 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Wei
A Benchmark for Structured Extractions from Complex Documents
Nov 15, 2022




Understanding visually-rich business documents to extract structured data and automate business workflows has been receiving attention both in academia and industry. Although recent multi-modal language models have achieved impressive results, we find that existing benchmarks do not reflect the complexity of real documents seen in industry. In this work, we identify the desiderata for a more comprehensive benchmark and propose one we call Visually Rich Document Understanding (VRDU). VRDU contains two datasets that represent several challenges: rich schema including diverse data types as well as nested entities, complex templates including tables and multi-column layouts, and diversity of different layouts (templates) within a single document type. We design few-shot and conventional experiment settings along with a carefully designed matching algorithm to evaluate extraction results. We report the performance of strong baselines and three observations: (1) generalizing to new document templates is very challenging, (2) few-shot performance has a lot of headroom, and (3) models struggle with nested fields such as line-items in an invoice. We plan to open source the benchmark and the evaluation toolkit. We hope this helps the community make progress on these challenging tasks in extracting structured data from visually rich documents.
Knowledge Graph Enhanced Relation Extraction Datasets
Oct 19, 2022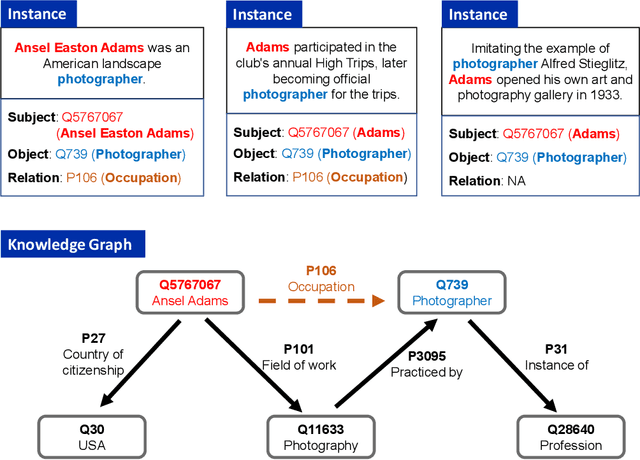
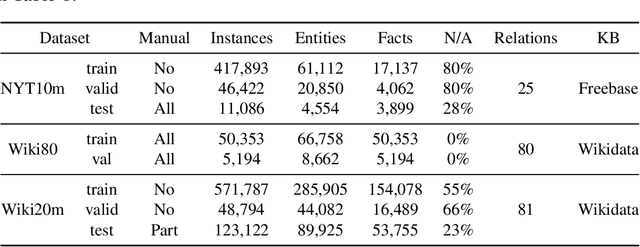

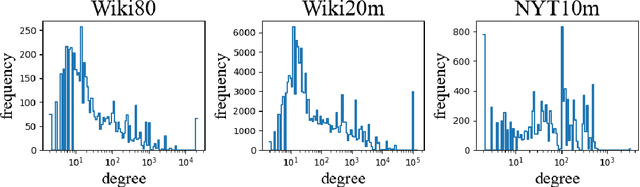
Knowledge-enhanced methods that take advantage of auxiliary knowledge graphs recently emerged in relation extraction, and they surpass traditional text-based relation extraction methods. However, there are no unified public benchmarks that currently involve evidence sentences and knowledge graphs for knowledge-enhanced relation extraction. To combat these issues, we propose KGRED, a knowledge graph enhanced relation extraction dataset with features as follows: (1) the benchmarks are based on widely-used distantly supervised relation extraction datasets; (2) we refine these existing datasets to improve the data quality, and we also construct auxiliary knowledge graphs for these existing datasets through entity linking to support knowledge-enhanced relation extraction tasks; (3) with the new benchmarks we curated, we build baselines in two popular relation extraction settings including sentence-level and bag-level relation extraction, and we also make comparisons among the latest knowledge-enhanced relation extraction methods. KGRED provides high-quality relation extraction datasets with auxiliary knowledge graphs for evaluating the performance of knowledge-enhanced relation extraction methods. Meanwhile, our experiments on KGRED reveal the influence of knowledge graph information on relation extraction tasks.
HCL-TAT: A Hybrid Contrastive Learning Method for Few-shot Event Detection with Task-Adaptive Threshold
Oct 17, 2022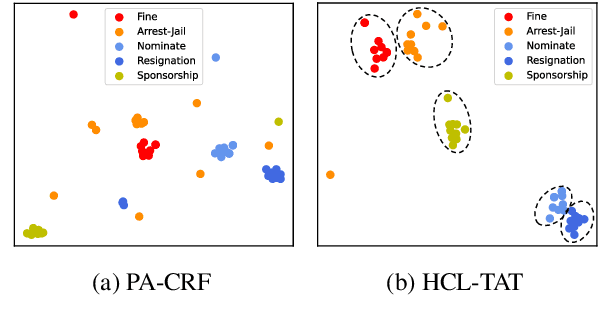
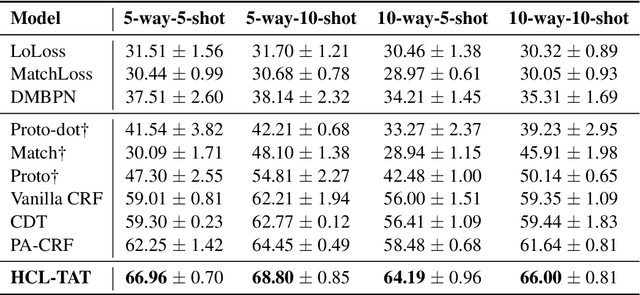
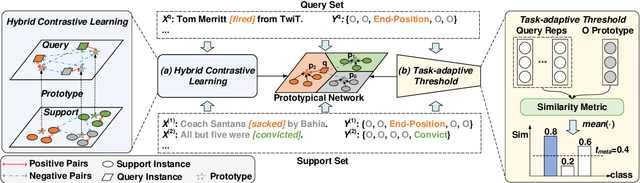
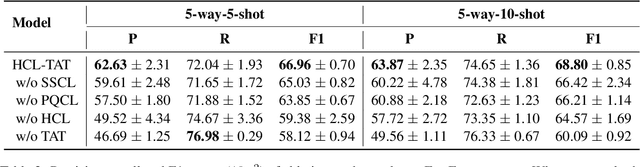
Conventional event detection models under supervised learning settings suffer from the inability of transfer to newly-emerged event types owing to lack of sufficient annotations. A commonly-adapted solution is to follow a identify-then-classify manner, which first identifies the triggers and then converts the classification task via a few-shot learning paradigm. However, these methods still fall far short of expectations due to: (i) insufficient learning of discriminative representations in low-resource scenarios, and (ii) trigger misidentification caused by the overlap of the learned representations of triggers and non-triggers. To address the problems, in this paper, we propose a novel Hybrid Contrastive Learning method with a Task-Adaptive Threshold (abbreviated as HCLTAT), which enables discriminative representation learning with a two-view contrastive loss (support-support and prototype-query), and devises a easily-adapted threshold to alleviate misidentification of triggers. Extensive experiments on the benchmark dataset FewEvent demonstrate the superiority of our method to achieve better results compared to the state-of-the-arts. All the code and data of this paper will be available for online public access.
Sequential Topic Selection Model with Latent Variable for Topic-Grounded Dialogue
Oct 17, 2022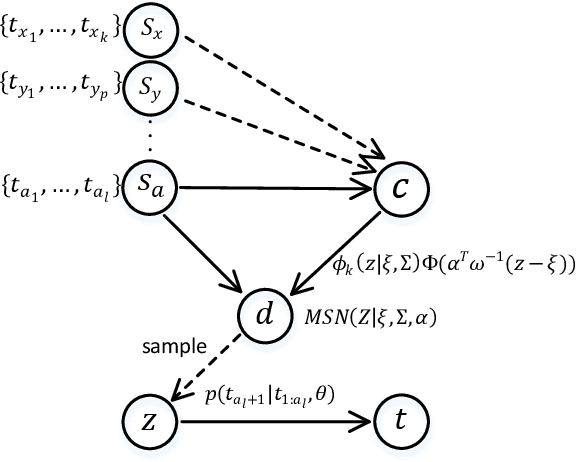
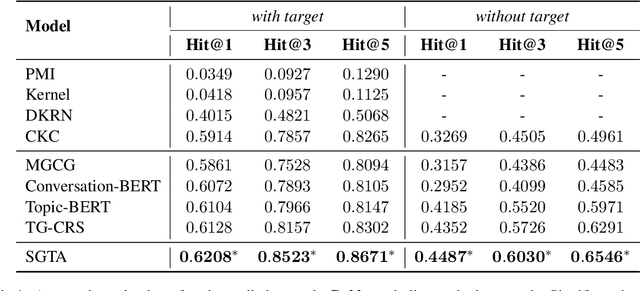
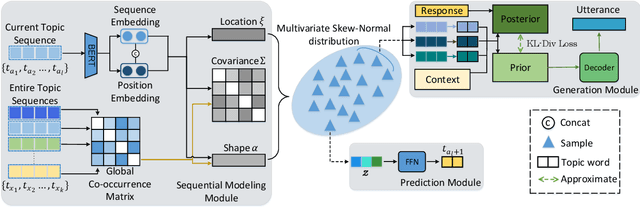
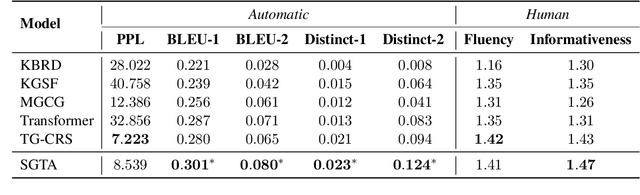
Recently, topic-grounded dialogue system has attracted significant attention due to its effectiveness in predicting the next topic to yield better responses via the historical context and given topic sequence. However, almost all existing topic prediction solutions focus on only the current conversation and corresponding topic sequence to predict the next conversation topic, without exploiting other topic-guided conversations which may contain relevant topic-transitions to current conversation. To address the problem, in this paper we propose a novel approach, named Sequential Global Topic Attention (SGTA) to exploit topic transition over all conversations in a subtle way for better modeling post-to-response topic-transition and guiding the response generation to the current conversation. Specifically, we introduce a latent space modeled as a Multivariate Skew-Normal distribution with hybrid kernel functions to flexibly integrate the global-level information with sequence-level information, and predict the topic based on the distribution sampling results. We also leverage a topic-aware prior-posterior approach for secondary selection of predicted topics, which is utilized to optimize the response generation task. Extensive experiments demonstrate that our model outperforms competitive baselines on prediction and generation tasks.
Capturing Global Structural Information in Long Document Question Answering with Compressive Graph Selector Network
Oct 11, 2022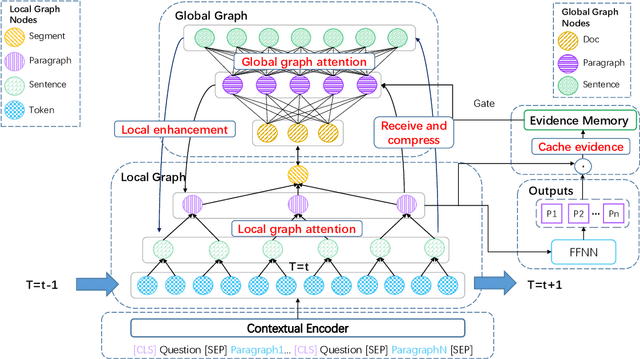
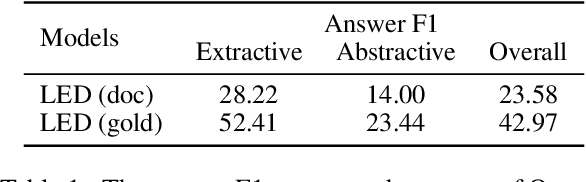
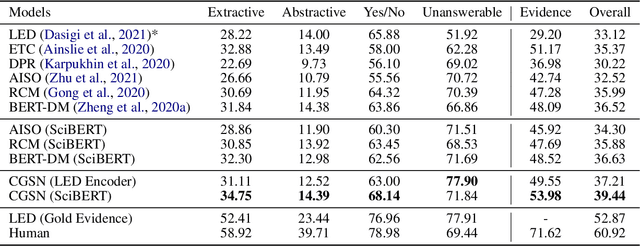
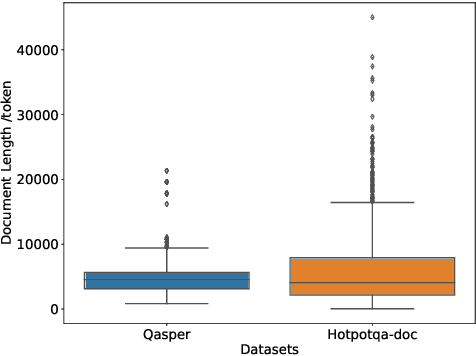
Long document question answering is a challenging task due to its demands for complex reasoning over long text. Previous works usually take long documents as non-structured flat texts or only consider the local structure in long documents. However, these methods usually ignore the global structure of the long document, which is essential for long-range understanding. To tackle this problem, we propose Compressive Graph Selector Network (CGSN) to capture the global structure in a compressive and iterative manner. Specifically, the proposed model consists of three modules: local graph network, global graph network and evidence memory network. Firstly, the local graph network builds the graph structure of the chunked segment in token, sentence, paragraph and segment levels to capture the short-term dependency of the text. Secondly, the global graph network selectively receives the information of each level from the local graph, compresses them into the global graph nodes and applies graph attention into the global graph nodes to build the long-range reasoning over the entire text in an iterative way. Thirdly, the evidence memory network is designed to alleviate the redundancy problem in the evidence selection via saving the selected result in the previous steps. Extensive experiments show that the proposed model outperforms previous methods on two datasets.
Incorporating Causal Analysis into Diversified and Logical Response Generation
Oct 11, 2022
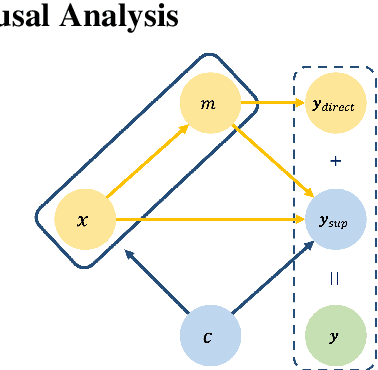
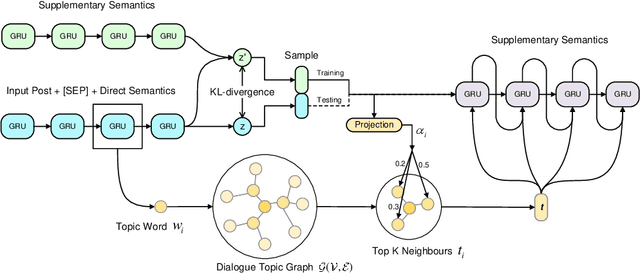
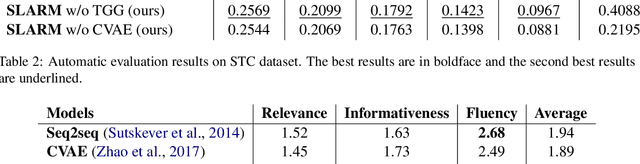
Although the Conditional Variational AutoEncoder (CVAE) model can generate more diversified responses than the traditional Seq2Seq model, the responses often have low relevance with the input words or are illogical with the question. A causal analysis is carried out to study the reasons behind, and a methodology of searching for the mediators and mitigating the confounding bias in dialogues is provided. Specifically, we propose to predict the mediators to preserve relevant information and auto-regressively incorporate the mediators into generating process. Besides, a dynamic topic graph guided conditional variational autoencoder (TGG-CVAE) model is utilized to complement the semantic space and reduce the confounding bias in responses. Extensive experiments demonstrate that the proposed model is able to generate both relevant and informative responses, and outperforms the state-of-the-art in terms of automatic metrics and human evaluations.
Metric Distribution to Vector: Constructing Data Representation via Broad-Scale Discrepancies
Oct 02, 2022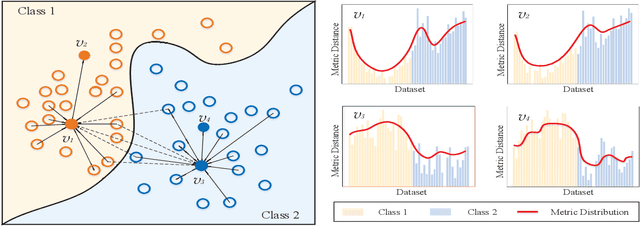
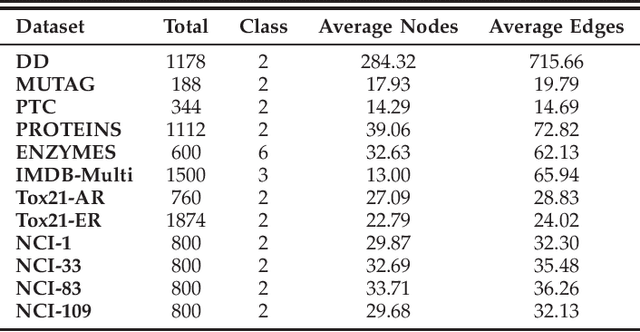
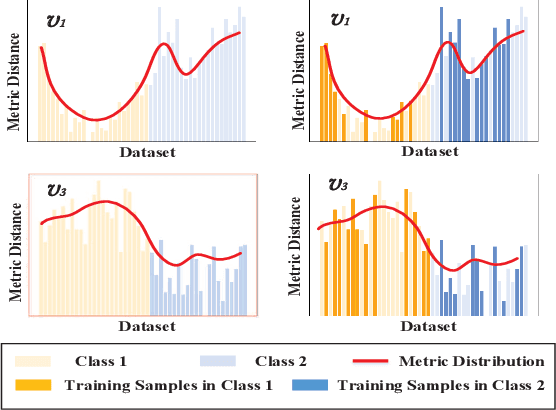

Graph embedding provides a feasible methodology to conduct pattern classification for graph-structured data by mapping each data into the vectorial space. Various pioneering works are essentially coding method that concentrates on a vectorial representation about the inner properties of a graph in terms of the topological constitution, node attributions, link relations, etc. However, the classification for each targeted data is a qualitative issue based on understanding the overall discrepancies within the dataset scale. From the statistical point of view, these discrepancies manifest a metric distribution over the dataset scale if the distance metric is adopted to measure the pairwise similarity or dissimilarity. Therefore, we present a novel embedding strategy named $\mathbf{MetricDistribution2vec}$ to extract such distribution characteristics into the vectorial representation for each data. We demonstrate the application and effectiveness of our representation method in the supervised prediction tasks on extensive real-world structural graph datasets. The results have gained some unexpected increases compared with a surge of baselines on all the datasets, even if we take the lightweight models as classifiers. Moreover, the proposed methods also conducted experiments in Few-Shot classification scenarios, and the results still show attractive discrimination in rare training samples based inference.
Unsupervised Hashing with Semantic Concept Mining
Sep 23, 2022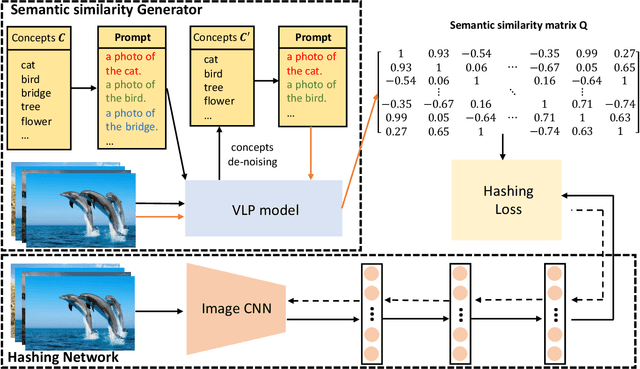
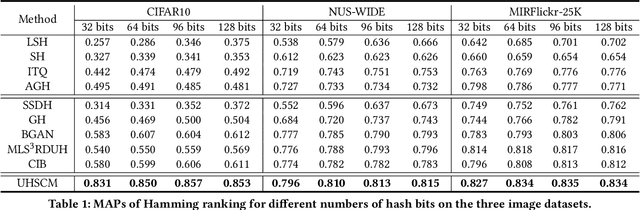
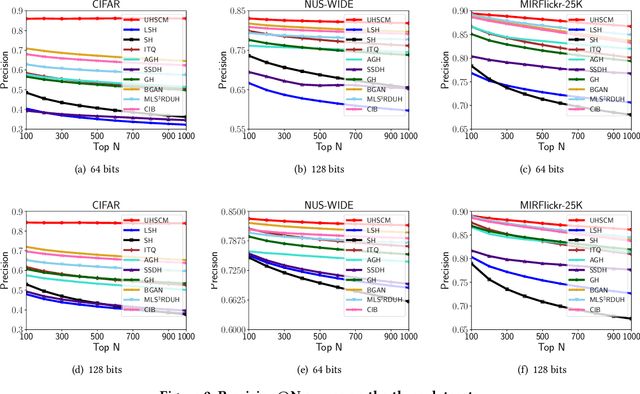
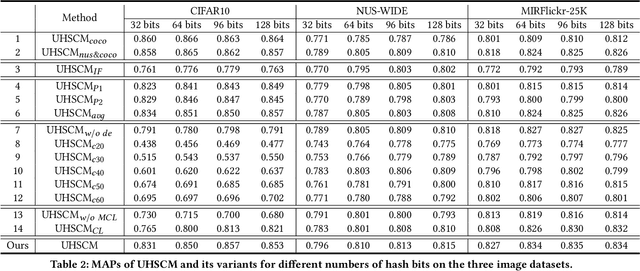
Recently, to improve the unsupervised image retrieval performance, plenty of unsupervised hashing methods have been proposed by designing a semantic similarity matrix, which is based on the similarities between image features extracted by a pre-trained CNN model. However, most of these methods tend to ignore high-level abstract semantic concepts contained in images. Intuitively, concepts play an important role in calculating the similarity among images. In real-world scenarios, each image is associated with some concepts, and the similarity between two images will be larger if they share more identical concepts. Inspired by the above intuition, in this work, we propose a novel Unsupervised Hashing with Semantic Concept Mining, called UHSCM, which leverages a VLP model to construct a high-quality similarity matrix. Specifically, a set of randomly chosen concepts is first collected. Then, by employing a vision-language pretraining (VLP) model with the prompt engineering which has shown strong power in visual representation learning, the set of concepts is denoised according to the training images. Next, the proposed method UHSCM applies the VLP model with prompting again to mine the concept distribution of each image and construct a high-quality semantic similarity matrix based on the mined concept distributions. Finally, with the semantic similarity matrix as guiding information, a novel hashing loss with a modified contrastive loss based regularization item is proposed to optimize the hashing network. Extensive experiments on three benchmark datasets show that the proposed method outperforms the state-of-the-art baselines in the image retrieval task.
Incorporating Casual Analysis into Diversified and Logical Response Generation
Sep 20, 2022Although the Conditional Variational AutoEncoder (CVAE) model can generate more diversified responses than the traditional Seq2Seq model, the responses often have low relevance with the input words or are illogical with the question. A causal analysis is carried out to study the reasons behind, and a methodology of searching for the mediators and mitigating the confounding bias in dialogues is provided. Specifically, we propose to predict the mediators to preserve relevant information and auto-regressively incorporate the mediators into generating process. Besides, a dynamic topic graph guided conditional variational autoencoder (TGG-CVAE) model is utilized to complement the semantic space and reduce the confounding bias in responses. Extensive experiments demonstrate that the proposed model is able to generate both relevant and informative responses, and outperforms the state-of-the-art in terms of automatic metrics and human evaluations.
Multi-level Contrastive Learning Framework for Sequential Recommendation
Aug 27, 2022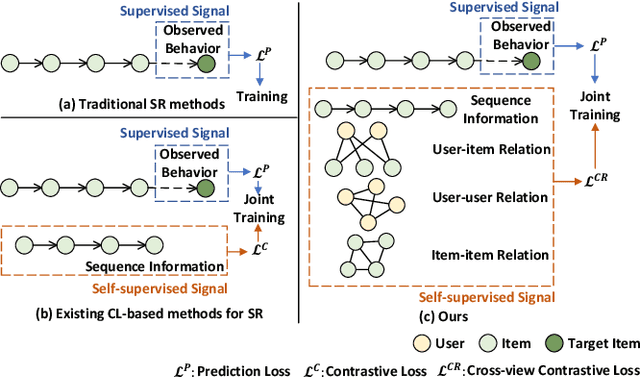
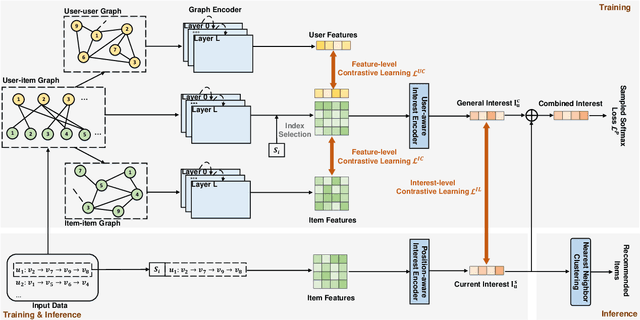
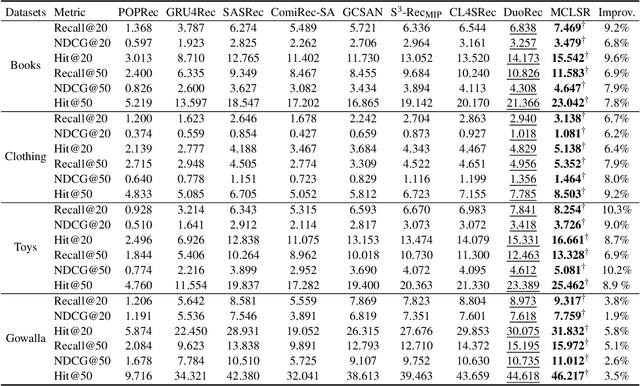
Sequential recommendation (SR) aims to predict the subsequent behaviors of users by understanding their successive historical behaviors. Recently, some methods for SR are devoted to alleviating the data sparsity problem (i.e., limited supervised signals for training), which take account of contrastive learning to incorporate self-supervised signals into SR. Despite their achievements, it is far from enough to learn informative user/item embeddings due to the inadequacy modeling of complex collaborative information and co-action information, such as user-item relation, user-user relation, and item-item relation. In this paper, we study the problem of SR and propose a novel multi-level contrastive learning framework for sequential recommendation, named MCLSR. Different from the previous contrastive learning-based methods for SR, MCLSR learns the representations of users and items through a cross-view contrastive learning paradigm from four specific views at two different levels (i.e., interest- and feature-level). Specifically, the interest-level contrastive mechanism jointly learns the collaborative information with the sequential transition patterns, and the feature-level contrastive mechanism re-observes the relation between users and items via capturing the co-action information (i.e., co-occurrence). Extensive experiments on four real-world datasets show that the proposed MCLSR outperforms the state-of-the-art methods consistently.