 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware LLM Council with Adaptive Decision Pathways for Decision Support
Jan 30, 2026Large language models (LLMs) have shown strong capabilities across diverse decision-making tasks. However, existing approaches often overlook the specialization differences among available models, treating all LLMs as uniformly applicable regardless of task characteristics. This limits their ability to adapt to varying reasoning demands and task complexities. In this work, we propose Task-Aware LLM Council (TALC), a task-adaptive decision framework that integrates a council of LLMs with Monte Carlo Tree Search (MCTS) to enable dynamic expert selection and efficient multi-step planning. Each LLM is equipped with a structured success memory profile derived from prior task trajectories, enabling semantic matching between current reasoning context and past successes. At each decision point, TALC routes control to the most contextually appropriate model and estimates node value using a dual-signal mechanism that fuses model-based evaluations with historical utility scores. These signals are adaptively weighted based on intra-node variance and used to guide MCTS selection, allowing the system to balance exploration depth with planning confidence. Experiments on WebShop, HumanEval, and the Game of 24 demonstrate that TALC achieves superior task success rates and improved search efficiency compared to strong baselines, validating the benefits of specialization-aware routing and adaptive planning.
Evaluating ChatGPT on Medical Information Extraction Tasks: Performance, Explainability and Beyond
Jan 29, 2026Large Language Models (LLMs) like ChatGPT have demonstrated amazing capabilities in comprehending user intents and generate reasonable and useful responses. Beside their ability to chat, their capabilities in various natural language processing (NLP) tasks are of interest to the research community. In this paper, we focus on assessing the overall ability of ChatGPT in 4 different medical information extraction (MedIE) tasks across 6 benchmark datasets. We present the systematically analysis by measuring ChatGPT's performance, explainability, confidence, faithfulness, and uncertainty. Our experiments reveal that: (a) ChatGPT's performance scores on MedIE tasks fall behind those of the fine-tuned baseline models. (b) ChatGPT can provide high-quality explanations for its decisions, however, ChatGPT is over-confident in its predcitions. (c) ChatGPT demonstrates a high level of faithfulness to the original text in the majority of cases. (d) The uncertainty in generation causes uncertainty in information extraction results, thus may hinder its applications in MedIE tasks.
ShapLoRA: Allocation of Low-rank Adaption on Large Language Models via Shapley Value Inspired Importance Estimation
Jan 25, 2026Low-rank adaption (LoRA) is a representative method in the field of parameter-efficient fine-tuning (PEFT), and is key to Democratizating the modern large language models (LLMs). The vanilla LoRA is implemented with uniform ranks, and the recent literature have found that properly allocating ranks on the LLM backbones results in performance boosts. However, the previous rank allocation methods have limitations since they rely on inexplanable and unreliable importance measures for the LoRA ranks. To address the above issues, we propose the ShapLoRA framework. Inspired by the explanable attribution measure Shapley Value, we combine the sensitivity-based measures with the idea of coalitions in the collaborative games among LoRA ranks, and propose a more explainable importance measure called Shapley sensitivity. In addition, we optimize the workflow of the existing works by: (a) calculating Shapley sensitivity on a separate validation set; (b) Setting up the allocating-retraining procedures for fair comparisons. We have conducted experiments on various challenging tasks, and the experimental results demonstrate that our ShapLoRA method can outperform the recent baselines with comparable tunable parameters.\footnote{Codes and fine-tuned models will be open-sourced to facilitate future research.
MRAG: Benchmarking Retrieval-Augmented Generation for Bio-medicine
Jan 23, 2026While Retrieval-Augmented Generation (RAG) has been swiftly adopted in scientific and clinical QA systems, a comprehensive evaluation benchmark in the medical domain is lacking. To address this gap, we introduce the Medical Retrieval-Augmented Generation (MRAG) benchmark, covering various tasks in English and Chinese languages, and building a corpus with Wikipedia and Pubmed. Additionally, we develop the MRAG-Toolkit, facilitating systematic exploration of different RAG components. Our experiments reveal that: (a) RAG enhances LLM reliability across MRAG tasks. (b) the performance of RAG systems is influenced by retrieval approaches, model sizes, and prompting strategies. (c) While RAG improves usefulness and reasoning quality, LLM responses may become slightly less readable for long-form questions. We will release the MRAG-Bench's dataset and toolkit with CCBY-4.0 license upon acceptance, to facilitate applications from both academia and industry.
FT-MDT: Extracting Decision Trees from Medical Texts via a Novel Low-rank Adaptation Method
Oct 06, 2025Knowledge of the medical decision process, which can be modeled as medical decision trees (MDTs), is critical to building clinical decision support systems. However, current MDT construction methods rely heavily on time-consuming and laborious manual annotation. To address this challenge, we propose PI-LoRA (Path-Integrated LoRA), a novel low-rank adaptation method for automatically extracting MDTs from clinical guidelines and textbooks. We integrate gradient path information to capture synergistic effects between different modules, enabling more effective and reliable rank allocation. This framework ensures that the most critical modules receive appropriate rank allocations while less important ones are pruned, resulting in a more efficient and accurate model for extracting medical decision trees from clinical texts. Extensive experiments on medical guideline datasets demonstrate that our PI-LoRA method significantly outperforms existing parameter-efficient fine-tuning approaches for the Text2MDT task, achieving better accuracy with substantially reduced model complexity. The proposed method achieves state-of-the-art results while maintaining a lightweight architecture, making it particularly suitable for clinical decision support systems where computational resources may be limited.
AMAS: Adaptively Determining Communication Topology for LLM-based Multi-Agent System
Oct 02, 2025Although large language models (LLMs) have revolutionized natural language processing capabilities, their practical implementation as autonomous multi-agent systems (MAS) for industrial problem-solving encounters persistent barriers. Conventional MAS architectures are fundamentally restricted by inflexible, hand-crafted graph topologies that lack contextual responsiveness, resulting in diminished efficacy across varied academic and commercial workloads. To surmount these constraints, we introduce AMAS, a paradigm-shifting framework that redefines LLM-based MAS through a novel dynamic graph designer. This component autonomously identifies task-specific optimal graph configurations via lightweight LLM adaptation, eliminating the reliance on monolithic, universally applied structural templates. Instead, AMAS exploits the intrinsic properties of individual inputs to intelligently direct query trajectories through task-optimized agent pathways. Rigorous validation across question answering, mathematical deduction, and code generation benchmarks confirms that AMAS systematically exceeds state-of-the-art single-agent and multi-agent approaches across diverse LLM architectures. Our investigation establishes that context-sensitive structural adaptability constitutes a foundational requirement for high-performance LLM MAS deployments.
CorrMoE: Mixture of Experts with De-stylization Learning for Cross-Scene and Cross-Domain Correspondence Pruning
Jul 16, 2025Establishing reliable correspondences between image pairs is a fundamental task in computer vision, underpinning applications such as 3D reconstruction and visual localization. Although recent methods have made progress in pruning outliers from dense correspondence sets, they often hypothesize consistent visual domains and overlook the challenges posed by diverse scene structures. In this paper, we propose CorrMoE, a novel correspondence pruning framework that enhances robustness under cross-domain and cross-scene variations. To address domain shift, we introduce a De-stylization Dual Branch, performing style mixing on both implicit and explicit graph features to mitigate the adverse influence of domain-specific representations. For scene diversity, we design a Bi-Fusion Mixture of Experts module that adaptively integrates multi-perspective features through linear-complexity attention and dynamic expert routing. Extensive experiments on benchmark datasets demonstrate that CorrMoE achieves superior accuracy and generalization compared to state-of-the-art methods. The code and pre-trained models are available at https://github.com/peiwenxia/CorrMoE.
Robust Moment Identification for Nonlinear PDEs via a Neural ODE Approach
Jun 05, 2025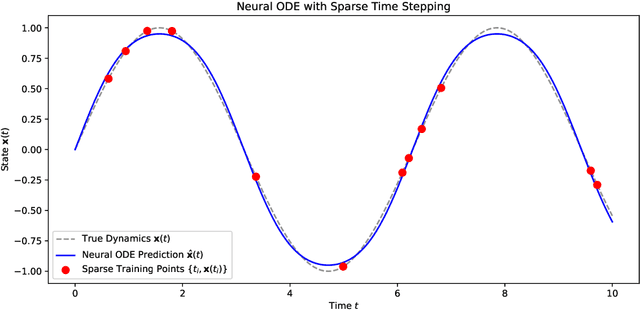


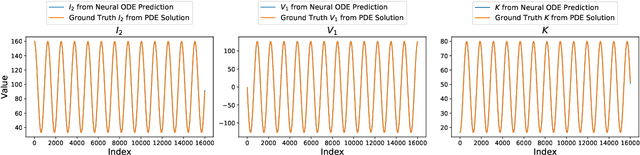
We propose a data-driven framework for learning reduced-order moment dynamics from PDE-governed systems using Neural ODEs. In contrast to derivative-based methods like SINDy, which necessitate densely sampled data and are sensitive to noise, our approach based on Neural ODEs directly models moment trajectories, enabling robust learning from sparse and potentially irregular time series. Using as an application platform the nonlinear Schr\"{o}dinger equation, the framework accurately recovers governing moment dynamics when closure is available, even with limited and irregular observations. For systems without analytical closure, we introduce a data-driven coordinate transformation strategy based on Stiefel manifold optimization, enabling the discovery of low-dimensional representations in which the moment dynamics become closed, facilitating interpretable and reliable modeling. We also explore cases where a closure model is not known, such as a Fisher-KPP reaction-diffusion system. Here we demonstrate that Neural ODEs can still effectively approximate the unclosed moment dynamics and achieve superior extrapolation accuracy compared to physical-expert-derived ODE models. This advantage remains robust even under sparse and irregular sampling, highlighting the method's robustness in data-limited settings. Our results highlight the Neural ODE framework as a powerful and flexible tool for learning interpretable, low-dimensional moment dynamics in complex PDE-governed systems.
ML-Triton, A Multi-Level Compilation and Language Extension to Triton GPU Programming
Mar 19, 2025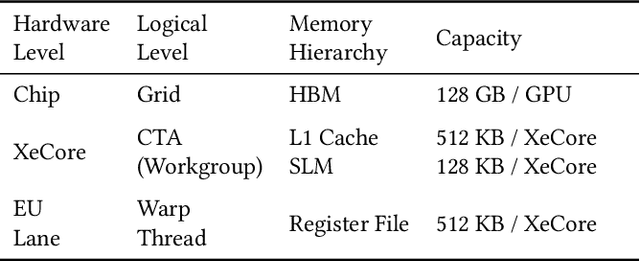
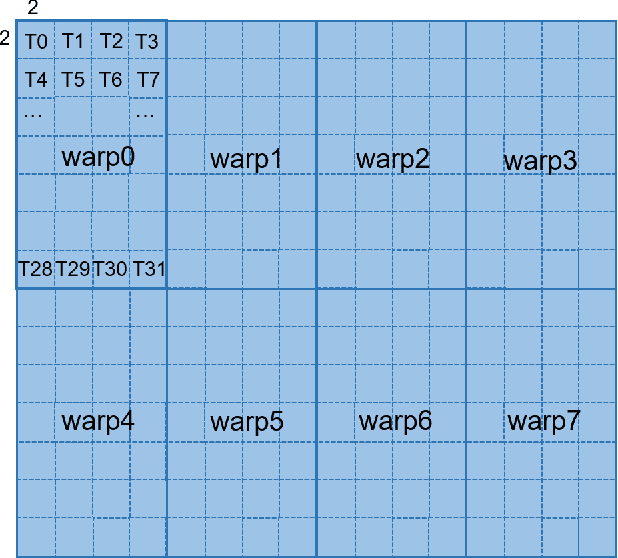

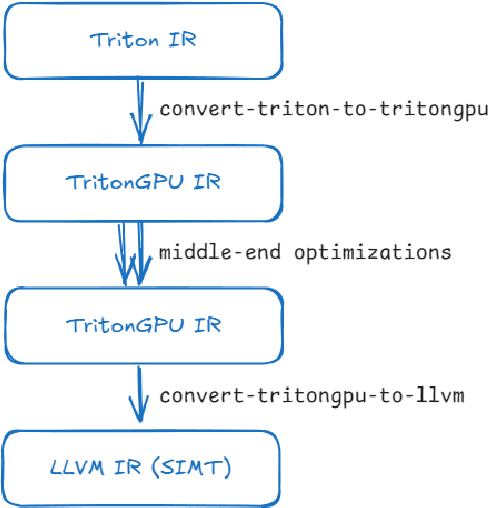
In the era of LLMs, dense operations such as GEMM and MHA are critical components. These operations are well-suited for parallel execution using a tilebased approach. While traditional GPU programming often relies on low level interfaces like CUDA or SYCL, Triton has emerged as a DSL that offers a more user-friendly and portable alternative by programming at a higher level. The current Triton starts at the workgroup (aka threadblock) level, and directly lowers to per-thread level. And then attempt to coalesce and amend through a series of passes, promoting information from low-level representation. We believe this is pre-mature lowering based on the below observations. 1. GPU has a hierarchical structure both physically and logically. Modern GPUs often feature SIMD units capable of directly operating on tiles on a warp or warpgroup basis, such as blocked load and blocked MMA. 2. Multi-level gradual lowering can make compiler decoupled and clean by separating considerations inter and intra a logical layer. 3. Kernel developers often need fine control to get good performance on the latest hardware. FlashAttention2 advocates explicit data partition between warps to make a performance boost. In this context, we propose ML-Triton which features multi-level compilation flow and programming interface. Our approach begins at the workgroup level and progressively lowers to the warp and intrinsic level, implementing a multilevel lowering align with the hierarchical nature of GPU. Additionally, we extend triton language to support user-set compiler hint and warp level programming, enabling researchers to get good out-of-the box performance without awaiting compiler updates. Experimental results demonstrate that our approach achieves performance above 95% of expert-written kernels on Intel GPU, as measured by the geometric mean.
EmoBipedNav: Emotion-aware Social Navigation for Bipedal Robots with Deep Reinforcement Learning
Mar 16, 2025This study presents an emotion-aware navigation framework -- EmoBipedNav -- using deep reinforcement learning (DRL) for bipedal robots walking in socially interactive environments. The inherent locomotion constraints of bipedal robots challenge their safe maneuvering capabilities in dynamic environments. When combined with the intricacies of social environments, including pedestrian interactions and social cues, such as emotions, these challenges become even more pronounced. To address these coupled problems, we propose a two-stage pipeline that considers both bipedal locomotion constraints and complex social environments. Specifically, social navigation scenarios are represented using sequential LiDAR grid maps (LGMs), from which we extract latent features, including collision regions, emotion-related discomfort zones, social interactions, and the spatio-temporal dynamics of evolving environments. The extracted features are directly mapped to the actions of reduced-order models (ROMs) through a DRL architecture. Furthermore, the proposed framework incorporates full-order dynamics and locomotion constraints during training, effectively accounting for tracking errors and restrictions of the locomotion controller while planning the trajectory with ROMs. Comprehensive experiments demonstrate that our approach exceeds both model-based planners and DRL-based baselines. The hardware videos and open-source code are available at https://gatech-lidar.github.io/emobipednav.github.io/.