 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximately optimal domain adaptation with Fisher's Linear Discriminant Analysis
Mar 14, 2023



We propose a class of models based on Fisher's Linear Discriminant (FLD) in the context of domain adaptation. The class is the convex combination of two hypotheses: i) an average hypothesis representing previously seen source tasks and ii) a hypothesis trained on a new target task. For a particular generative setting we derive the optimal convex combination of the two models under 0-1 loss, propose a computable approximation, and study the effect of various parameter settings on the relative risks between the optimal hypothesis, hypothesis i), and hypothesis ii). We demonstrate the effectiveness of the proposed optimal classifier in the context of EEG- and ECG-based classification settings and argue that the optimal classifier can be computed without access to direct information from any of the individual source tasks. We conclude by discussing further applications, limitations, and possible future directions.
Efficient Reinforcement Learning Through Trajectory Generation
Dec 01, 2022



A key barrier to using reinforcement learning (RL) in many real-world applications is the requirement of a large number of system interactions to learn a good control policy. Off-policy and Offline RL methods have been proposed to reduce the number of interactions with the physical environment by learning control policies from historical data. However, their performances suffer from the lack of exploration and the distributional shifts in trajectories once controllers are updated. Moreover, most RL methods require that all states are directly observed, which is difficult to be attained in many settings. To overcome these challenges, we propose a trajectory generation algorithm, which adaptively generates new trajectories as if the system is being operated and explored under the updated control policies. Motivated by the fundamental lemma for linear systems, assuming sufficient excitation, we generate trajectories from linear combinations of historical trajectories. For linear feedback control, we prove that the algorithm generates trajectories with the exact distribution as if they are sampled from the real system using the updated control policy. In particular, the algorithm extends to systems where the states are not directly observed. Experiments show that the proposed method significantly reduces the number of sampled data needed for RL algorithms.
Energy Efficient Design in IRS-Assisted UAV Data Collection System under Malicious Jamming
Aug 31, 2022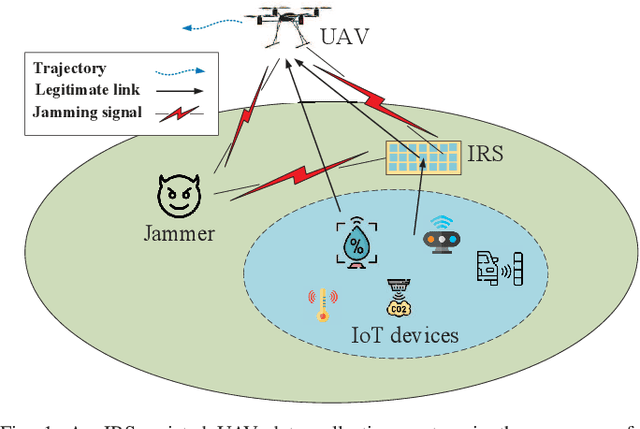
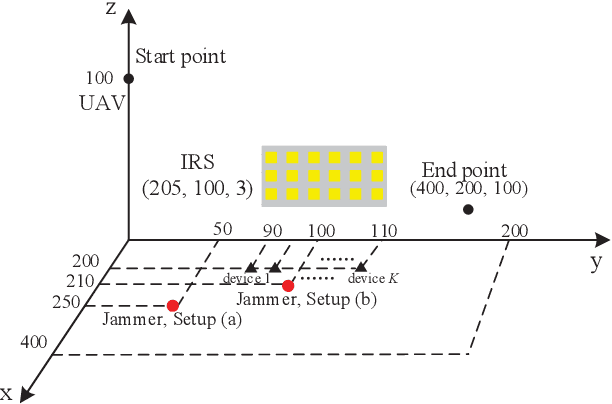
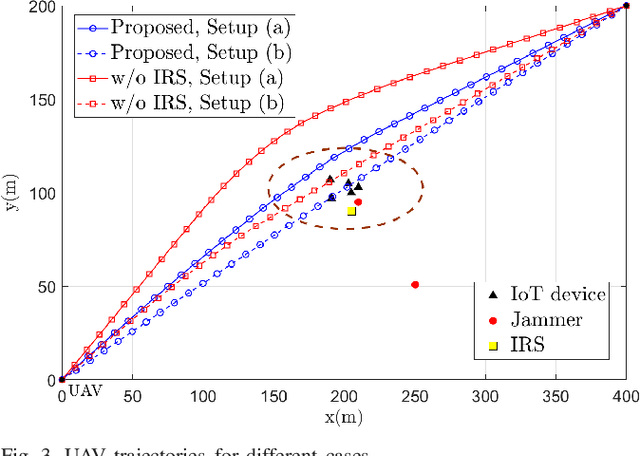
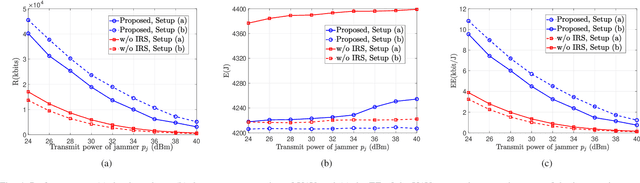
In this paper, we study an unmanned aerial vehicle (UAV) enabled data collection system, where an intelligent reflecting surface (IRS) is deployed to assist in the communication from a cluster of Internet-of-Things (IoT) devices to a UAV in the presence of a jammer. We aim to improve the energy efficiency (EE) via the joint design of UAV trajectory, IRS passive beamforming, device power allocation, and communication scheduling. However, the formulated non-linear fractional programming problem is challenging to solve due to its non-convexity and coupled variables. To overcome the difficulty, we propose an alternating optimization based algorithm to solve it sub-optimally by leveraging Dinkelbach's algorithm, successive convex approximation (SCA) technique, and block coordinate descent (BCD) method. Extensive simulation results show that the proposed design can significantly improve the anti-jamming performance. In particular, for the remote jammer case, the proposed design can largely shorten the flight path and thus decrease the energy consumption via the signal enhancement; while for the local jammer case, which is deemed highly challenging in conventional systems without IRS since the retreating away strategy becomes ineffective, our proposed design even achieves a higher performance gain owing to the efficient jamming signal mitigation.
Deep Learning with Label Noise: A Hierarchical Approach
May 28, 2022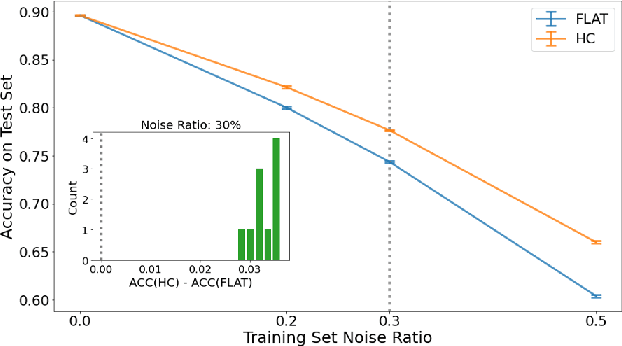
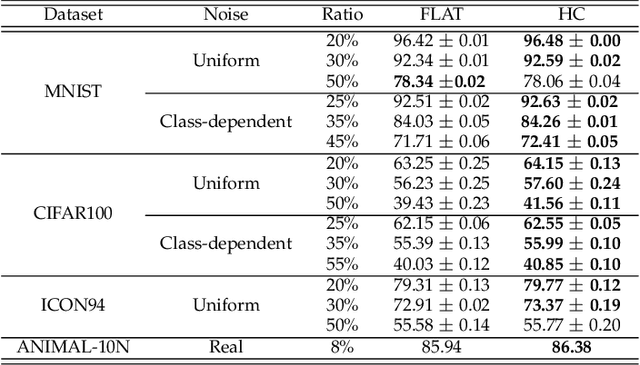
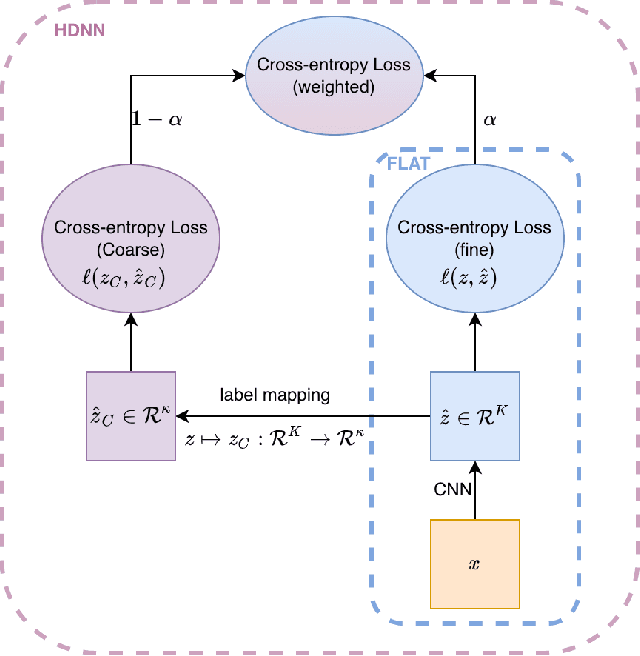
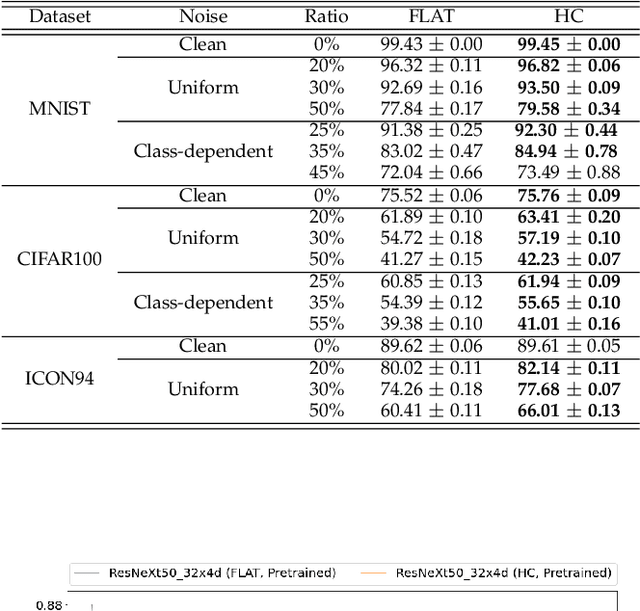
Deep neural networks are susceptible to label noise. Existing methods to improve robustness, such as meta-learning and regularization, usually require significant change to the network architecture or careful tuning of the optimization procedure. In this work, we propose a simple hierarchical approach that incorporates a label hierarchy when training the deep learning models. Our approach requires no change of the network architecture or the optimization procedure. We investigate our hierarchical network through a wide range of simulated and real datasets and various label noise types. Our hierarchical approach improves upon regular deep neural networks in learning with label noise. Combining our hierarchical approach with pre-trained models achieves state-of-the-art performance in real-world noisy datasets.
Mental State Classification Using Multi-graph Features
Feb 25, 2022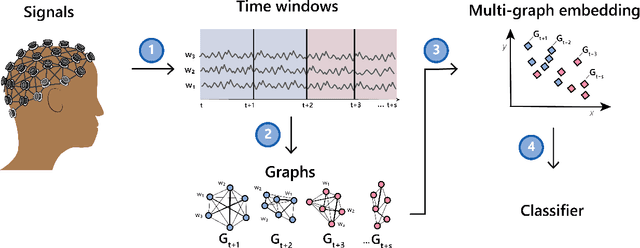
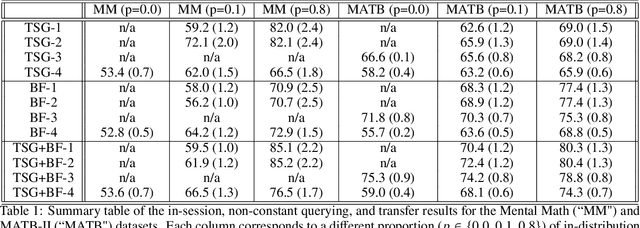
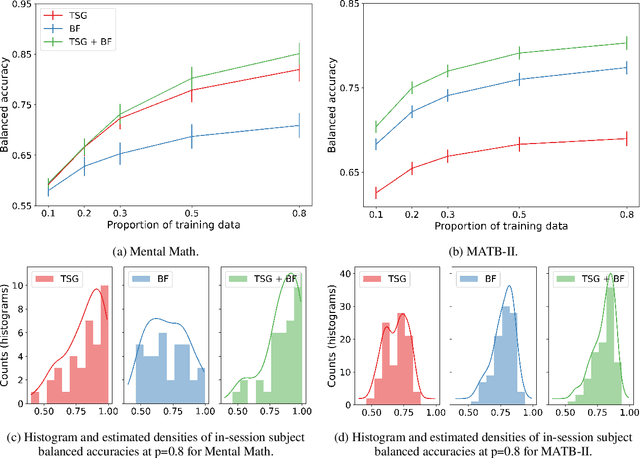
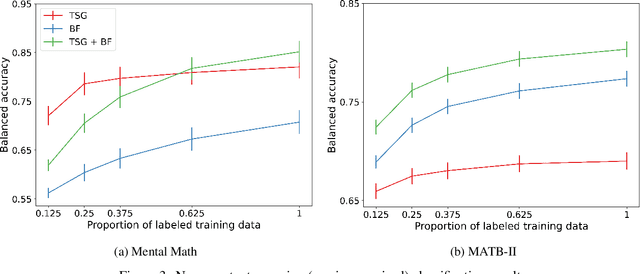
We consider the problem of extracting features from passive, multi-channel electroencephalogram (EEG) devices for downstream inference tasks related to high-level mental states such as stress and cognitive load. Our proposed method leverages recently developed multi-graph tools and applies them to the time series of graphs implied by the statistical dependence structure (e.g., correlation) amongst the multiple sensors. We compare the effectiveness of the proposed features to traditional band power-based features in the context of three classification experiments and find that the two feature sets offer complementary predictive information. We conclude by showing that the importance of particular channels and pairs of channels for classification when using the proposed features is neuroscientifically valid.
Prospective Learning: Back to the Future
Jan 19, 2022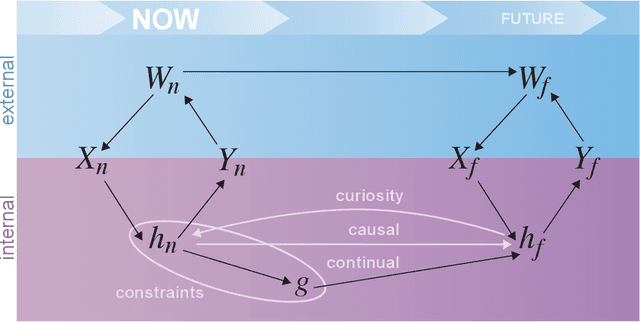

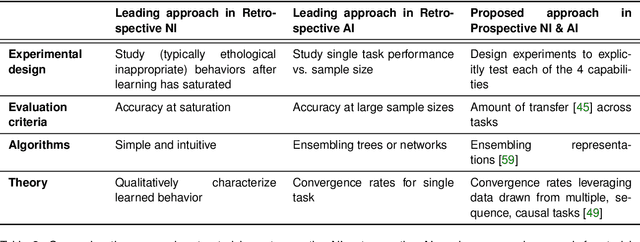
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
Leveraging semantically similar queries for ranking via combining representations
Jun 23, 2021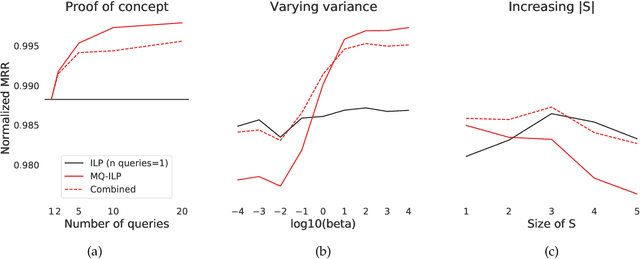
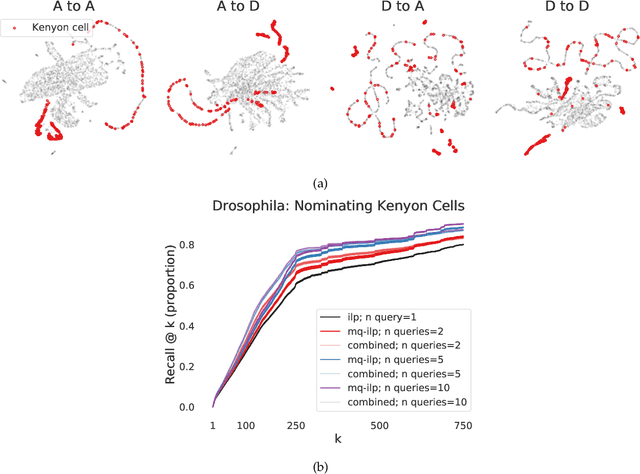
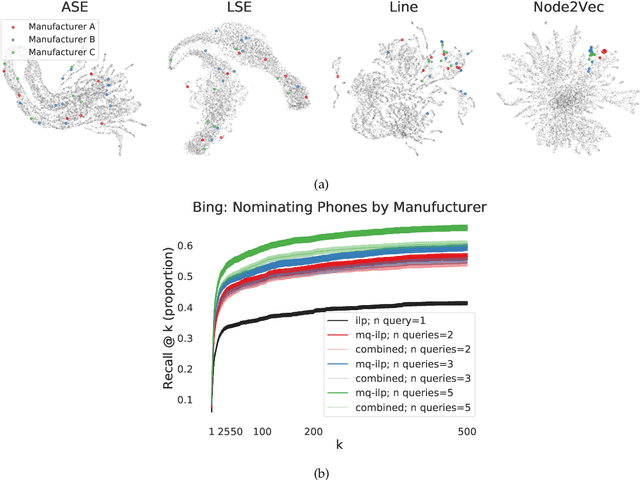
In modern ranking problems, different and disparate representations of the items to be ranked are often available. It is sensible, then, to try to combine these representations to improve ranking. Indeed, learning to rank via combining representations is both principled and practical for learning a ranking function for a particular query. In extremely data-scarce settings, however, the amount of labeled data available for a particular query can lead to a highly variable and ineffective ranking function. One way to mitigate the effect of the small amount of data is to leverage information from semantically similar queries. Indeed, as we demonstrate in simulation settings and real data examples, when semantically similar queries are available it is possible to gainfully use them when ranking with respect to a particular query. We describe and explore this phenomenon in the context of the bias-variance trade off and apply it to the data-scarce settings of a Bing navigational graph and the Drosophila larva connectome.
Learning without gradient descent encoded by the dynamics of a neurobiological model
Mar 23, 2021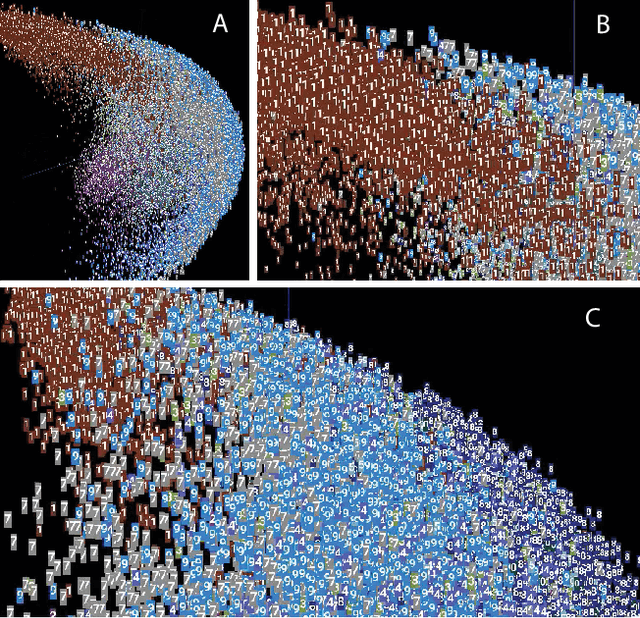
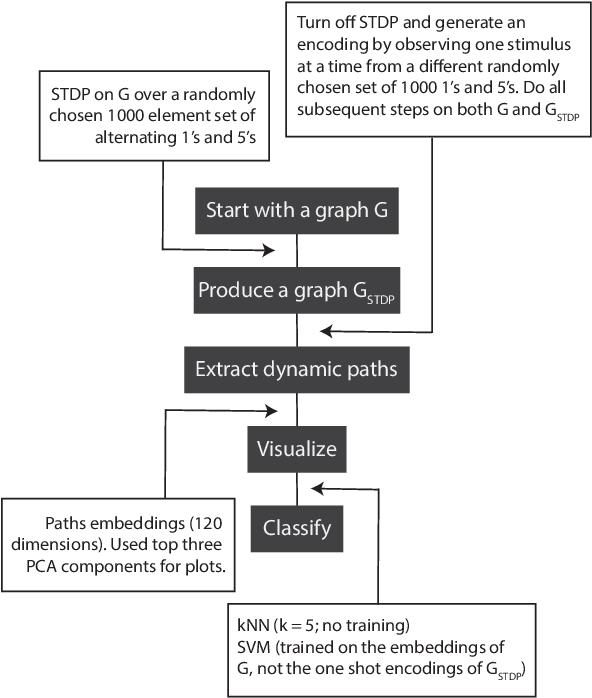
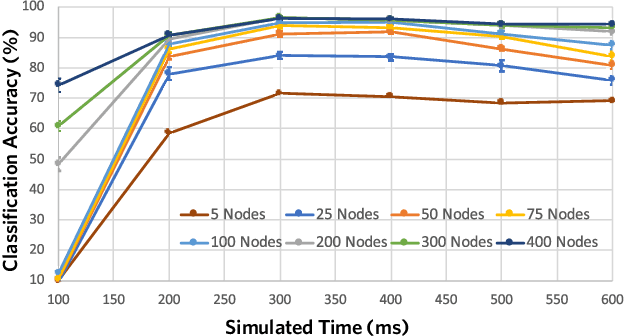
The success of state-of-the-art machine learning is essentially all based on different variations of gradient descent algorithms that minimize some version of a cost or loss function. A fundamental limitation, however, is the need to train these systems in either supervised or unsupervised ways by exposing them to typically large numbers of training examples. Here, we introduce a fundamentally novel conceptual approach to machine learning that takes advantage of a neurobiologically derived model of dynamic signaling, constrained by the geometric structure of a network. We show that MNIST images can be uniquely encoded and classified by the dynamics of geometric networks with nearly state-of-the-art accuracy in an unsupervised way, and without the need for any training.
Inducing a hierarchy for multi-class classification problems
Feb 20, 2021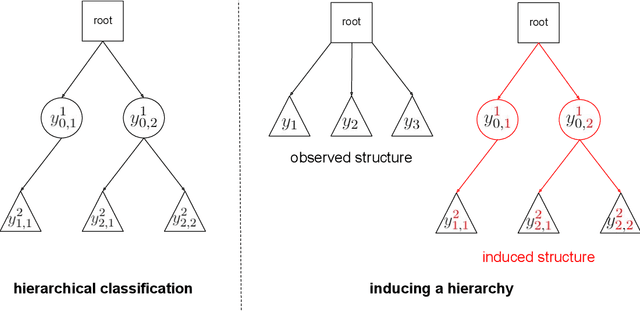
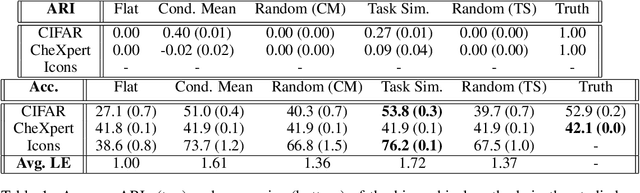
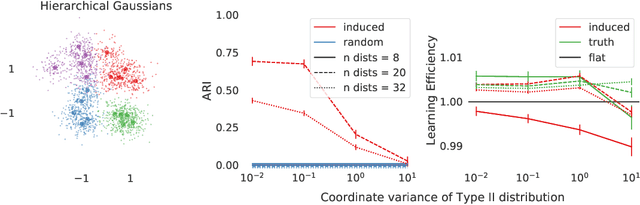
In applications where categorical labels follow a natural hierarchy, classification methods that exploit the label structure often outperform those that do not. Un-fortunately, the majority of classification datasets do not come pre-equipped with a hierarchical structure and classical flat classifiers must be employed. In this paper, we investigate a class of methods that induce a hierarchy that can similarly improve classification performance over flat classifiers. The class of methods follows the structure of first clustering the conditional distributions and subsequently using a hierarchical classifier with the induced hierarchy. We demonstrate the effectiveness of the class of methods both for discovering a latent hierarchy and for improving accuracy in principled simulation settings and three real data applications.
A partition-based similarity for classification distributions
Nov 12, 2020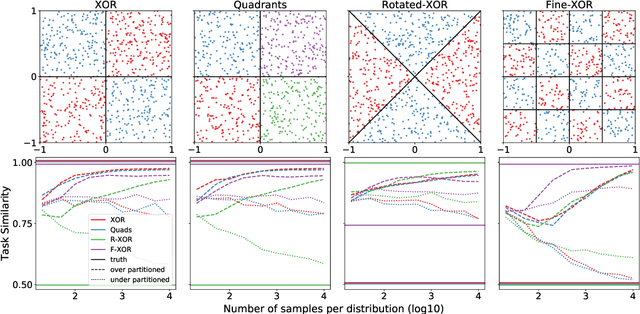
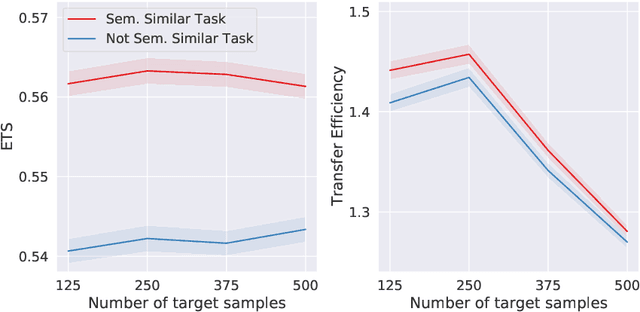
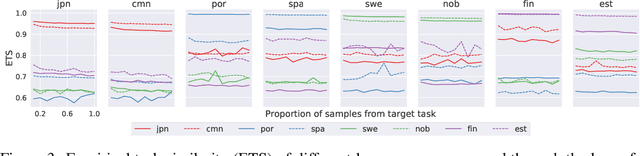
Herein we define a measure of similarity between classification distributions that is both principled from the perspective of statistical pattern recognition and useful from the perspective of machine learning practitioners. In particular, we propose a novel similarity on classification distributions, dubbed task similarity, that quantifies how an optimally-transformed optimal representation for a source distribution performs when applied to inference related to a target distribution. The definition of task similarity allows for natural definitions of adversarial and orthogonal distributions. We highlight limiting properties of representations induced by (universally) consistent decision rules and demonstrate in simulation that an empirical estimate of task similarity is a function of the decision rule deployed for inference. We demonstrate that for a given target distribution, both transfer efficiency and semantic similarity of candidate source distributions correlate with empirical task similarity.