 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Guarantees for Learning Branch-and-Cut Policies in Integer Programming
May 16, 2025Mixed-integer programming (MIP) provides a powerful framework for optimization problems, with Branch-and-Cut (B&C) being the predominant algorithm in state-of-the-art solvers. The efficiency of B&C critically depends on heuristic policies for making sequential decisions, including node selection, cut selection, and branching variable selection. While traditional solvers often employ heuristics with manually tuned parameters, recent approaches increasingly leverage machine learning, especially neural networks, to learn these policies directly from data. A key challenge is to understand the theoretical underpinnings of these learned policies, particularly their generalization performance from finite data. This paper establishes rigorous sample complexity bounds for learning B&C policies where the scoring functions guiding each decision step (node, cut, branch) have a certain piecewise polynomial structure. This structure generalizes the linear models that form the most commonly deployed policies in practice and investigated recently in a foundational series of theoretical works by Balcan et al. Such piecewise polynomial policies also cover the neural network architectures (e.g., using ReLU activations) that have been the focal point of contemporary practical studies. Consequently, our theoretical framework closely reflects the models utilized by practitioners investigating machine learning within B&C, offering a unifying perspective relevant to both established theory and modern empirical research in this area. Furthermore, our theory applies to quite general sequential decision making problems beyond B&C.
Learning Cut Generating Functions for Integer Programming
May 22, 2024



The branch-and-cut algorithm is the method of choice to solve large scale integer programming problems in practice. A key ingredient of branch-and-cut is the use of cutting planes which are derived constraints that reduce the search space for an optimal solution. Selecting effective cutting planes to produce small branch-and-cut trees is a critical challenge in the branch-and-cut algorithm. Recent advances have employed a data-driven approach to select optimal cutting planes from a parameterized family, aimed at reducing the branch-and-bound tree size (in expectation) for a given distribution of integer programming instances. We extend this idea to the selection of the best cut generating function (CGF), which is a tool in the integer programming literature for generating a wide variety of cutting planes that generalize the well-known Gomory Mixed-Integer (GMI) cutting planes. We provide rigorous sample complexity bounds for the selection of an effective CGF from certain parameterized families that provably performs well for any specified distribution on the problem instances. Our empirical results show that the selected CGF can outperform the GMI cuts for certain distributions. Additionally, we explore the sample complexity of using neural networks for instance-dependent CGF selection.
Data-driven algorithm design using neural networks with applications to branch-and-cut
Feb 04, 2024Data-driven algorithm design is a paradigm that uses statistical and machine learning techniques to select from a class of algorithms for a computational problem an algorithm that has the best expected performance with respect to some (unknown) distribution on the instances of the problem. We build upon recent work in this line of research by introducing the idea where, instead of selecting a single algorithm that has the best performance, we allow the possibility of selecting an algorithm based on the instance to be solved. In particular, given a representative sample of instances, we learn a neural network that maps an instance of the problem to the most appropriate algorithm {\em for that instance}. We formalize this idea and derive rigorous sample complexity bounds for this learning problem, in the spirit of recent work in data-driven algorithm design. We then apply this approach to the problem of making good decisions in the branch-and-cut framework for mixed-integer optimization (e.g., which cut to add?). In other words, the neural network will take as input a mixed-integer optimization instance and output a decision that will result in a small branch-and-cut tree for that instance. Our computational results provide evidence that our particular way of using neural networks for cut selection can make a significant impact in reducing branch-and-cut tree sizes, compared to previous data-driven approaches.
On the power of graph neural networks and the role of the activation function
Jul 10, 2023
In this article we present new results about the expressivity of Graph Neural Networks (GNNs). We prove that for any GNN with piecewise polynomial activations, whose architecture size does not grow with the graph input sizes, there exists a pair of non-isomorphic rooted trees of depth two such that the GNN cannot distinguish their root vertex up to an arbitrary number of iterations. The proof relies on tools from the algebra of symmetric polynomials. In contrast, it was already known that unbounded GNNs (those whose size is allowed to change with the graph sizes) with piecewise polynomial activations can distinguish these vertices in only two iterations. Our results imply a strict separation between bounded and unbounded size GNNs, answering an open question formulated by [Grohe, 2021]. We next prove that if one allows activations that are not piecewise polynomial, then in two iterations a single neuron perceptron can distinguish the root vertices of any pair of nonisomorphic trees of depth two (our results hold for activations like the sigmoid, hyperbolic tan and others). This shows how the power of graph neural networks can change drastically if one changes the activation function of the neural networks. The proof of this result utilizes the Lindemann-Weierstrauss theorem from transcendental number theory.
Neural networks with linear threshold activations: structure and algorithms
Nov 15, 2021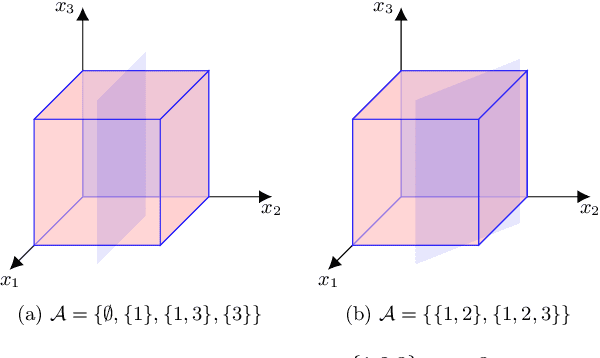
In this article we present new results on neural networks with linear threshold activation functions. We precisely characterize the class of functions that are representable by such neural networks and show that 2 hidden layers are necessary and sufficient to represent any function representable in the class. This is a surprising result in the light of recent exact representability investigations for neural networks using other popular activation functions like rectified linear units (ReLU). We also give precise bounds on the sizes of the neural networks required to represent any function in the class. Finally, we design an algorithm to solve the empirical risk minimization (ERM) problem to global optimality for these neural networks with a fixed architecture. The algorithm's running time is polynomial in the size of the data sample, if the input dimension and the size of the network architecture are considered fixed constants. The algorithm is unique in the sense that it works for any architecture with any number of layers, whereas previous polynomial time globally optimal algorithms work only for very restricted classes of architectures.
Leveraging semantically similar queries for ranking via combining representations
Jun 23, 2021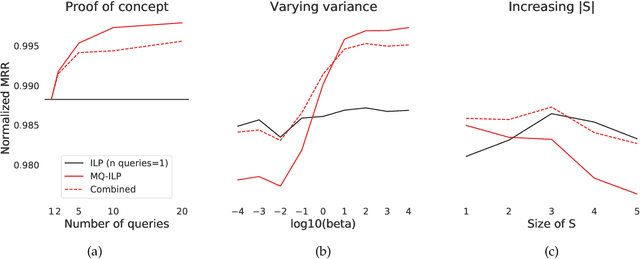
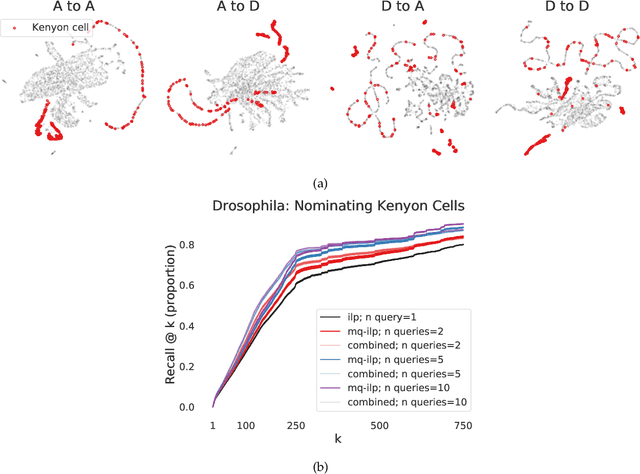
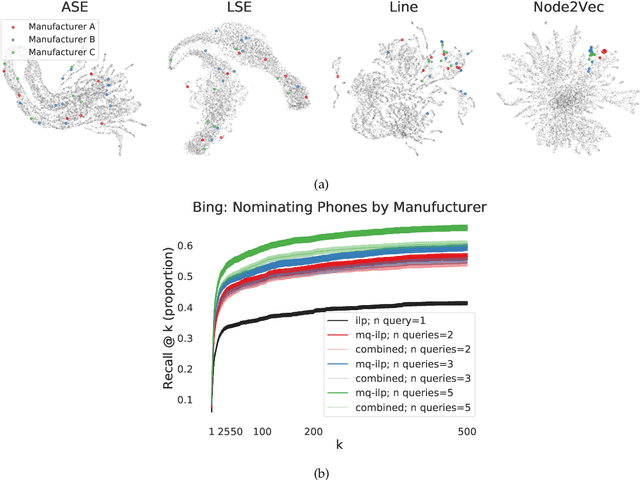
In modern ranking problems, different and disparate representations of the items to be ranked are often available. It is sensible, then, to try to combine these representations to improve ranking. Indeed, learning to rank via combining representations is both principled and practical for learning a ranking function for a particular query. In extremely data-scarce settings, however, the amount of labeled data available for a particular query can lead to a highly variable and ineffective ranking function. One way to mitigate the effect of the small amount of data is to leverage information from semantically similar queries. Indeed, as we demonstrate in simulation settings and real data examples, when semantically similar queries are available it is possible to gainfully use them when ranking with respect to a particular query. We describe and explore this phenomenon in the context of the bias-variance trade off and apply it to the data-scarce settings of a Bing navigational graph and the Drosophila larva connectome.
Towards Lower Bounds on the Depth of ReLU Neural Networks
May 31, 2021



We contribute to a better understanding of the class of functions that is represented by a neural network with ReLU activations and a given architecture. Using techniques from mixed-integer optimization, polyhedral theory, and tropical geometry, we provide a mathematical counterbalance to the universal approximation theorems which suggest that a single hidden layer is sufficient for learning tasks. In particular, we investigate whether the class of exactly representable functions strictly increases by adding more layers (with no restrictions on size). This problem has potential impact on algorithmic and statistical aspects because of the insight it provides into the class of functions represented by neural hypothesis classes. However, to the best of our knowledge, this question has not been investigated in the neural network literature. We also present upper bounds on the sizes of neural networks required to represent functions in these neural hypothesis classes.
Learning to rank via combining representations
May 20, 2020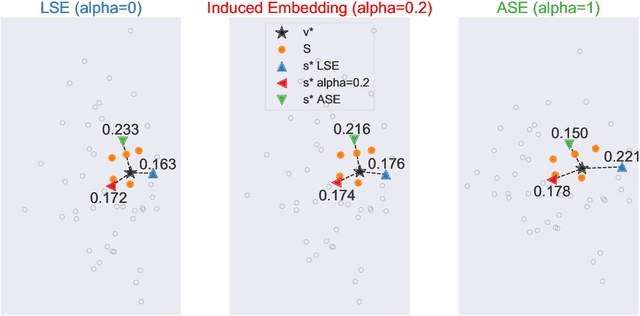
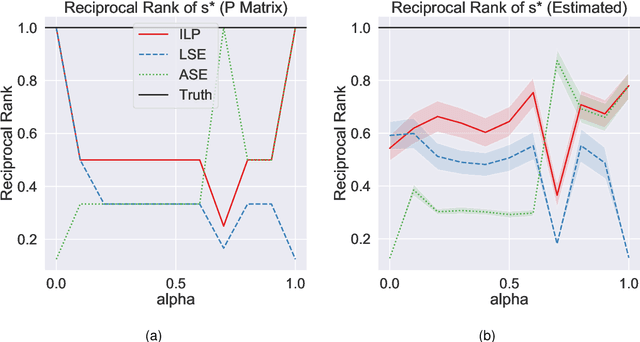
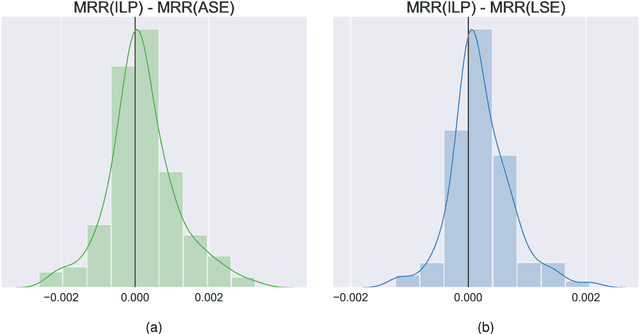
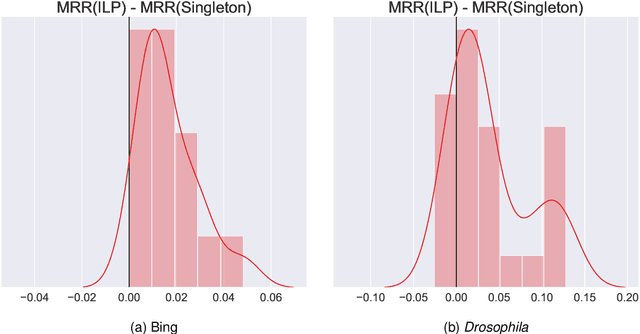
Learning to rank -- producing a ranked list of items specific to a query and with respect to a set of supervisory items -- is a problem of general interest. The setting we consider is one in which no analytic description of what constitutes a good ranking is available. Instead, we have a collection of representations and supervisory information consisting of a (target item, interesting items set) pair. We demonstrate -- analytically, in simulation, and in real data examples -- that learning to rank via combining representations using an integer linear program is effective when the supervision is as light as "these few items are similar to your item of interest." While this nomination task is of general interest, for specificity we present our methodology from the perspective of vertex nomination in graphs. The methodology described herein is model agnostic.
Understanding Deep Neural Networks with Rectified Linear Units
Feb 28, 2018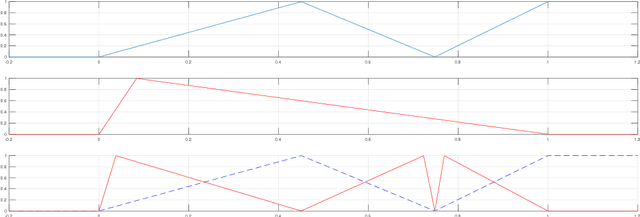
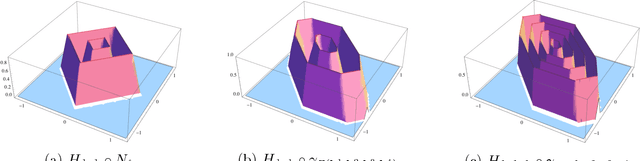
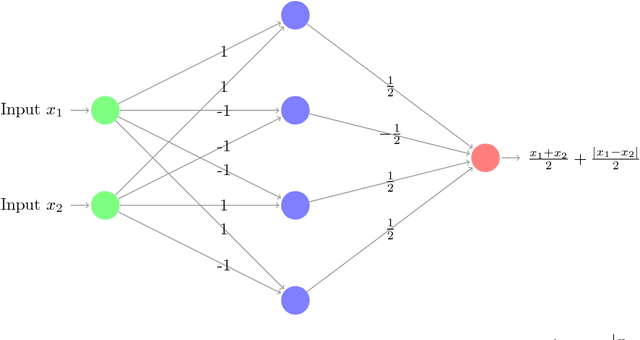
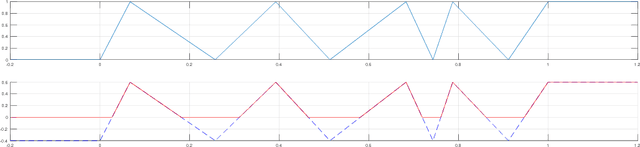
In this paper we investigate the family of functions representable by deep neural networks (DNN) with rectified linear units (ReLU). We give an algorithm to train a ReLU DNN with one hidden layer to *global optimality* with runtime polynomial in the data size albeit exponential in the input dimension. Further, we improve on the known lower bounds on size (from exponential to super exponential) for approximating a ReLU deep net function by a shallower ReLU net. Our gap theorems hold for smoothly parametrized families of "hard" functions, contrary to countable, discrete families known in the literature. An example consequence of our gap theorems is the following: for every natural number $k$ there exists a function representable by a ReLU DNN with $k^2$ hidden layers and total size $k^3$, such that any ReLU DNN with at most $k$ hidden layers will require at least $\frac{1}{2}k^{k+1}-1$ total nodes. Finally, for the family of $\mathbb{R}^n\to \mathbb{R}$ DNNs with ReLU activations, we show a new lowerbound on the number of affine pieces, which is larger than previous constructions in certain regimes of the network architecture and most distinctively our lowerbound is demonstrated by an explicit construction of a *smoothly parameterized* family of functions attaining this scaling. Our construction utilizes the theory of zonotopes from polyhedral theory.
* The poly(data) exact training algorithm has been improved to now be applicable to any single hidden layer R^n-> R ReLU DNN and there is a cleaner pseudocode for it given on page 8. Also now on page 7 there is a more precise description about when and how the Zonotope construction improves on the Theorem 4 of this paper, arXiv:1402.1869
Lower bounds over Boolean inputs for deep neural networks with ReLU gates
Nov 09, 2017Motivated by the resurgence of neural networks in being able to solve complex learning tasks we undertake a study of high depth networks using ReLU gates which implement the function $x \mapsto \max\{0,x\}$. We try to understand the role of depth in such neural networks by showing size lowerbounds against such network architectures in parameter regimes hitherto unexplored. In particular we show the following two main results about neural nets computing Boolean functions of input dimension $n$, 1. We use the method of random restrictions to show almost linear, $\Omega(\epsilon^{2(1-\delta)}n^{1-\delta})$, lower bound for completely weight unrestricted LTF-of-ReLU circuits to match the Andreev function on at least $\frac{1}{2} +\epsilon$ fraction of the inputs for $\epsilon > \sqrt{2\frac{\log^{\frac {2}{2-\delta}}(n)}{n}}$ for any $\delta \in (0,\frac 1 2)$ 2. We use the method of sign-rank to show exponential in dimension lower bounds for ReLU circuits ending in a LTF gate and of depths upto $O(n^{\xi})$ with $\xi < \frac{1}{8}$ with some restrictions on the weights in the bottom most layer. All other weights in these circuits are kept unrestricted. This in turns also implies the same lowerbounds for LTF circuits with the same architecture and the same weight restrictions on their bottom most layer. Along the way we also show that there exists a $\mathbb{R}^ n\rightarrow \mathbb{R}$ Sum-of-ReLU-of-ReLU function which Sum-of-ReLU neural nets can never represent no matter how large they are allowed to be.