 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV4D:4D Convolutional Neural Networks for Video-level Representation Learning
Feb 18, 2020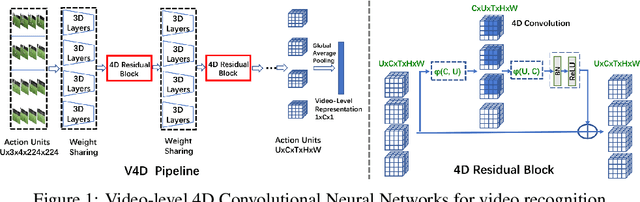

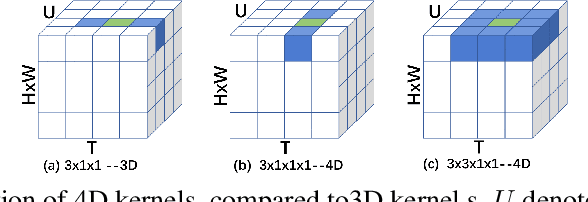
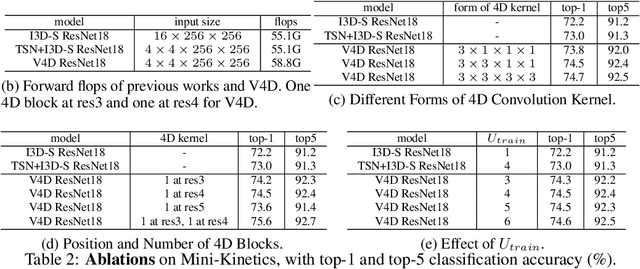
Most existing 3D CNNs for video representation learning are clip-based methods, and thus do not consider video-level temporal evolution of spatio-temporal features. In this paper, we propose Video-level 4D Convolutional Neural Networks, referred as V4D, to model the evolution of long-range spatio-temporal representation with 4D convolutions, and at the same time, to preserve strong 3D spatio-temporal representation with residual connections. Specifically, we design a new 4D residual block able to capture inter-clip interactions, which could enhance the representation power of the original clip-level 3D CNNs. The 4D residual blocks can be easily integrated into the existing 3D CNNs to perform long-range modeling hierarchically. We further introduce the training and inference methods for the proposed V4D. Extensive experiments are conducted on three video recognition benchmarks, where V4D achieves excellent results, surpassing recent 3D CNNs by a large margin.
Cross-Batch Memory for Embedding Learning
Dec 14, 2019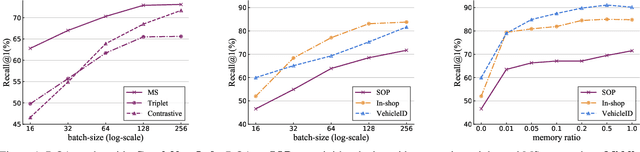

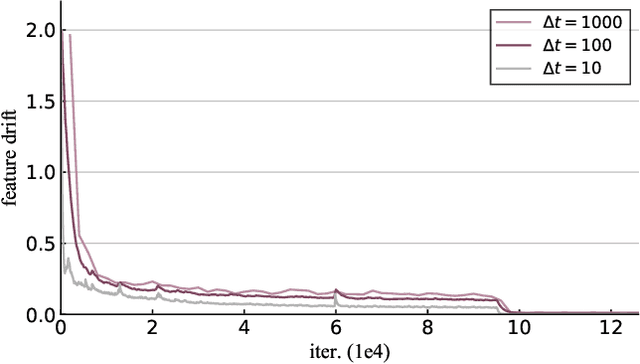
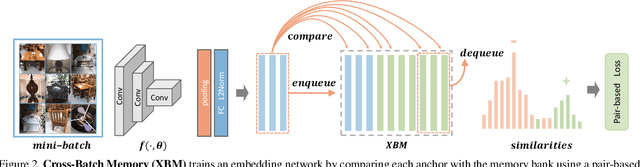
Mining informative negative instances are of central importance to deep metric learning (DML). However, the hard-mining ability of existing DML methods is intrinsically limited by mini-batch training, where only a mini-batch of instances are accessible at each iteration. In this paper, we identify a {"slow drift"} phenomena by observing that the embedding features drift exceptionally slow even as the model parameters are updating throughout the training process. It suggests that the features of instances computed at preceding iterations can considerably approximate to their features extracted by current model. We propose a cross-batch memory (XBM) mechanism that memorizes the embeddings of past iterations, allowing the model to collect sufficient hard negative pairs across multiple mini-batches - even over the whole dataset. Our XBM can be directly integrated into general pair-based DML framework. We demonstrate that, without bells and whistles, XBM augmented DML can boost the performance considerably on image retrieval. In particular, with XBM, a simple contrastive loss can have large R@1 improvements of 12\%-22.5\% on three large-scale datasets, easily surpassing the most sophisticated state-of-the-art methods by a large margin. Our XBM is conceptually simple, easy to implement - using several lines of codes, and is memory efficient - with a negligible 0.2 GB extra GPU memory.
Label-PEnet: Sequential Label Propagation and Enhancement Networks forWeakly Supervised Instance Segmentation
Oct 21, 2019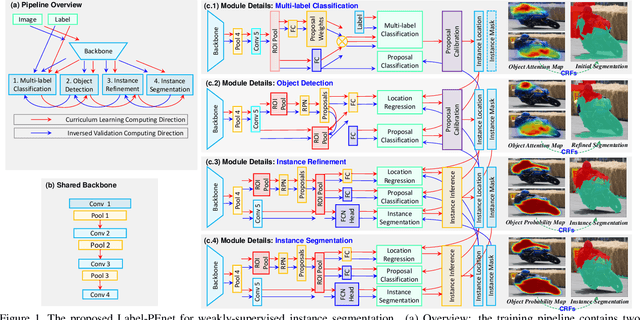
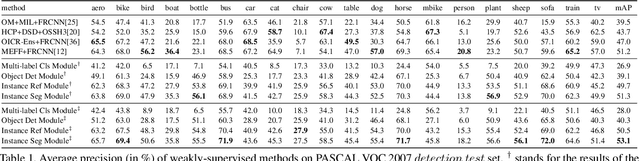
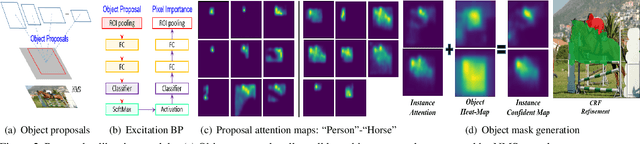

Weakly-supervised instance segmentation aims to detect and segment object instances precisely, given imagelevel labels only. Unlike previous methods which are composed of multiple offline stages, we propose Sequential Label Propagation and Enhancement Networks (referred as Label-PEnet) that progressively transform image-level labels to pixel-wise labels in a coarse-to-fine manner. We design four cascaded modules including multi-label classification, object detection, instance refinement and instance segmentation, which are implemented sequentially by sharing the same backbone. The cascaded pipeline is trained alternatively with a curriculum learning strategy that generalizes labels from high-level images to low-level pixels gradually with increasing accuracy. In addition, we design a proposal calibration module to explore the ability of classification networks to find key pixels that identify object parts, which serves as a post validation strategy running in the inverse order. We evaluate the efficiency of our Label-PEnet in mining instance masks on standard benchmarks: PASCAL VOC 2007 and 2012. Experimental results show that Label-PEnet outperforms the state-of-the-art algorithms by a clear margin, and obtains comparable performance even with the fully-supervised approaches.
Convolutional Character Networks
Oct 17, 2019
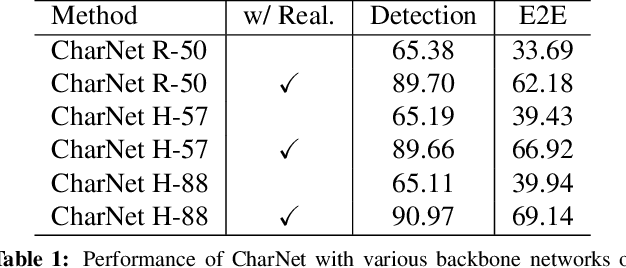
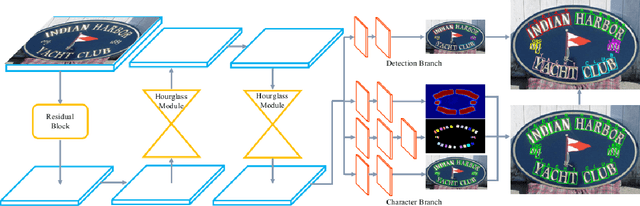
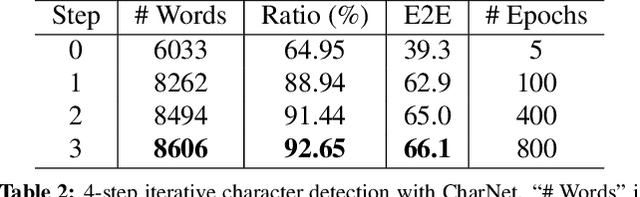
Recent progress has been made on developing a unified framework for joint text detection and recognition in natural images, but existing joint models were mostly built on two-stage framework by involving ROI pooling, which can degrade the performance on recognition task. In this work, we propose convolutional character networks, referred as CharNet, which is an one-stage model that can process two tasks simultaneously in one pass. CharNet directly outputs bounding boxes of words and characters, with corresponding character labels. We utilize character as basic element, allowing us to overcome the main difficulty of existing approaches that attempted to optimize text detection jointly with a RNN-based recognition branch. In addition, we develop an iterative character detection approach able to transform the ability of character detection learned from synthetic data to real-world images. These technical improvements result in a simple, compact, yet powerful one-stage model that works reliably on multi-orientation and curved text. We evaluate CharNet on three standard benchmarks, where it consistently outperforms the state-of-the-art approaches [25, 24] by a large margin, e.g., with improvements of 65.33%->71.08% (with generic lexicon) on ICDAR 2015, and 54.0%->69.23% on Total-Text, on end-to-end text recognition. Code is available at: https://github.com/MalongTech/research-charnet.
Dual-Stream Pyramid Registration Network
Sep 26, 2019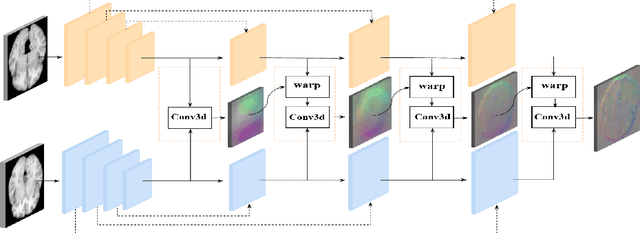
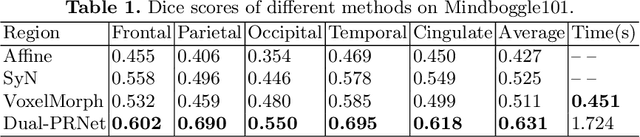
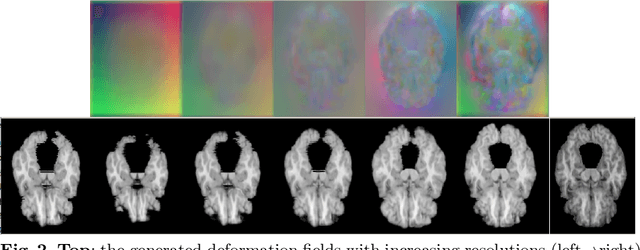
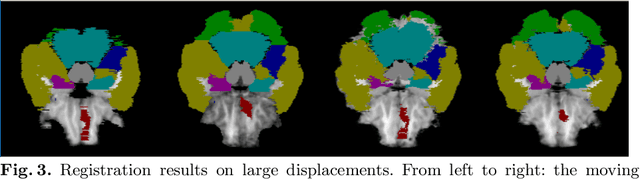
We propose a Dual-Stream Pyramid Registration Network (referred as Dual-PRNet) for unsupervised 3D medical image registration. Unlike recent CNN-based registration approaches, such as VoxelMorph, which explores a single-stream encoder-decoder network to compute a registration fields from a pair of 3D volumes, we design a two-stream architecture able to compute multi-scale registration fields from convolutional feature pyramids. Our contributions are two-fold: (i) we design a two-stream 3D encoder-decoder network which computes two convolutional feature pyramids separately for a pair of input volumes, resulting in strong deep representations that are meaningful for deformation estimation; (ii) we propose a pyramid registration module able to predict multi-scale registration fields directly from the decoding feature pyramids. This allows it to refine the registration fields gradually in a coarse-to-fine manner via sequential warping, and enable the model with the capability for handling significant deformations between two volumes, such as large displacements in spatial domain or slice space. The proposed Dual-PRNet is evaluated on two standard benchmarks for brain MRI registration, where it outperforms the state-of-the-art approaches by a large margin, e.g., having improvements over recent VoxelMorph [2] with 0.683->0.778 on the LPBA40, and 0.511->0.631 on the Mindboggle101, in term of average Dice score.
The iMaterialist Fashion Attribute Dataset
Jun 14, 2019
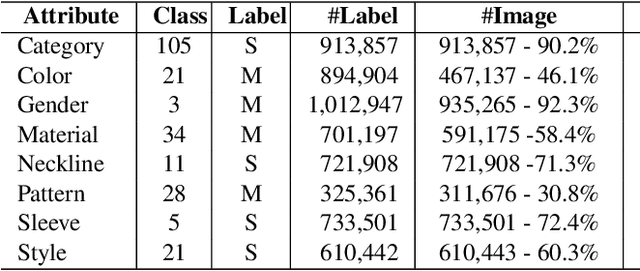
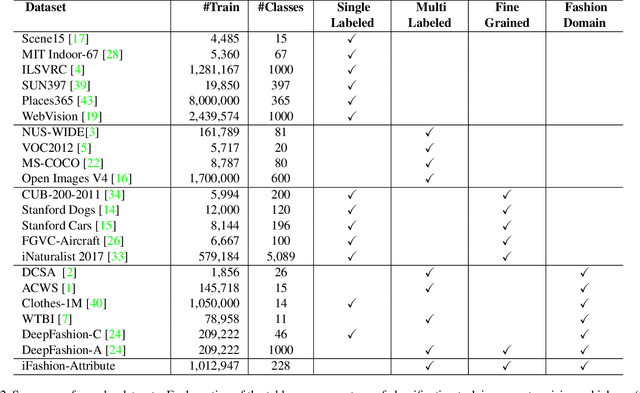
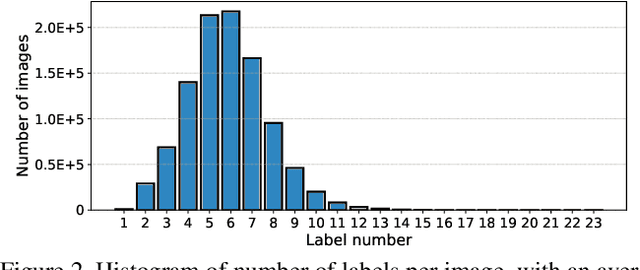
Large-scale image databases such as ImageNet have significantly advanced image classification and other visual recognition tasks. However much of these datasets are constructed only for single-label and coarse object-level classification. For real-world applications, multiple labels and fine-grained categories are often needed, yet very few such datasets exist publicly, especially those of large-scale and high quality. In this work, we contribute to the community a new dataset called iMaterialist Fashion Attribute (iFashion-Attribute) to address this problem in the fashion domain. The dataset is constructed from over one million fashion images with a label space that includes 8 groups of 228 fine-grained attributes in total. Each image is annotated by experts with multiple, high-quality fashion attributes. The result is the first known million-scale multi-label and fine-grained image dataset. We conduct extensive experiments and provide baseline results with modern deep Convolutional Neural Networks (CNNs). Additionally, we demonstrate models pre-trained on iFashion-Attribute achieve superior transfer learning performance on fashion related tasks compared with pre-training from ImageNet or other fashion datasets. Data is available at: https://github.com/visipedia/imat_fashion_comp
Multi-Similarity Loss with General Pair Weighting for Deep Metric Learning
May 11, 2019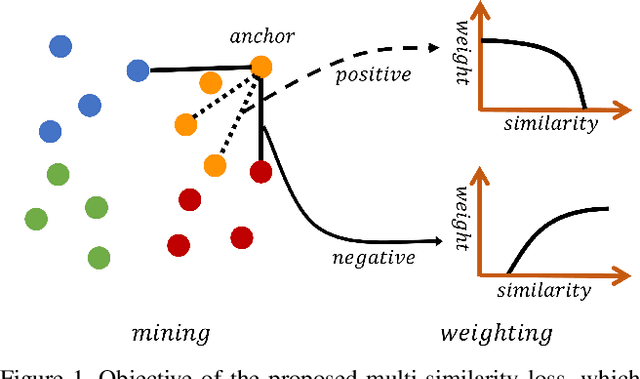

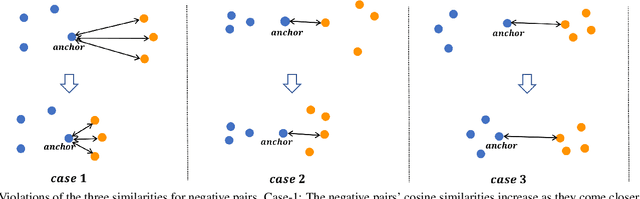
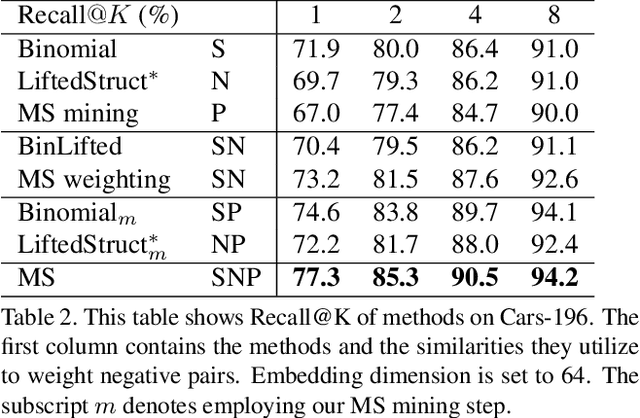
A family of loss functions built on pair-based computation have been proposed in the literature which provide a myriad of solutions for deep metric learning. In this paper, we provide a general weighting framework for understanding recent pair-based loss functions. Our contributions are three-fold: (1) we establish a General Pair Weighting (GPW) framework, which casts the sampling problem of deep metric learning into a unified view of pair weighting through gradient analysis, providing a powerful tool for understanding recent pair-based loss functions; (2) we show that with GPW, various existing pair-based methods can be compared and discussed comprehensively, with clear differences and key limitations identified; (3) we propose a new loss called multi-similarity loss (MS loss) under the GPW, which is implemented in two iterative steps (i.e., mining and weighting). This allows it to fully consider three similarities for pair weighting, providing a more principled approach for collecting and weighting informative pairs. Finally, the proposed MS loss obtains new state-of-the-art performance on four image retrieval benchmarks, where it outperforms the most recent approaches, such as ABE\cite{Kim_2018_ECCV} and HTL by a large margin: 60.6% to 65.7% on CUB200, and 80.9% to 88.0% on In-Shop Clothes Retrieval dataset at Recall@1. Code is available at https://github.com/MalongTech/research-ms-loss.
Compatible and Diverse Fashion Image Inpainting
Feb 04, 2019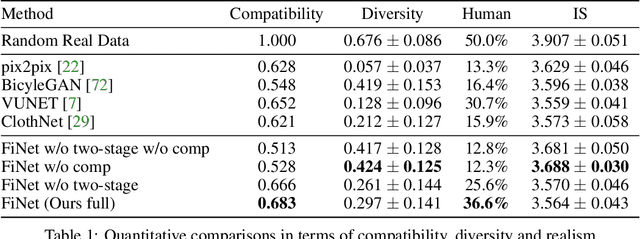
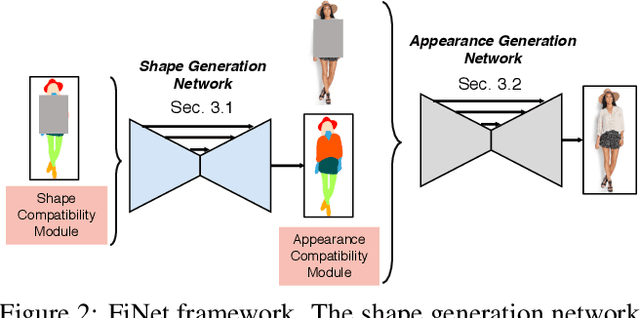
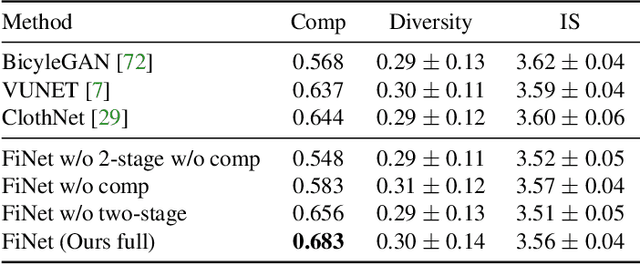
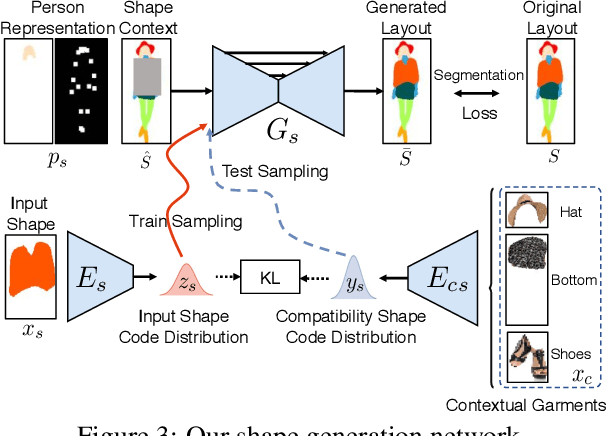
Visual compatibility is critical for fashion analysis, yet is missing in existing fashion image synthesis systems. In this paper, we propose to explicitly model visual compatibility through fashion image inpainting. To this end, we present Fashion Inpainting Networks (FiNet), a two-stage image-to-image generation framework that is able to perform compatible and diverse inpainting. Disentangling the generation of shape and appearance to ensure photorealistic results, our framework consists of a shape generation network and an appearance generation network. More importantly, for each generation network, we introduce two encoders interacting with one another to learn latent code in a shared compatibility space. The latent representations are jointly optimized with the corresponding generation network to condition the synthesis process, encouraging a diverse set of generated results that are visually compatible with existing fashion garments. In addition, our framework is readily extended to clothing reconstruction and fashion transfer, with impressive results. Extensive experiments with comparisons with state-of-the-art approaches on fashion synthesis task quantitatively and qualitatively demonstrate the effectiveness of our method.
CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images
Oct 18, 2018
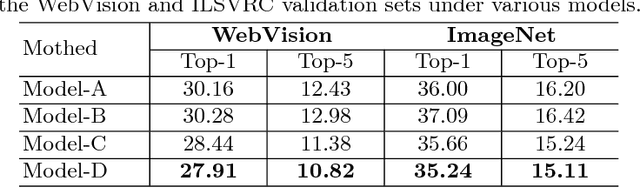
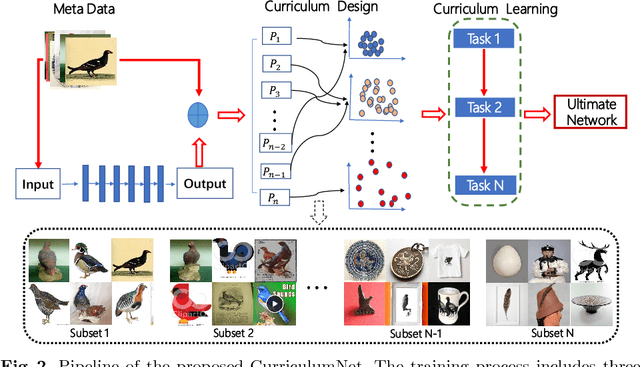

We present a simple yet efficient approach capable of training deep neural networks on large-scale weakly-supervised web images, which are crawled raw from the Internet by using text queries, without any human annotation. We develop a principled learning strategy by leveraging curriculum learning, with the goal of handling a massive amount of noisy labels and data imbalance effectively. We design a new learning curriculum by measuring the complexity of data using its distribution density in a feature space, and rank the complexity in an unsupervised manner. This allows for an efficient implementation of curriculum learning on large-scale web images, resulting in a high-performance CNN model, where the negative impact of noisy labels is reduced substantially. Importantly, we show by experiments that those images with highly noisy labels can surprisingly improve the generalization capability of the model, by serving as a manner of regularization. Our approaches obtain state-of-the-art performance on four benchmarks: WebVision, ImageNet, Clothing-1M and Food-101. With an ensemble of multiple models, we achieved a top-5 error rate of 5.2% on the WebVision challenge for 1000-category classification. This result was the top performance by a wide margin, outperforming second place by a nearly 50% relative error rate. Code and models are available at: https://github.com/MalongTech/CurriculumNet .
Deep Metric Learning with Hierarchical Triplet Loss
Oct 16, 2018
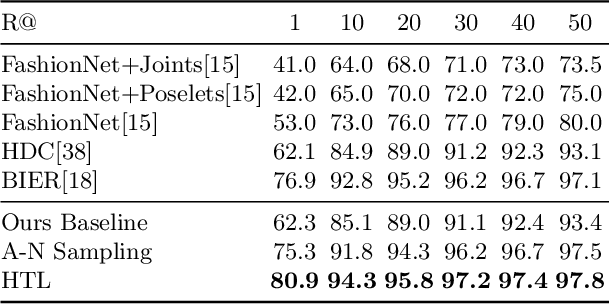
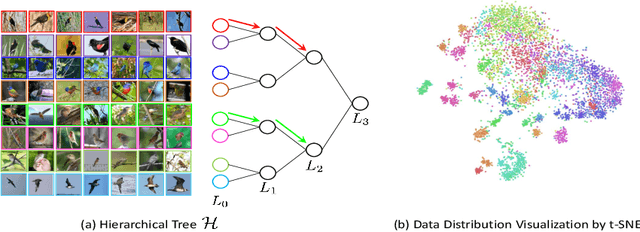
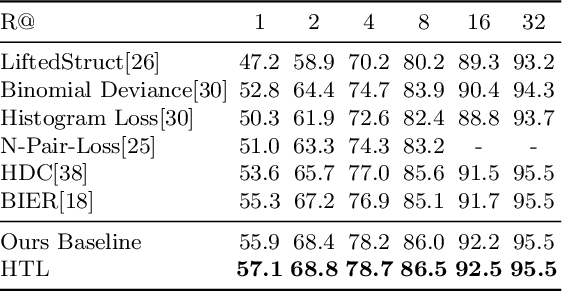
We present a novel hierarchical triplet loss (HTL) capable of automatically collecting informative training samples (triplets) via a defined hierarchical tree that encodes global context information. This allows us to cope with the main limitation of random sampling in training a conventional triplet loss, which is a central issue for deep metric learning. Our main contributions are two-fold. (i) we construct a hierarchical class-level tree where neighboring classes are merged recursively. The hierarchical structure naturally captures the intrinsic data distribution over the whole database. (ii) we formulate the problem of triplet collection by introducing a new violate margin, which is computed dynamically based on the designed hierarchical tree. This allows it to automatically select meaningful hard samples with the guide of global context. It encourages the model to learn more discriminative features from visual similar classes, leading to faster convergence and better performance. Our method is evaluated on the tasks of image retrieval and face recognition, where it outperforms the standard triplet loss substantially by 1%-18%. It achieves new state-of-the-art performance on a number of benchmarks, with much fewer learning iterations.