 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMBRAE: Unified Multimodal Decoding of Brain Signals
Apr 10, 2024
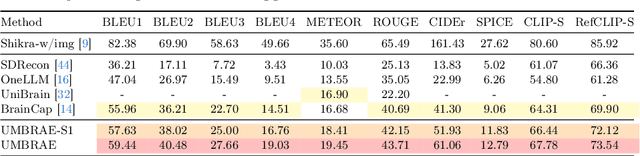
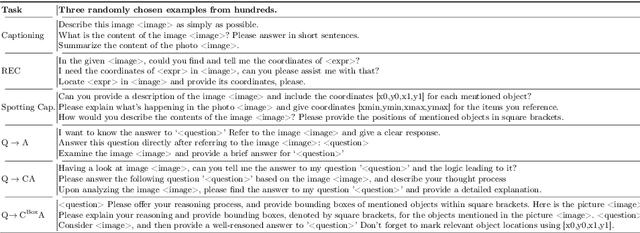
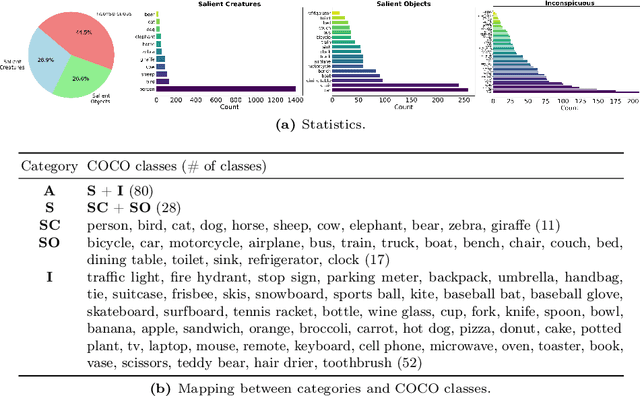
We address prevailing challenges of the brain-powered research, departing from the observation that the literature hardly recover accurate spatial information and require subject-specific models. To address these challenges, we propose UMBRAE, a unified multimodal decoding of brain signals. First, to extract instance-level conceptual and spatial details from neural signals, we introduce an efficient universal brain encoder for multimodal-brain alignment and recover object descriptions at multiple levels of granularity from subsequent multimodal large language model (MLLM). Second, we introduce a cross-subject training strategy mapping subject-specific features to a common feature space. This allows a model to be trained on multiple subjects without extra resources, even yielding superior results compared to subject-specific models. Further, we demonstrate this supports weakly-supervised adaptation to new subjects, with only a fraction of the total training data. Experiments demonstrate that UMBRAE not only achieves superior results in the newly introduced tasks but also outperforms methods in well established tasks. To assess our method, we construct and share with the community a comprehensive brain understanding benchmark BrainHub. Our code and benchmark are available at https://weihaox.github.io/UMBRAE.
DREAM: Visual Decoding from Reversing Human Visual System
Oct 03, 2023



In this work we present DREAM, an fMRI-to-image method for reconstructing viewed images from brain activities, grounded on fundamental knowledge of the human visual system. We craft reverse pathways that emulate the hierarchical and parallel nature of how humans perceive the visual world. These tailored pathways are specialized to decipher semantics, color, and depth cues from fMRI data, mirroring the forward pathways from visual stimuli to fMRI recordings. To do so, two components mimic the inverse processes within the human visual system: the Reverse Visual Association Cortex (R-VAC) which reverses pathways of this brain region, extracting semantics from fMRI data; the Reverse Parallel PKM (R-PKM) component simultaneously predicting color and depth from fMRI signals. The experiments indicate that our method outperforms the current state-of-the-art models in terms of the consistency of appearance, structure, and semantics. Code will be made publicly available to facilitate further research in this field.
A Survey on 3D-aware Image Synthesis
Oct 30, 2022



Recent years have seen remarkable progress in deep learning powered visual content creation. This includes 3D-aware generative image synthesis, which produces high-fidelity images in a 3D-consistent manner while simultaneously capturing compact surfaces of objects from pure image collections without the need for any 3D supervision, thus bridging the gap between 2D imagery and 3D reality. The 3D-aware generative models have shown that the introduction of 3D information can lead to more controllable image generation. The task of 3D-aware image synthesis has taken the field of computer vision by storm, with hundreds of papers accepted to top-tier journals and conferences in recent year (mainly the past two years), but there lacks a comprehensive survey of this remarkable and swift progress. Our survey aims to introduce new researchers to this topic, provide a useful reference for related works, and stimulate future research directions through our discussion section. Apart from the presented papers, we aim to constantly update the latest relevant papers along with corresponding implementations at https://weihaox.github.io/awesome-3D-aware-synthesis.
GAN Inversion for Consistent Video Interpolation and Manipulation
Aug 23, 2022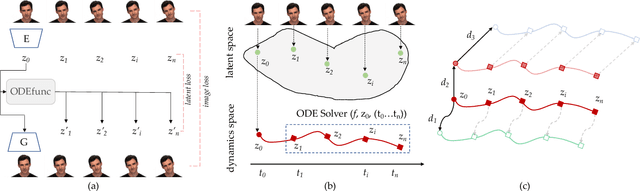

In this paper, we propose to model the video dynamics by learning the trajectory of independently inverted latent codes from GANs. The entire sequence is seen as discrete-time observations of a continuous trajectory of the initial latent code, by considering each latent code as a moving particle and the latent space as a high-dimensional dynamic system. The latent codes representing different frames are therefore reformulated as state transitions of the initial frame, which can be modeled by neural ordinary differential equations. The learned continuous trajectory allows us to perform infinite frame interpolation and consistent video manipulation. The latter task is reintroduced for video editing with the advantage of requiring the core operations to be applied to the first frame only while maintaining temporal consistency across all frames. Extensive experiments demonstrate that our method achieves state-of-the-art performance but with much less computation.
Learning Quality-aware Dynamic Memory for Video Object Segmentation
Jul 16, 2022
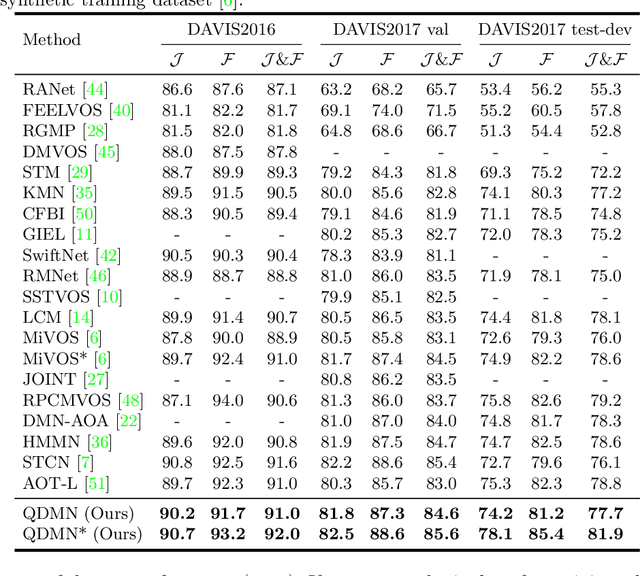
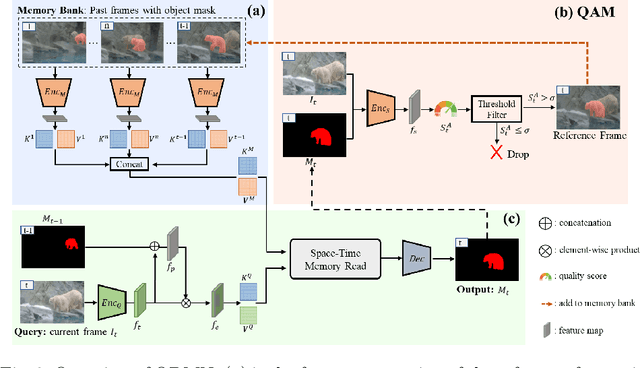
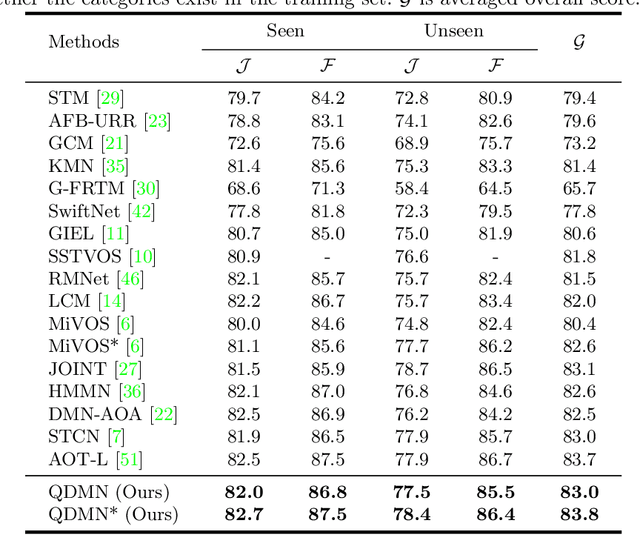
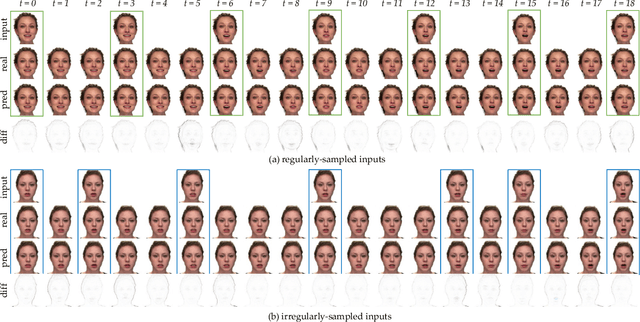
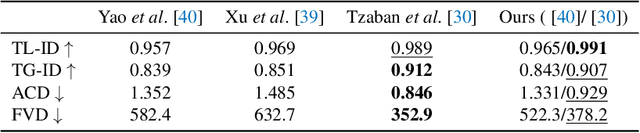
Recently, several spatial-temporal memory-based methods have verified that storing intermediate frames and their masks as memory are helpful to segment target objects in videos. However, they mainly focus on better matching between the current frame and the memory frames without explicitly paying attention to the quality of the memory. Therefore, frames with poor segmentation masks are prone to be memorized, which leads to a segmentation mask error accumulation problem and further affect the segmentation performance. In addition, the linear increase of memory frames with the growth of frame number also limits the ability of the models to handle long videos. To this end, we propose a Quality-aware Dynamic Memory Network (QDMN) to evaluate the segmentation quality of each frame, allowing the memory bank to selectively store accurately segmented frames to prevent the error accumulation problem. Then, we combine the segmentation quality with temporal consistency to dynamically update the memory bank to improve the practicability of the models. Without any bells and whistles, our QDMN achieves new state-of-the-art performance on both DAVIS and YouTube-VOS benchmarks. Moreover, extensive experiments demonstrate that the proposed Quality Assessment Module (QAM) can be applied to memory-based methods as generic plugins and significantly improves performance. Our source code is available at https://github.com/workforai/QDMN.
Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network
Apr 22, 2022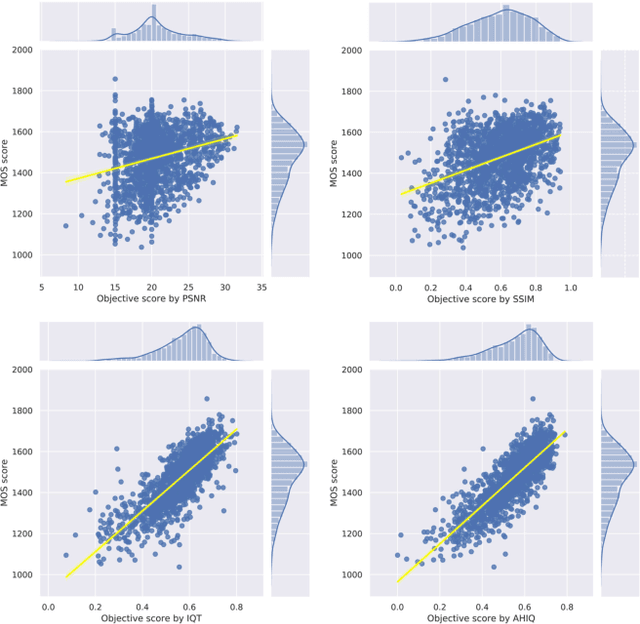

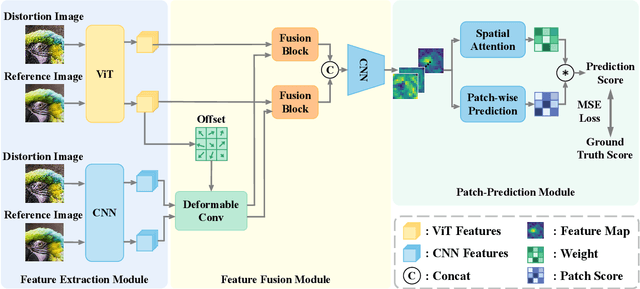
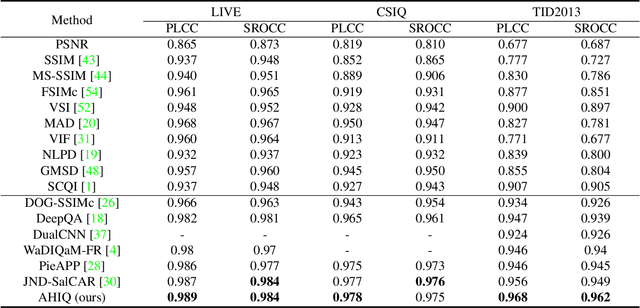
Image quality assessment (IQA) algorithm aims to quantify the human perception of image quality. Unfortunately, there is a performance drop when assessing the distortion images generated by generative adversarial network (GAN) with seemingly realistic texture. In this work, we conjecture that this maladaptation lies in the backbone of IQA models, where patch-level prediction methods use independent image patches as input to calculate their scores separately, but lack spatial relationship modeling among image patches. Therefore, we propose an Attention-based Hybrid Image Quality Assessment Network (AHIQ) to deal with the challenge and get better performance on the GAN-based IQA task. Firstly, we adopt a two-branch architecture, including a vision transformer (ViT) branch and a convolutional neural network (CNN) branch for feature extraction. The hybrid architecture combines interaction information among image patches captured by ViT and local texture details from CNN. To make the features from shallow CNN more focused on the visually salient region, a deformable convolution is applied with the help of semantic information from the ViT branch. Finally, we use a patch-wise score prediction module to obtain the final score. The experiments show that our model outperforms the state-of-the-art methods on four standard IQA datasets and AHIQ ranked first on the Full Reference (FR) track of the NTIRE 2022 Perceptual Image Quality Assessment Challenge.
High-fidelity GAN Inversion with Padding Space
Mar 21, 2022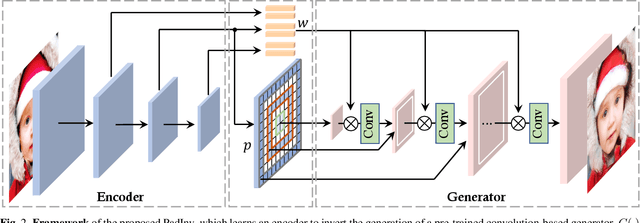



Inverting a Generative Adversarial Network (GAN) facilitates a wide range of image editing tasks using pre-trained generators. Existing methods typically employ the latent space of GANs as the inversion space yet observe the insufficient recovery of spatial details. In this work, we propose to involve the padding space of the generator to complement the latent space with spatial information. Concretely, we replace the constant padding (e.g., usually zeros) used in convolution layers with some instance-aware coefficients. In this way, the inductive bias assumed in the pre-trained model can be appropriately adapted to fit each individual image. Through learning a carefully designed encoder, we manage to improve the inversion quality both qualitatively and quantitatively, outperforming existing alternatives. We then demonstrate that such a space extension barely affects the native GAN manifold, hence we can still reuse the prior knowledge learned by GANs for various downstream applications. Beyond the editing tasks explored in prior arts, our approach allows a more flexible image manipulation, such as the separate control of face contour and facial details, and enables a novel editing manner where users can customize their own manipulations highly efficiently.
Identity-Guided Face Generation with Multi-modal Contour Conditions
Oct 10, 2021
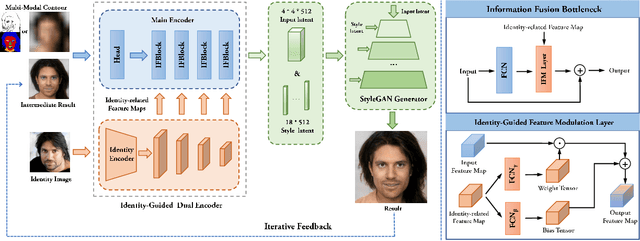
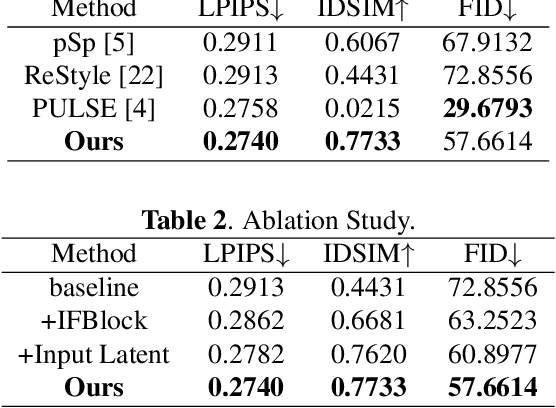

Recent face generation methods have tried to synthesize faces based on the given contour condition, like a low-resolution image or a sketch. However, the problem of identity ambiguity remains unsolved, which usually occurs when the contour is too vague to provide reliable identity information (e.g., when its resolution is extremely low). In this work, we propose a framework that takes the contour and an extra image specifying the identity as the inputs, where the contour can be of various modalities, including the low-resolution image, sketch, and semantic label map. This task especially fits the situation of tracking the known criminals or making intelligent creations for entertainment. Concretely, we propose a novel dual-encoder architecture, in which an identity encoder extracts the identity-related feature, accompanied by a main encoder to obtain the rough contour information and further fuse all the information together. The encoder output is iteratively fed into a pre-trained StyleGAN generator until getting a satisfying result. To the best of our knowledge, this is the first work that achieves identity-guided face generation conditioned on multi-modal contour images. Moreover, our method can produce photo-realistic results with 1024$\times$1024 resolution. Code will be available at https://git.io/Jo4yh.
Real-time Human-Centric Segmentation for Complex Video Scenes
Aug 16, 2021
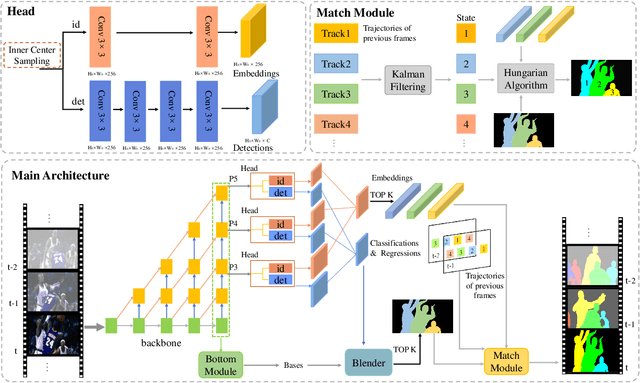

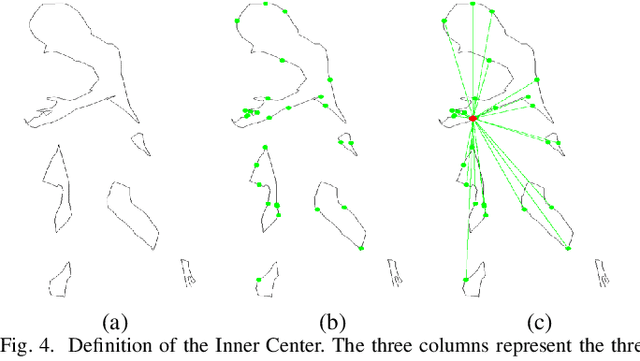
Most existing video tasks related to "human" focus on the segmentation of salient humans, ignoring the unspecified others in the video. Few studies have focused on segmenting and tracking all humans in a complex video, including pedestrians and humans of other states (e.g., seated, riding, or occluded). In this paper, we propose a novel framework, abbreviated as HVISNet, that segments and tracks all presented people in given videos based on a one-stage detector. To better evaluate complex scenes, we offer a new benchmark called HVIS (Human Video Instance Segmentation), which comprises 1447 human instance masks in 805 high-resolution videos in diverse scenes. Extensive experiments show that our proposed HVISNet outperforms the state-of-the-art methods in terms of accuracy at a real-time inference speed (30 FPS), especially on complex video scenes. We also notice that using the center of the bounding box to distinguish different individuals severely deteriorates the segmentation accuracy, especially in heavily occluded conditions. This common phenomenon is referred to as the ambiguous positive samples problem. To alleviate this problem, we propose a mechanism named Inner Center Sampling to improve the accuracy of instance segmentation. Such a plug-and-play inner center sampling mechanism can be incorporated in any instance segmentation models based on a one-stage detector to improve the performance. In particular, it gains 4.1 mAP improvement on the state-of-the-art method in the case of occluded humans. Code and data are available at https://github.com/IIGROUP/HVISNet.
PoseDet: Fast Multi-Person Pose Estimation Using Pose Embedding
Jul 27, 2021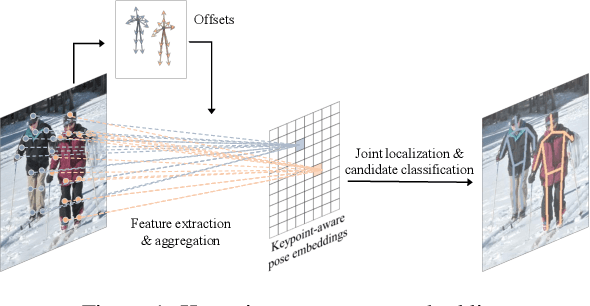
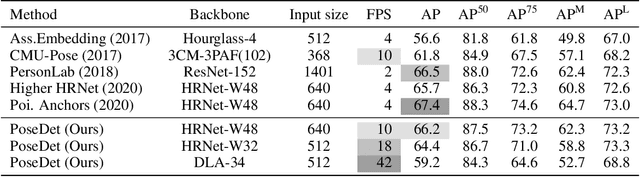
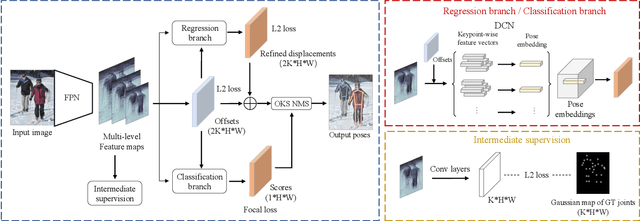
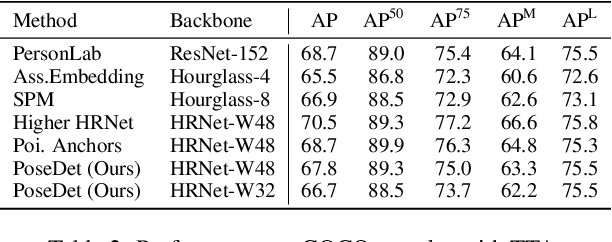
Current methods of multi-person pose estimation typically treat the localization and the association of body joints separately. It is convenient but inefficient, leading to additional computation and a waste of time. This paper, however, presents a novel framework PoseDet (Estimating Pose by Detection) to localize and associate body joints simultaneously at higher inference speed. Moreover, we propose the keypoint-aware pose embedding to represent an object in terms of the locations of its keypoints. The proposed pose embedding contains semantic and geometric information, allowing us to access discriminative and informative features efficiently. It is utilized for candidate classification and body joint localization in PoseDet, leading to robust predictions of various poses. This simple framework achieves an unprecedented speed and a competitive accuracy on the COCO benchmark compared with state-of-the-art methods. Extensive experiments on the CrowdPose benchmark show the robustness in the crowd scenes. Source code is available.