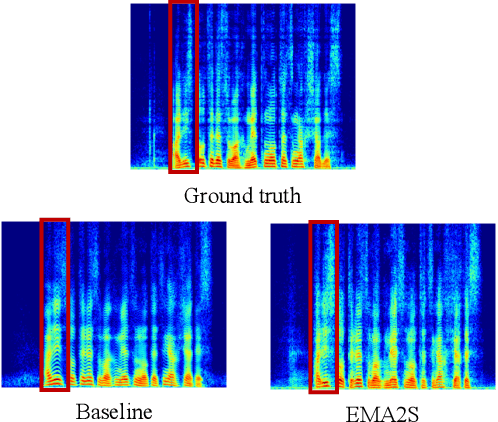
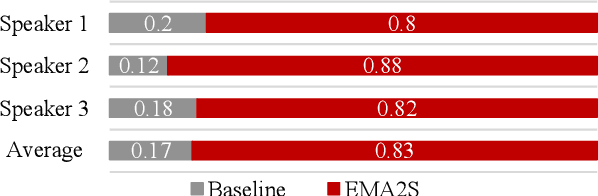
Synthesized speech from articulatory movements can have real-world use for patients with vocal cord disorders, situations requiring silent speech, or in high-noise environments. In this work, we present EMA2S, an end-to-end multimodal articulatory-to-speech system that directly converts articulatory movements to speech signals. We use a neural-network-based vocoder combined with multimodal joint-training, incorporating spectrogram, mel-spectrogram, and deep features. The experimental results confirm that the multimodal approach of EMA2S outperforms the baseline system in terms of both objective evaluation and subjective evaluation metrics. Moreover, results demonstrate that joint mel-spectrogram and deep feature loss training can effectively improve system performance.
Speech Recognition by Simply Fine-tuning BERT
Jan 30, 2021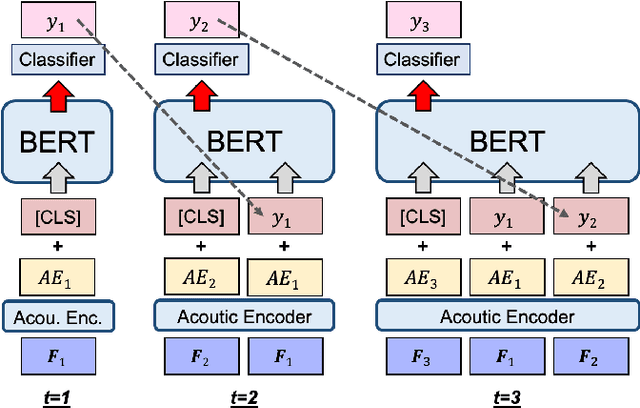
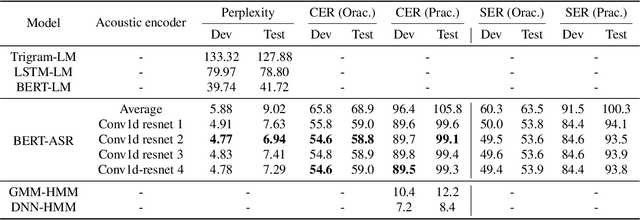
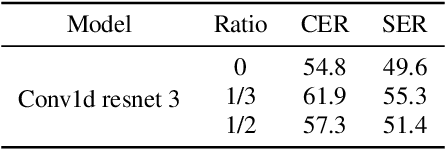
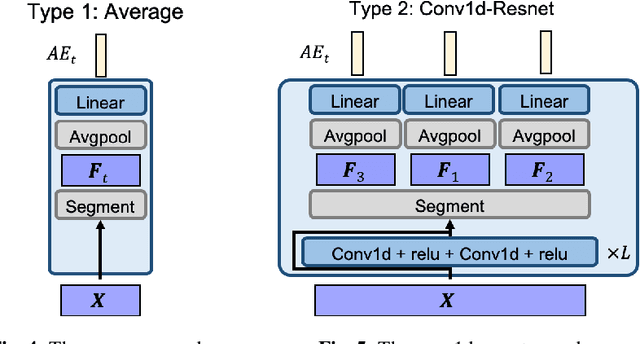
We propose a simple method for automatic speech recognition (ASR) by fine-tuning BERT, which is a language model (LM) trained on large-scale unlabeled text data and can generate rich contextual representations. Our assumption is that given a history context sequence, a powerful LM can narrow the range of possible choices and the speech signal can be used as a simple clue. Hence, comparing to conventional ASR systems that train a powerful acoustic model (AM) from scratch, we believe that speech recognition is possible by simply fine-tuning a BERT model. As an initial study, we demonstrate the effectiveness of the proposed idea on the AISHELL dataset and show that stacking a very simple AM on top of BERT can yield reasonable performance.
The 2020 ESPnet update: new features, broadened applications, performance improvements, and future plans
Dec 23, 2020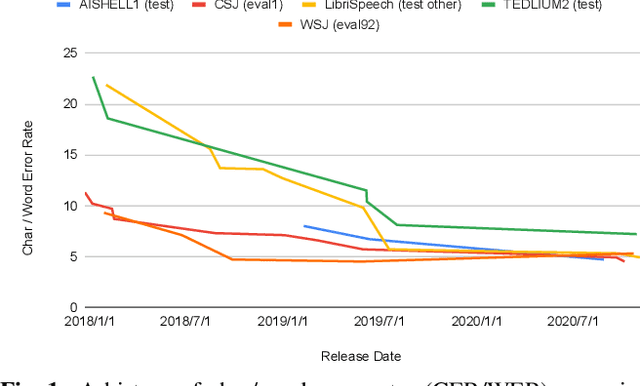

This paper describes the recent development of ESPnet (https://github.com/espnet/espnet), an end-to-end speech processing toolkit. This project was initiated in December 2017 to mainly deal with end-to-end speech recognition experiments based on sequence-to-sequence modeling. The project has grown rapidly and now covers a wide range of speech processing applications. Now ESPnet also includes text to speech (TTS), voice conversation (VC), speech translation (ST), and speech enhancement (SE) with support for beamforming, speech separation, denoising, and dereverberation. All applications are trained in an end-to-end manner, thanks to the generic sequence to sequence modeling properties, and they can be further integrated and jointly optimized. Also, ESPnet provides reproducible all-in-one recipes for these applications with state-of-the-art performance in various benchmarks by incorporating transformer, advanced data augmentation, and conformer. This project aims to provide up-to-date speech processing experience to the community so that researchers in academia and various industry scales can develop their technologies collaboratively.