 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Compression via Constrained Optimal Transport
Mar 13, 2024This paper presents a novel point cloud compression method COT-PCC by formulating the task as a constrained optimal transport (COT) problem. COT-PCC takes the bitrate of compressed features as an extra constraint of optimal transport (OT) which learns the distribution transformation between original and reconstructed points. Specifically, the formulated COT is implemented with a generative adversarial network (GAN) and a bitrate loss for training. The discriminator measures the Wasserstein distance between input and reconstructed points, and a generator calculates the optimal mapping between distributions of input and reconstructed point cloud. Moreover, we introduce a learnable sampling module for downsampling in the compression procedure. Extensive results on both sparse and dense point cloud datasets demonstrate that COT-PCC outperforms state-of-the-art methods in terms of both CD and PSNR metrics. Source codes are available at \url{https://github.com/cognaclee/PCC-COT}.
MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
Jan 09, 2024The growing demand for high-fidelity video generation from textual descriptions has catalyzed significant research in this field. In this work, we introduce MagicVideo-V2 that integrates the text-to-image model, video motion generator, reference image embedding module and frame interpolation module into an end-to-end video generation pipeline. Benefiting from these architecture designs, MagicVideo-V2 can generate an aesthetically pleasing, high-resolution video with remarkable fidelity and smoothness. It demonstrates superior performance over leading Text-to-Video systems such as Runway, Pika 1.0, Morph, Moon Valley and Stable Video Diffusion model via user evaluation at large scale.
MSECNet: Accurate and Robust Normal Estimation for 3D Point Clouds by Multi-Scale Edge Conditioning
Aug 23, 2023Estimating surface normals from 3D point clouds is critical for various applications, including surface reconstruction and rendering. While existing methods for normal estimation perform well in regions where normals change slowly, they tend to fail where normals vary rapidly. To address this issue, we propose a novel approach called MSECNet, which improves estimation in normal varying regions by treating normal variation modeling as an edge detection problem. MSECNet consists of a backbone network and a multi-scale edge conditioning (MSEC) stream. The MSEC stream achieves robust edge detection through multi-scale feature fusion and adaptive edge detection. The detected edges are then combined with the output of the backbone network using the edge conditioning module to produce edge-aware representations. Extensive experiments show that MSECNet outperforms existing methods on both synthetic (PCPNet) and real-world (SceneNN) datasets while running significantly faster. We also conduct various analyses to investigate the contribution of each component in the MSEC stream. Finally, we demonstrate the effectiveness of our approach in surface reconstruction.
P2Net: A Post-Processing Network for Refining Semantic Segmentation of LiDAR Point Cloud based on Consistency of Consecutive Frames
Dec 01, 2022We present a lightweight post-processing method to refine the semantic segmentation results of point cloud sequences. Most existing methods usually segment frame by frame and encounter the inherent ambiguity of the problem: based on a measurement in a single frame, labels are sometimes difficult to predict even for humans. To remedy this problem, we propose to explicitly train a network to refine these results predicted by an existing segmentation method. The network, which we call the P2Net, learns the consistency constraints between coincident points from consecutive frames after registration. We evaluate the proposed post-processing method both qualitatively and quantitatively on the SemanticKITTI dataset that consists of real outdoor scenes. The effectiveness of the proposed method is validated by comparing the results predicted by two representative networks with and without the refinement by the post-processing network. Specifically, qualitative visualization validates the key idea that labels of the points that are difficult to predict can be corrected with P2Net. Quantitatively, overall mIoU is improved from 10.5% to 11.7% for PointNet [1] and from 10.8% to 15.9% for PointNet++ [2].
Efficient stereo matching on embedded GPUs with zero-means cross correlation
Dec 01, 2022



Mobile stereo-matching systems have become an important part of many applications, such as automated-driving vehicles and autonomous robots. Accurate stereo-matching methods usually lead to high computational complexity; however, mobile platforms have only limited hardware resources to keep their power consumption low; this makes it difficult to maintain both an acceptable processing speed and accuracy on mobile platforms. To resolve this trade-off, we herein propose a novel acceleration approach for the well-known zero-means normalized cross correlation (ZNCC) matching cost calculation algorithm on a Jetson Tx2 embedded GPU. In our method for accelerating ZNCC, target images are scanned in a zigzag fashion to efficiently reuse one pixel's computation for its neighboring pixels; this reduces the amount of data transmission and increases the utilization of on-chip registers, thus increasing the processing speed. As a result, our method is 2X faster than the traditional image scanning method, and 26% faster than the latest NCC method. By combining this technique with the domain transformation (DT) algorithm, our system show real-time processing speed of 32 fps, on a Jetson Tx2 GPU for 1,280x384 pixel images with a maximum disparity of 128. Additionally, the evaluation results on the KITTI 2015 benchmark show that our combined system is more accurate than the same algorithm combined with census by 7.26%, while maintaining almost the same processing speed.
MagicVideo: Efficient Video Generation With Latent Diffusion Models
Nov 20, 2022We present an efficient text-to-video generation framework based on latent diffusion models, termed MagicVideo. Given a text description, MagicVideo can generate photo-realistic video clips with high relevance to the text content. With the proposed efficient latent 3D U-Net design, MagicVideo can generate video clips with 256x256 spatial resolution on a single GPU card, which is 64x faster than the recent video diffusion model (VDM). Unlike previous works that train video generation from scratch in the RGB space, we propose to generate video clips in a low-dimensional latent space. We further utilize all the convolution operator weights of pre-trained text-to-image generative U-Net models for faster training. To achieve this, we introduce two new designs to adapt the U-Net decoder to video data: a framewise lightweight adaptor for the image-to-video distribution adjustment and a directed temporal attention module to capture frame temporal dependencies. The whole generation process is within the low-dimension latent space of a pre-trained variation auto-encoder. We demonstrate that MagicVideo can generate both realistic video content and imaginary content in a photo-realistic style with a trade-off in terms of quality and computational cost. Refer to https://magicvideo.github.io/# for more examples.
Interpretable Edge Enhancement and Suppression Learning for 3D Point Cloud Segmentation
Sep 20, 2022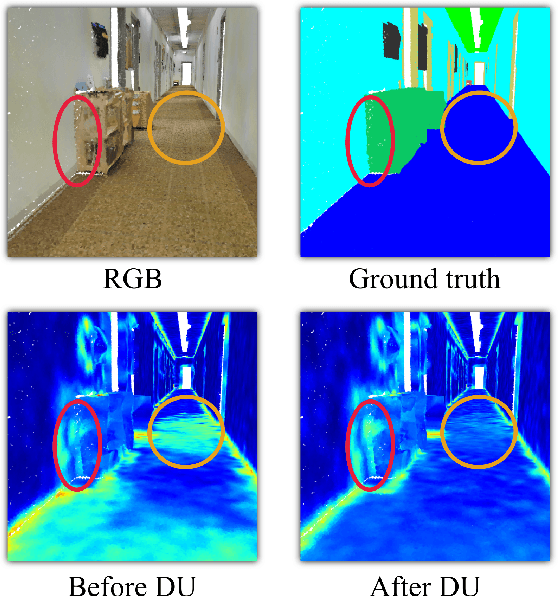
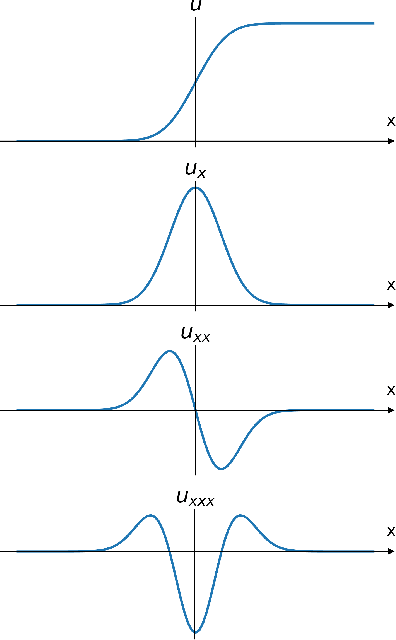
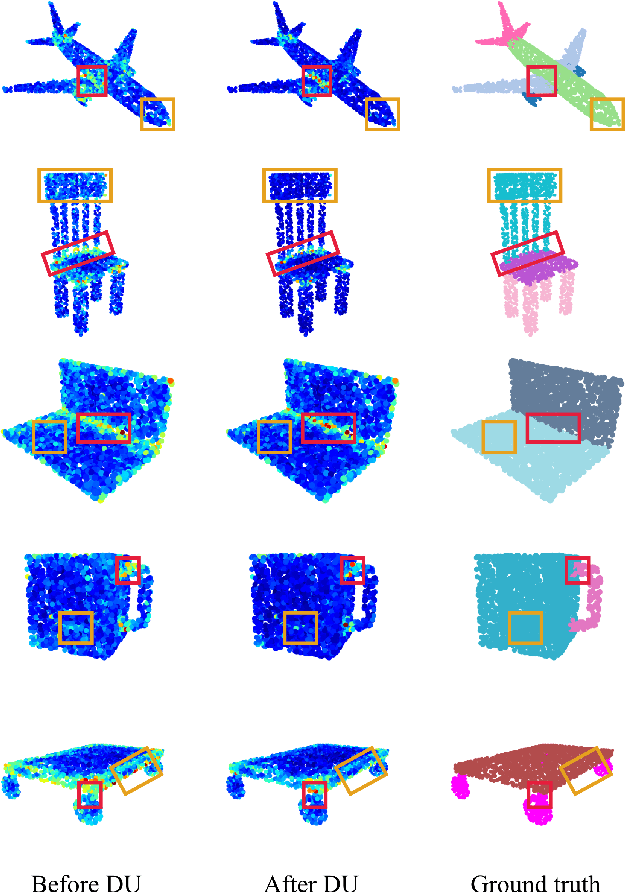
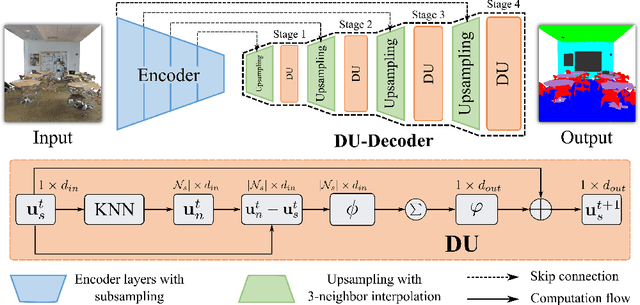
3D point clouds can flexibly represent continuous surfaces and can be used for various applications; however, the lack of structural information makes point cloud recognition challenging. Recent edge-aware methods mainly use edge information as an extra feature that describes local structures to facilitate learning. Although these methods show that incorporating edges into the network design is beneficial, they generally lack interpretability, making users wonder how exactly edges help. To shed light on this issue, in this study, we propose the Diffusion Unit (DU) that handles edges in an interpretable manner while providing decent improvement. Our method is interpretable in three ways. First, we theoretically show that DU learns to perform task-beneficial edge enhancement and suppression. Second, we experimentally observe and verify the edge enhancement and suppression behavior. Third, we empirically demonstrate that this behavior contributes to performance improvement. Extensive experiments performed on challenging benchmarks verify the superiority of DU in terms of both interpretability and performance gain. Specifically, our method achieves state-of-the-art performance in object part segmentation using ShapeNet part and scene segmentation using S3DIS. Our source code will be released at https://github.com/martianxiu/DiffusionUnit.
Surgical Skill Assessment via Video Semantic Aggregation
Aug 04, 2022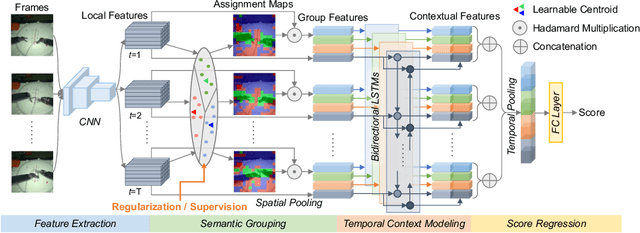
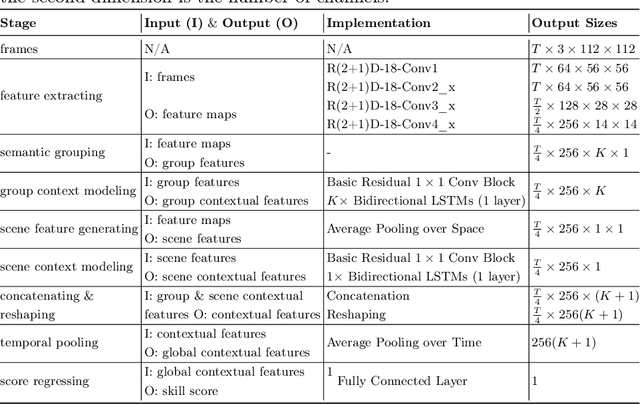
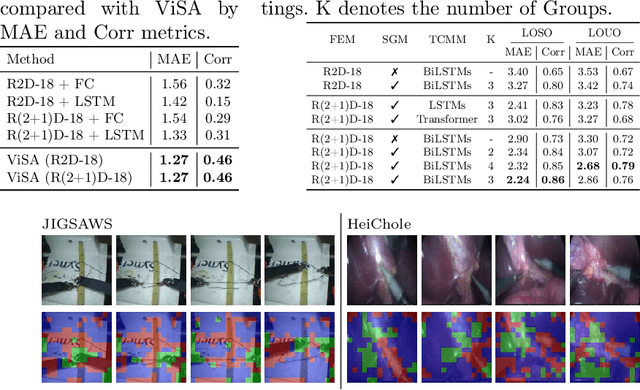
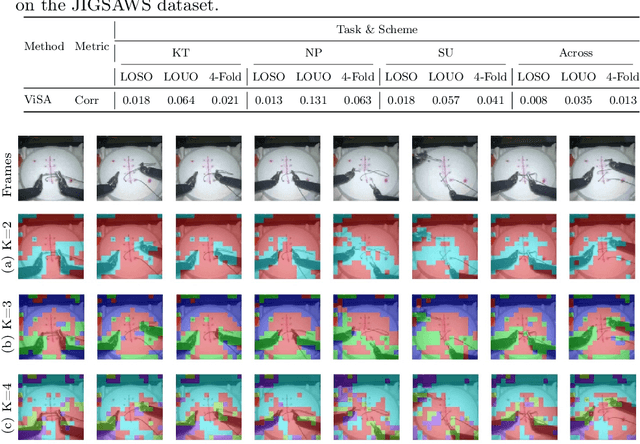
Automated video-based assessment of surgical skills is a promising task in assisting young surgical trainees, especially in poor-resource areas. Existing works often resort to a CNN-LSTM joint framework that models long-term relationships by LSTMs on spatially pooled short-term CNN features. However, this practice would inevitably neglect the difference among semantic concepts such as tools, tissues, and background in the spatial dimension, impeding the subsequent temporal relationship modeling. In this paper, we propose a novel skill assessment framework, Video Semantic Aggregation (ViSA), which discovers different semantic parts and aggregates them across spatiotemporal dimensions. The explicit discovery of semantic parts provides an explanatory visualization that helps understand the neural network's decisions. It also enables us to further incorporate auxiliary information such as the kinematic data to improve representation learning and performance. The experiments on two datasets show the competitiveness of ViSA compared to state-of-the-art methods. Source code is available at: bit.ly/MICCAI2022ViSA.
Enhancing Local Geometry Learning for 3D Point Cloud via Decoupling Convolution
Jul 04, 2022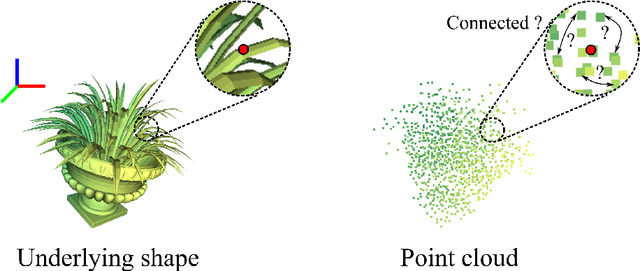
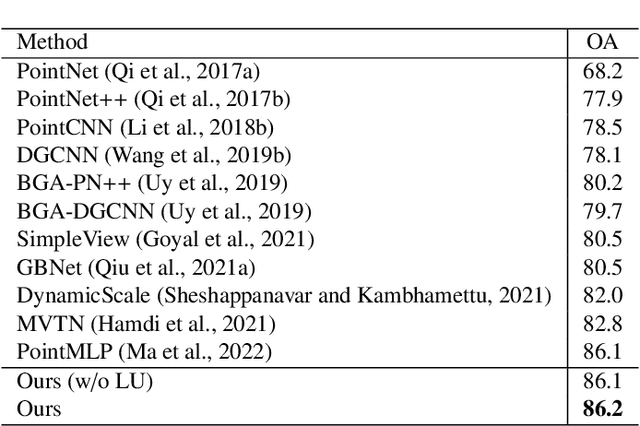
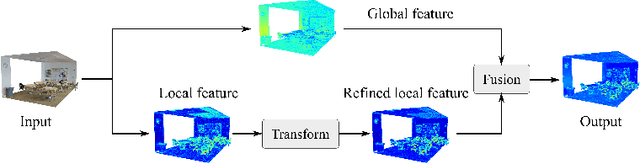
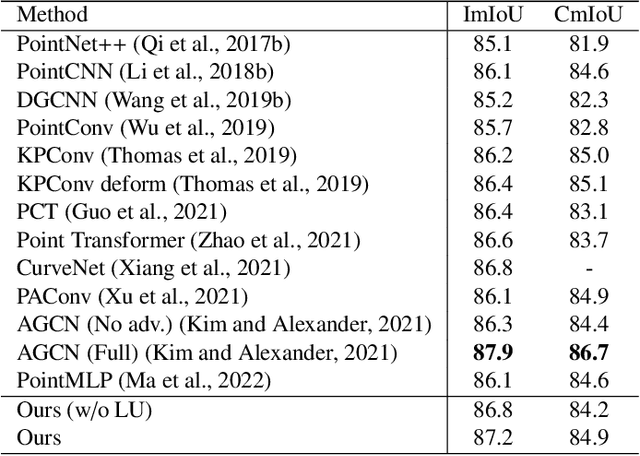
Modeling the local surface geometry is challenging in 3D point cloud understanding due to the lack of connectivity information. Most prior works model local geometry using various convolution operations. We observe that the convolution can be equivalently decomposed as a weighted combination of a local and a global component. With this observation, we explicitly decouple these two components so that the local one can be enhanced and facilitate the learning of local surface geometry. Specifically, we propose Laplacian Unit (LU), a simple yet effective architectural unit that can enhance the learning of local geometry. Extensive experiments demonstrate that networks equipped with LUs achieve competitive or superior performance on typical point cloud understanding tasks. Moreover, through establishing connections between the mean curvature flow, a further investigation of LU based on curvatures is made to interpret the adaptive smoothing and sharpening effect of LU. The code will be available.
Enhancing Local Feature Learning Using Diffusion for 3D Point Cloud Understanding
Jul 04, 2022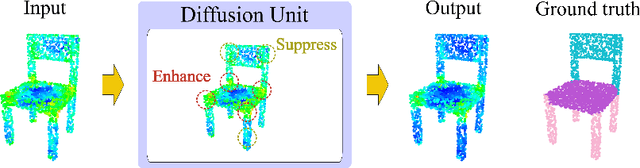
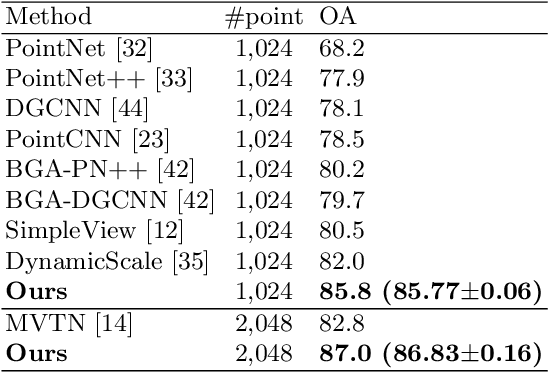
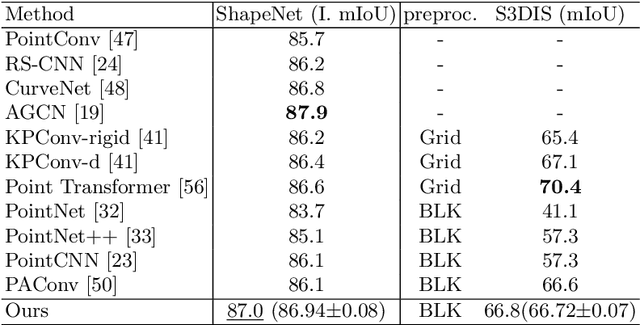

Learning point clouds is challenging due to the lack of connectivity information, i.e., edges. Although existing edge-aware methods can improve the performance by modeling edges, how edges contribute to the improvement is unclear. In this study, we propose a method that automatically learns to enhance/suppress edges while keeping the its working mechanism clear. First, we theoretically figure out how edge enhancement/suppression works. Second, we experimentally verify the edge enhancement/suppression behavior. Third, we empirically show that this behavior improves performance. In general, we observe that the proposed method achieves competitive performance in point cloud classification and segmentation tasks.