 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent estimation of generative model representations in the data kernel perspective space
Sep 25, 2024


Generative models, such as large language models and text-to-image diffusion models, produce relevant information when presented a query. Different models may produce different information when presented the same query. As the landscape of generative models evolves, it is important to develop techniques to study and analyze differences in model behaviour. In this paper we present novel theoretical results for embedding-based representations of generative models in the context of a set of queries. We establish sufficient conditions for the consistent estimation of the model embeddings in situations where the query set and the number of models grow.
Comparing Foundation Models using Data Kernels
May 18, 2023


Recent advances in self-supervised learning and neural network scaling have enabled the creation of large models, known as foundation models, which can be easily adapted to a wide range of downstream tasks. The current paradigm for comparing foundation models involves evaluating them with aggregate metrics on various benchmark datasets. This method of model comparison is heavily dependent on the chosen evaluation metric, which makes it unsuitable for situations where the ideal metric is either not obvious or unavailable. In this work, we present a methodology for directly comparing the embedding space geometry of foundation models, which facilitates model comparison without the need for an explicit evaluation metric. Our methodology is grounded in random graph theory and enables valid hypothesis testing of embedding similarity on a per-datum basis. Further, we demonstrate how our methodology can be extended to facilitate population level model comparison. In particular, we show how our framework can induce a manifold of models equipped with a distance function that correlates strongly with several downstream metrics. We remark on the utility of this population level model comparison as a first step towards a taxonomic science of foundation models.
Approximately optimal domain adaptation with Fisher's Linear Discriminant Analysis
Mar 14, 2023



We propose a class of models based on Fisher's Linear Discriminant (FLD) in the context of domain adaptation. The class is the convex combination of two hypotheses: i) an average hypothesis representing previously seen source tasks and ii) a hypothesis trained on a new target task. For a particular generative setting we derive the optimal convex combination of the two models under 0-1 loss, propose a computable approximation, and study the effect of various parameter settings on the relative risks between the optimal hypothesis, hypothesis i), and hypothesis ii). We demonstrate the effectiveness of the proposed optimal classifier in the context of EEG- and ECG-based classification settings and argue that the optimal classifier can be computed without access to direct information from any of the individual source tasks. We conclude by discussing further applications, limitations, and possible future directions.
Deep Learning with Label Noise: A Hierarchical Approach
May 28, 2022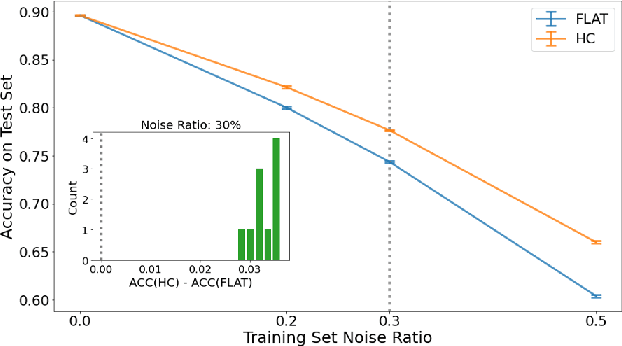
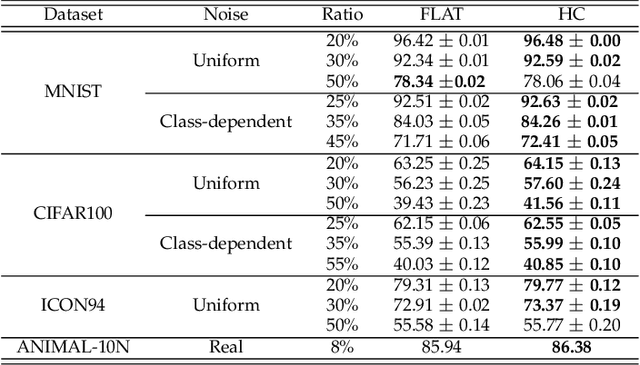
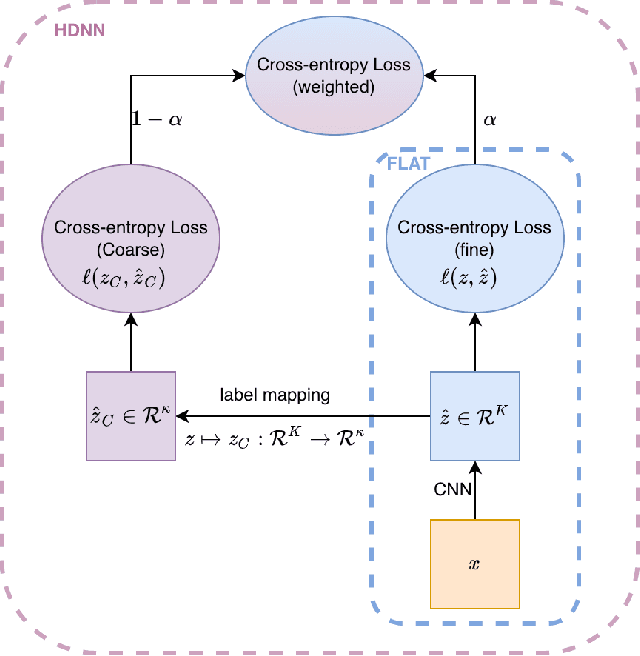
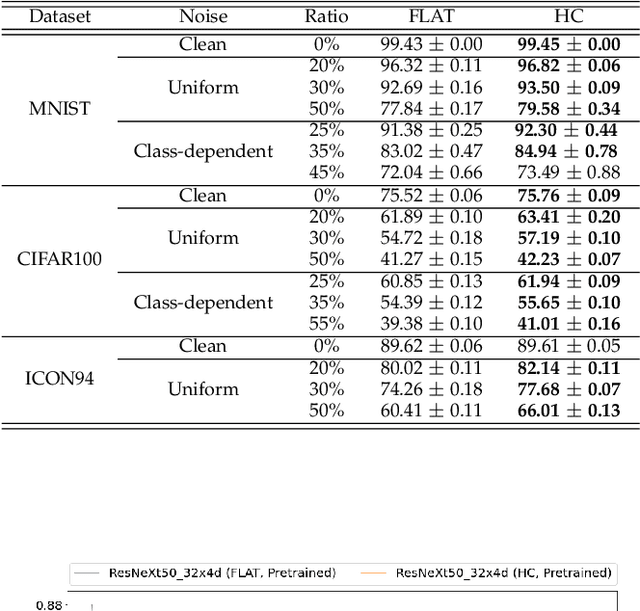
Deep neural networks are susceptible to label noise. Existing methods to improve robustness, such as meta-learning and regularization, usually require significant change to the network architecture or careful tuning of the optimization procedure. In this work, we propose a simple hierarchical approach that incorporates a label hierarchy when training the deep learning models. Our approach requires no change of the network architecture or the optimization procedure. We investigate our hierarchical network through a wide range of simulated and real datasets and various label noise types. Our hierarchical approach improves upon regular deep neural networks in learning with label noise. Combining our hierarchical approach with pre-trained models achieves state-of-the-art performance in real-world noisy datasets.
Mental State Classification Using Multi-graph Features
Feb 25, 2022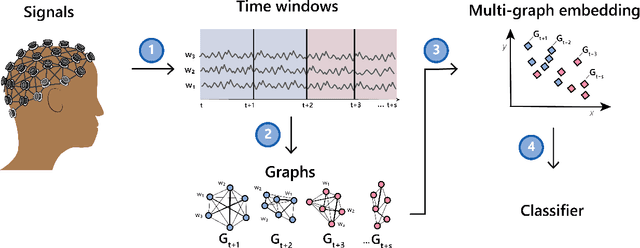
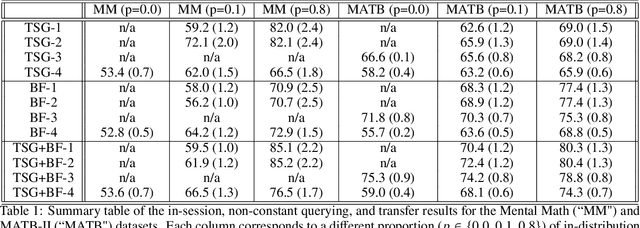
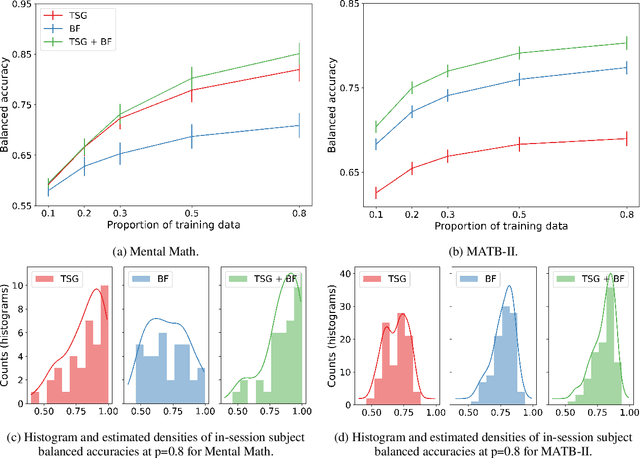
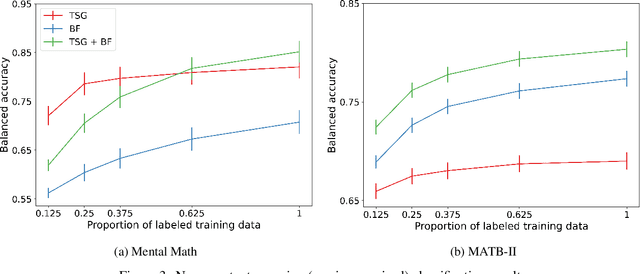
We consider the problem of extracting features from passive, multi-channel electroencephalogram (EEG) devices for downstream inference tasks related to high-level mental states such as stress and cognitive load. Our proposed method leverages recently developed multi-graph tools and applies them to the time series of graphs implied by the statistical dependence structure (e.g., correlation) amongst the multiple sensors. We compare the effectiveness of the proposed features to traditional band power-based features in the context of three classification experiments and find that the two feature sets offer complementary predictive information. We conclude by showing that the importance of particular channels and pairs of channels for classification when using the proposed features is neuroscientifically valid.
Towards a theory of out-of-distribution learning
Oct 07, 2021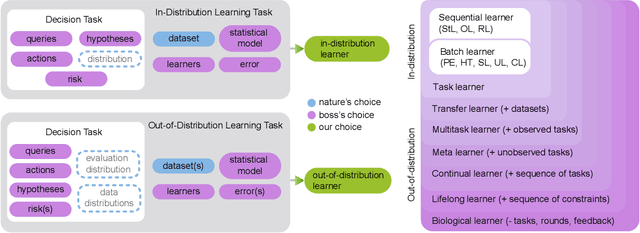
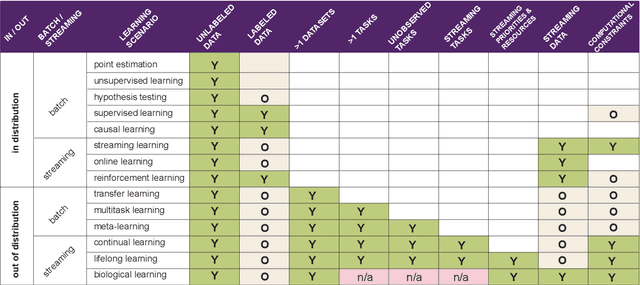
What is learning? 20$^{st}$ century formalizations of learning theory -- which precipitated revolutions in artificial intelligence -- focus primarily on $\mathit{in-distribution}$ learning, that is, learning under the assumption that the training data are sampled from the same distribution as the evaluation distribution. This assumption renders these theories inadequate for characterizing 21$^{st}$ century real world data problems, which are typically characterized by evaluation distributions that differ from the training data distributions (referred to as out-of-distribution learning). We therefore make a small change to existing formal definitions of learnability by relaxing that assumption. We then introduce $\mathbf{learning\ efficiency}$ (LE) to quantify the amount a learner is able to leverage data for a given problem, regardless of whether it is an in- or out-of-distribution problem. We then define and prove the relationship between generalized notions of learnability, and show how this framework is sufficiently general to characterize transfer, multitask, meta, continual, and lifelong learning. We hope this unification helps bridge the gap between empirical practice and theoretical guidance in real world problems. Finally, because biological learning continues to outperform machine learning algorithms on certain OOD challenges, we discuss the limitations of this framework vis-\'a-vis its ability to formalize biological learning, suggesting multiple avenues for future research.
Leveraging semantically similar queries for ranking via combining representations
Jun 23, 2021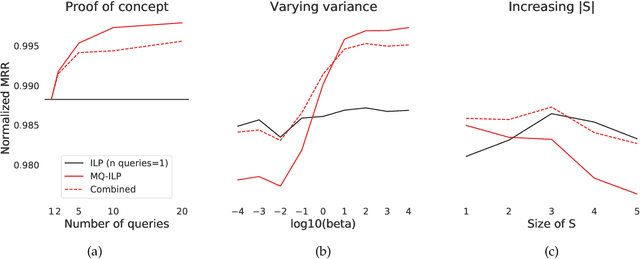
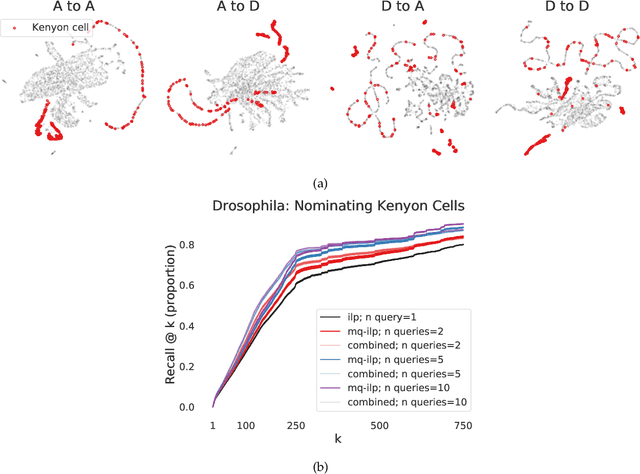
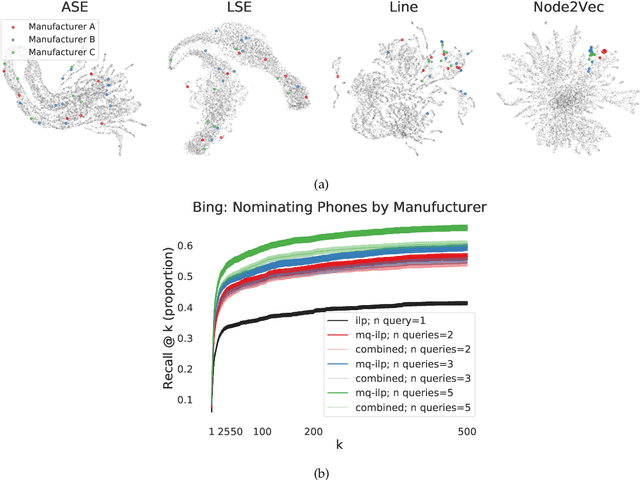
In modern ranking problems, different and disparate representations of the items to be ranked are often available. It is sensible, then, to try to combine these representations to improve ranking. Indeed, learning to rank via combining representations is both principled and practical for learning a ranking function for a particular query. In extremely data-scarce settings, however, the amount of labeled data available for a particular query can lead to a highly variable and ineffective ranking function. One way to mitigate the effect of the small amount of data is to leverage information from semantically similar queries. Indeed, as we demonstrate in simulation settings and real data examples, when semantically similar queries are available it is possible to gainfully use them when ranking with respect to a particular query. We describe and explore this phenomenon in the context of the bias-variance trade off and apply it to the data-scarce settings of a Bing navigational graph and the Drosophila larva connectome.
Inducing a hierarchy for multi-class classification problems
Feb 20, 2021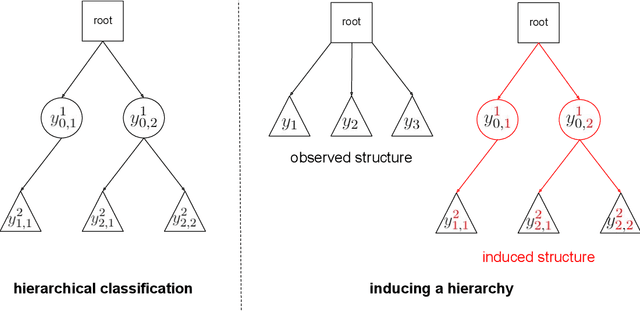
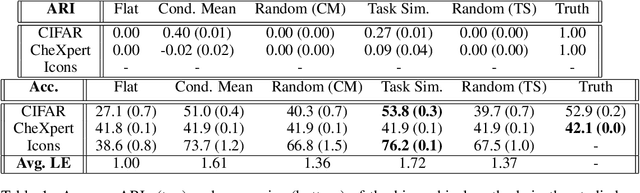
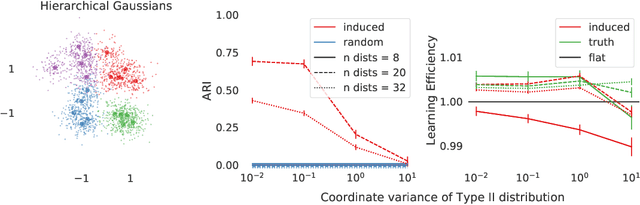
In applications where categorical labels follow a natural hierarchy, classification methods that exploit the label structure often outperform those that do not. Un-fortunately, the majority of classification datasets do not come pre-equipped with a hierarchical structure and classical flat classifiers must be employed. In this paper, we investigate a class of methods that induce a hierarchy that can similarly improve classification performance over flat classifiers. The class of methods follows the structure of first clustering the conditional distributions and subsequently using a hierarchical classifier with the induced hierarchy. We demonstrate the effectiveness of the class of methods both for discovering a latent hierarchy and for improving accuracy in principled simulation settings and three real data applications.
Subgraph nomination: Query by Example Subgraph Retrieval in Networks
Jan 29, 2021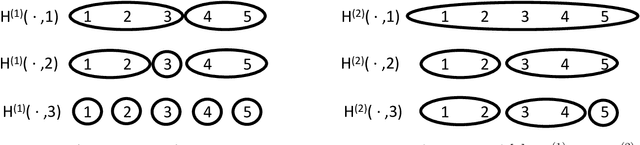
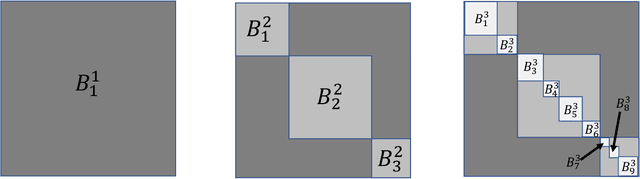
This paper introduces the subgraph nomination inference task, in which example subgraphs of interest are used to query a network for similarly interesting subgraphs. This type of problem appears time and again in real world problems connected to, for example, user recommendation systems and structural retrieval tasks in social and biological/connectomic networks. We formally define the subgraph nomination framework with an emphasis on the notion of a user-in-the-loop in the subgraph nomination pipeline. In this setting, a user can provide additional post-nomination light supervision that can be incorporated into the retrieval task. After introducing and formalizing the retrieval task, we examine the nuanced effect that user-supervision can have on performance, both analytically and across real and simulated data examples.
A partition-based similarity for classification distributions
Nov 12, 2020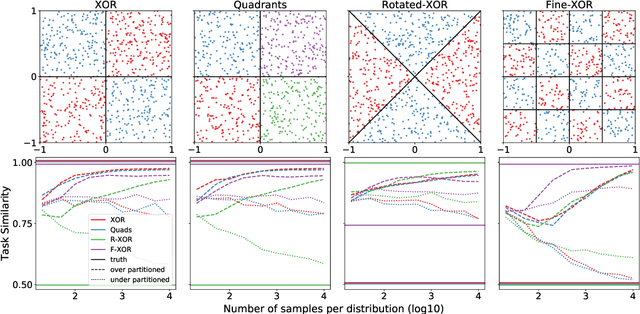
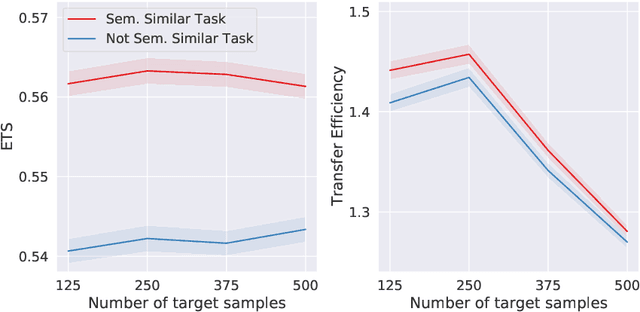
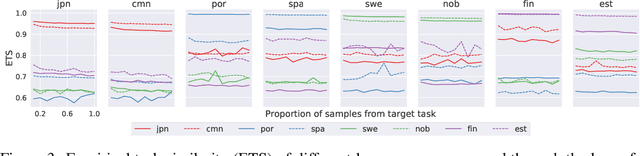
Herein we define a measure of similarity between classification distributions that is both principled from the perspective of statistical pattern recognition and useful from the perspective of machine learning practitioners. In particular, we propose a novel similarity on classification distributions, dubbed task similarity, that quantifies how an optimally-transformed optimal representation for a source distribution performs when applied to inference related to a target distribution. The definition of task similarity allows for natural definitions of adversarial and orthogonal distributions. We highlight limiting properties of representations induced by (universally) consistent decision rules and demonstrate in simulation that an empirical estimate of task similarity is a function of the decision rule deployed for inference. We demonstrate that for a given target distribution, both transfer efficiency and semantic similarity of candidate source distributions correlate with empirical task similarity.