 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying the Hierarchical Emotional Areas in the Human Brain Through Information Fusion
Aug 01, 2024



The brain basis of emotion has consistently received widespread attention, attracting a large number of studies to explore this cutting-edge topic. However, the methods employed in these studies typically only model the pairwise relationship between two brain regions, while neglecting the interactions and information fusion among multiple brain regions$\unicode{x2014}$one of the key ideas of the psychological constructionist hypothesis. To overcome the limitations of traditional methods, this study provides an in-depth theoretical analysis of how to maximize interactions and information fusion among brain regions. Building on the results of this analysis, we propose to identify the hierarchical emotional areas in the human brain through multi-source information fusion and graph machine learning methods. Comprehensive experiments reveal that the identified hierarchical emotional areas, from lower to higher levels, primarily facilitate the fundamental process of emotion perception, the construction of basic psychological operations, and the coordination and integration of these operations. Overall, our findings provide unique insights into the brain mechanisms underlying specific emotions based on the psychological constructionist hypothesis.
Human-like object concept representations emerge naturally in multimodal large language models
Jul 01, 2024



The conceptualization and categorization of natural objects in the human mind have long intrigued cognitive scientists and neuroscientists, offering crucial insights into human perception and cognition. Recently, the rapid development of Large Language Models (LLMs) has raised the attractive question of whether these models can also develop human-like object representations through exposure to vast amounts of linguistic and multimodal data. In this study, we combined behavioral and neuroimaging analysis methods to uncover how the object concept representations in LLMs correlate with those of humans. By collecting large-scale datasets of 4.7 million triplet judgments from LLM and Multimodal LLM (MLLM), we were able to derive low-dimensional embeddings that capture the underlying similarity structure of 1,854 natural objects. The resulting 66-dimensional embeddings were found to be highly stable and predictive, and exhibited semantic clustering akin to human mental representations. Interestingly, the interpretability of the dimensions underlying these embeddings suggests that LLM and MLLM have developed human-like conceptual representations of natural objects. Further analysis demonstrated strong alignment between the identified model embeddings and neural activity patterns in many functionally defined brain ROIs (e.g., EBA, PPA, RSC and FFA). This provides compelling evidence that the object representations in LLMs, while not identical to those in the human, share fundamental commonalities that reflect key schemas of human conceptual knowledge. This study advances our understanding of machine intelligence and informs the development of more human-like artificial cognitive systems.
Multi-label Class Incremental Emotion Decoding with Augmented Emotional Semantics Learning
May 31, 2024



Emotion decoding plays an important role in affective human-computer interaction. However, previous studies ignored the dynamic real-world scenario, where human experience a blend of multiple emotions which are incrementally integrated into the model, leading to the multi-label class incremental learning (MLCIL) problem. Existing methods have difficulty in solving MLCIL issue due to notorious catastrophic forgetting caused by partial label problem and inadequate label semantics mining. In this paper, we propose an augmented emotional semantics learning framework for multi-label class incremental emotion decoding. Specifically, we design an augmented emotional relation graph module with label disambiguation to handle the past-missing partial label problem. Then, we leverage domain knowledge from affective dimension space to alleviate future-missing partial label problem by knowledge distillation. Besides, an emotional semantics learning module is constructed with a graph autoencoder to obtain emotion embeddings in order to guide the semantic-specific feature decoupling for better multi-label learning. Extensive experiments on three datasets show the superiority of our method for improving emotion decoding performance and mitigating forgetting on MLCIL problem.
Multi-view Multi-label Fine-grained Emotion Decoding from Human Brain Activity
Oct 26, 2022



Decoding emotional states from human brain activity plays an important role in brain-computer interfaces. Existing emotion decoding methods still have two main limitations: one is only decoding a single emotion category from a brain activity pattern and the decoded emotion categories are coarse-grained, which is inconsistent with the complex emotional expression of human; the other is ignoring the discrepancy of emotion expression between the left and right hemispheres of human brain. In this paper, we propose a novel multi-view multi-label hybrid model for fine-grained emotion decoding (up to 80 emotion categories) which can learn the expressive neural representations and predicting multiple emotional states simultaneously. Specifically, the generative component of our hybrid model is parametrized by a multi-view variational auto-encoder, in which we regard the brain activity of left and right hemispheres and their difference as three distinct views, and use the product of expert mechanism in its inference network. The discriminative component of our hybrid model is implemented by a multi-label classification network with an asymmetric focal loss. For more accurate emotion decoding, we first adopt a label-aware module for emotion-specific neural representations learning and then model the dependency of emotional states by a masked self-attention mechanism. Extensive experiments on two visually evoked emotional datasets show the superiority of our method.
Decoding Visual Neural Representations by Multimodal Learning of Brain-Visual-Linguistic Features
Oct 13, 2022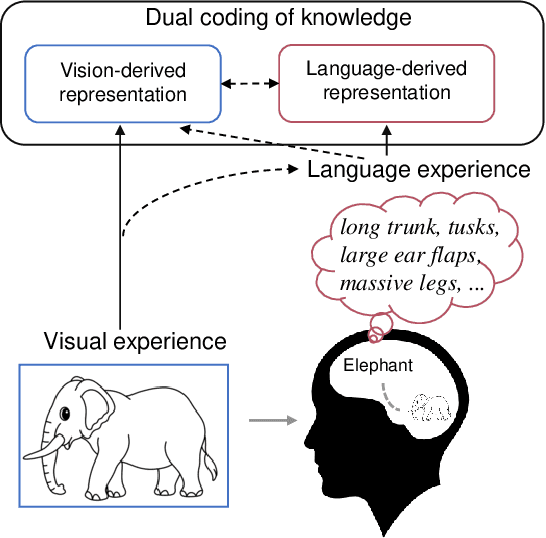

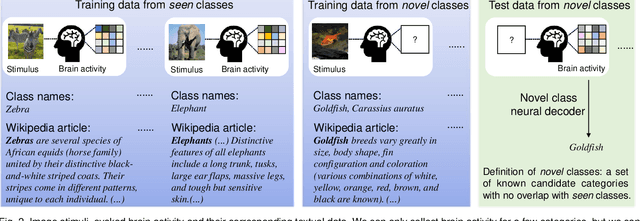
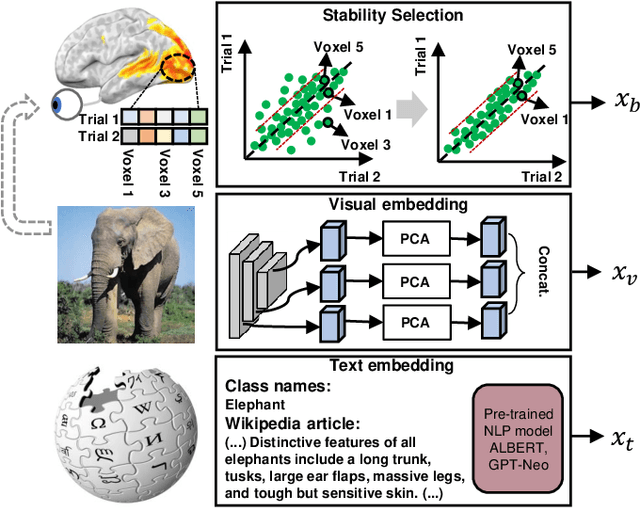
Decoding human visual neural representations is a challenging task with great scientific significance in revealing vision-processing mechanisms and developing brain-like intelligent machines. Most existing methods are difficult to generalize to novel categories that have no corresponding neural data for training. The two main reasons are 1) the under-exploitation of the multimodal semantic knowledge underlying the neural data and 2) the small number of paired (stimuli-responses) training data. To overcome these limitations, this paper presents a generic neural decoding method called BraVL that uses multimodal learning of brain-visual-linguistic features. We focus on modeling the relationships between brain, visual and linguistic features via multimodal deep generative models. Specifically, we leverage the mixture-of-product-of-experts formulation to infer a latent code that enables a coherent joint generation of all three modalities. To learn a more consistent joint representation and improve the data efficiency in the case of limited brain activity data, we exploit both intra- and inter-modality mutual information maximization regularization terms. In particular, our BraVL model can be trained under various semi-supervised scenarios to incorporate the visual and textual features obtained from the extra categories. Finally, we construct three trimodal matching datasets, and the extensive experiments lead to some interesting conclusions and cognitive insights: 1) decoding novel visual categories from human brain activity is practically possible with good accuracy; 2) decoding models using the combination of visual and linguistic features perform much better than those using either of them alone; 3) visual perception may be accompanied by linguistic influences to represent the semantics of visual stimuli. Code and data: https://github.com/ChangdeDu/BraVL.