 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Failure Dynamics in Large Language Model Reasoning
Apr 16, 2026Large Language Models (LLMs) achieve strong performance through extended inference-time deliberation, yet how their reasoning failures arise remains poorly understood. By analyzing model-generated reasoning trajectories, we find that errors are not uniformly distributed but often originate from a small number of early transition points, after which reasoning remains locally coherent but globally incorrect. These transitions coincide with localized spikes in token-level entropy, and alternative continuations from the same intermediate state can still lead to correct solutions. Based on these observations, we introduce GUARD, a targeted inference-time framework that probes and redirects critical transitions using uncertainty signals. Empirical evaluations across multiple benchmarks confirm that interventions guided by these failure dynamics lead to more reliable reasoning outcomes. Our findings highlight the importance of understanding when and how reasoning first deviates, complementing existing approaches that focus on scaling inference-time computation.
Task-Aware LLM Council with Adaptive Decision Pathways for Decision Support
Jan 30, 2026Large language models (LLMs) have shown strong capabilities across diverse decision-making tasks. However, existing approaches often overlook the specialization differences among available models, treating all LLMs as uniformly applicable regardless of task characteristics. This limits their ability to adapt to varying reasoning demands and task complexities. In this work, we propose Task-Aware LLM Council (TALC), a task-adaptive decision framework that integrates a council of LLMs with Monte Carlo Tree Search (MCTS) to enable dynamic expert selection and efficient multi-step planning. Each LLM is equipped with a structured success memory profile derived from prior task trajectories, enabling semantic matching between current reasoning context and past successes. At each decision point, TALC routes control to the most contextually appropriate model and estimates node value using a dual-signal mechanism that fuses model-based evaluations with historical utility scores. These signals are adaptively weighted based on intra-node variance and used to guide MCTS selection, allowing the system to balance exploration depth with planning confidence. Experiments on WebShop, HumanEval, and the Game of 24 demonstrate that TALC achieves superior task success rates and improved search efficiency compared to strong baselines, validating the benefits of specialization-aware routing and adaptive planning.
SYMPHONY: Synergistic Multi-agent Planning with Heterogeneous Language Model Assembly
Jan 30, 2026Recent advancements have increasingly focused on leveraging large language models (LLMs) to construct autonomous agents for complex problem-solving tasks. However, existing approaches predominantly employ a single-agent framework to generate search branches and estimate rewards during Monte Carlo Tree Search (MCTS) planning. This single-agent paradigm inherently limits exploration capabilities, often resulting in insufficient diversity among generated branches and suboptimal planning performance. To overcome these limitations, we propose Synergistic Multi-agent Planning with Heterogeneous langauge model assembly (SYMPHONY), a novel multi-agent planning framework that integrates a pool of heterogeneous language model-based agents. By leveraging diverse reasoning patterns across agents, SYMPHONY enhances rollout diversity and facilitates more effective exploration. Empirical results across multiple benchmark tasks show that SYMPHONY achieves strong performance even when instantiated with open-source LLMs deployable on consumer-grade hardware. When enhanced with cloud-based LLMs accessible via API, SYMPHONY demonstrates further improvements, outperforming existing state-of-the-art baselines and underscoring the effectiveness of heterogeneous multi-agent coordination in planning tasks.
Dual-Kernel Graph Community Contrastive Learning
Nov 11, 2025



Graph Contrastive Learning (GCL) has emerged as a powerful paradigm for training Graph Neural Networks (GNNs) in the absence of task-specific labels. However, its scalability on large-scale graphs is hindered by the intensive message passing mechanism of GNN and the quadratic computational complexity of contrastive loss over positive and negative node pairs. To address these issues, we propose an efficient GCL framework that transforms the input graph into a compact network of interconnected node sets while preserving structural information across communities. We firstly introduce a kernelized graph community contrastive loss with linear complexity, enabling effective information transfer among node sets to capture hierarchical structural information of the graph. We then incorporate a knowledge distillation technique into the decoupled GNN architecture to accelerate inference while maintaining strong generalization performance. Extensive experiments on sixteen real-world datasets of varying scales demonstrate that our method outperforms state-of-the-art GCL baselines in both effectiveness and scalability.
Cancer Subtyping by Improved Transcriptomic Features Using Vector Quantized Variational Autoencoder
Jul 20, 2022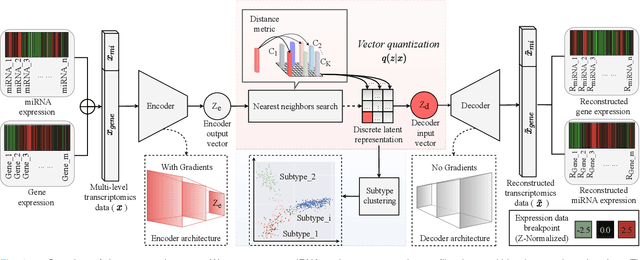
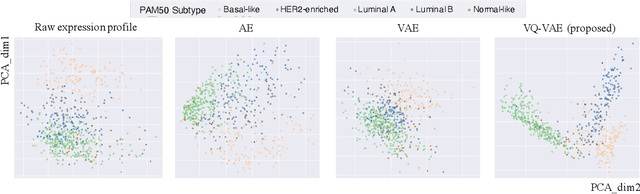
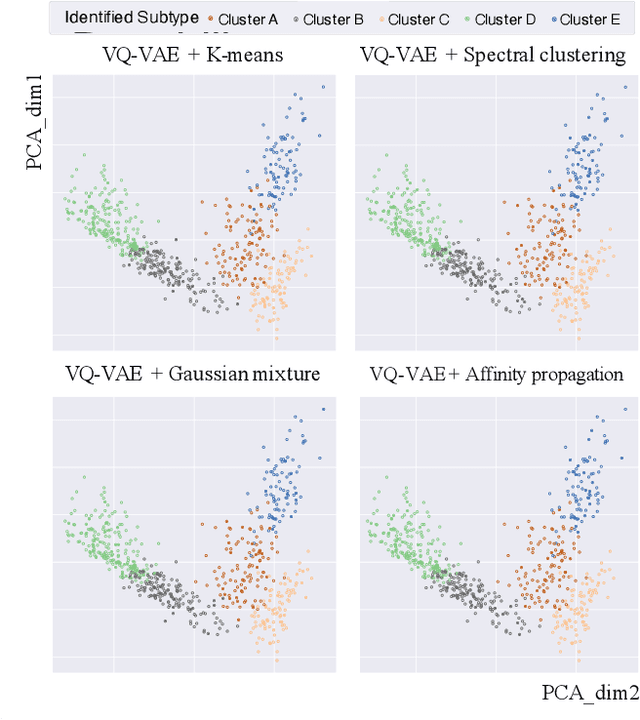
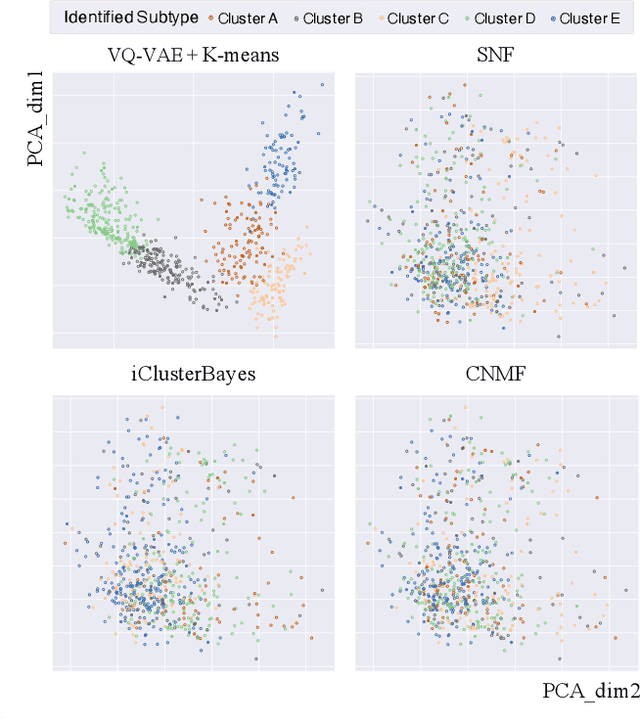
Defining and separating cancer subtypes is essential for facilitating personalized therapy modality and prognosis of patients. The definition of subtypes has been constantly recalibrated as a result of our deepened understanding. During this recalibration, researchers often rely on clustering of cancer data to provide an intuitive visual reference that could reveal the intrinsic characteristics of subtypes. The data being clustered are often omics data such as transcriptomics that have strong correlations to the underlying biological mechanism. However, while existing studies have shown promising results, they suffer from issues associated with omics data: sample scarcity and high dimensionality. As such, existing methods often impose unrealistic assumptions to extract useful features from the data while avoiding overfitting to spurious correlations. In this paper, we propose to leverage a recent strong generative model, Vector Quantized Variational AutoEncoder (VQ-VAE), to tackle the data issues and extract informative latent features that are crucial to the quality of subsequent clustering by retaining only information relevant to reconstructing the input. VQ-VAE does not impose strict assumptions and hence its latent features are better representations of the input, capable of yielding superior clustering performance with any mainstream clustering method. Extensive experiments and medical analysis on multiple datasets comprising 10 distinct cancers demonstrate the VQ-VAE clustering results can significantly and robustly improve prognosis over prevalent subtyping systems.