 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Aware Dialog System Technology Challenge (DSTC11)
Dec 16, 2022



Most research on task oriented dialog modeling is based on written text input. However, users interact with practical dialog systems often using speech as input. Typically, systems convert speech into text using an Automatic Speech Recognition (ASR) system, introducing errors. Furthermore, these systems do not address the differences in written and spoken language. The research on this topic is stymied by the lack of a public corpus. Motivated by these considerations, our goal in hosting the speech-aware dialog state tracking challenge was to create a public corpus or task which can be used to investigate the performance gap between the written and spoken forms of input, develop models that could alleviate this gap, and establish whether Text-to-Speech-based (TTS) systems is a reasonable surrogate to the more-labor intensive human data collection. We created three spoken versions of the popular written-domain MultiWoz task -- (a) TTS-Verbatim: written user inputs were converted into speech waveforms using a TTS system, (b) Human-Verbatim: humans spoke the user inputs verbatim, and (c) Human-paraphrased: humans paraphrased the user inputs. Additionally, we provided different forms of ASR output to encourage wider participation from teams that may not have access to state-of-the-art ASR systems. These included ASR transcripts, word time stamps, and latent representations of the audio (audio encoder outputs). In this paper, we describe the corpus, report results from participating teams, provide preliminary analyses of their results, and summarize the current state-of-the-art in this domain.
An Interpretable Neuron Embedding for Static Knowledge Distillation
Nov 14, 2022



Although deep neural networks have shown well-performance in various tasks, the poor interpretability of the models is always criticized. In the paper, we propose a new interpretable neural network method, by embedding neurons into the semantic space to extract their intrinsic global semantics. In contrast to previous methods that probe latent knowledge inside the model, the proposed semantic vector externalizes the latent knowledge to static knowledge, which is easy to exploit. Specifically, we assume that neurons with similar activation are of similar semantic information. Afterwards, semantic vectors are optimized by continuously aligning activation similarity and semantic vector similarity during the training of the neural network. The visualization of semantic vectors allows for a qualitative explanation of the neural network. Moreover, we assess the static knowledge quantitatively by knowledge distillation tasks. Empirical experiments of visualization show that semantic vectors describe neuron activation semantics well. Without the sample-by-sample guidance from the teacher model, static knowledge distillation exhibit comparable or even superior performance with existing relation-based knowledge distillation methods.
Accelerating RNN-T Training and Inference Using CTC guidance
Oct 29, 2022We propose a novel method to accelerate training and inference process of recurrent neural network transducer (RNN-T) based on the guidance from a co-trained connectionist temporal classification (CTC) model. We made a key assumption that if an encoder embedding frame is classified as a blank frame by the CTC model, it is likely that this frame will be aligned to blank for all the partial alignments or hypotheses in RNN-T and it can be discarded from the decoder input. We also show that this frame reduction operation can be applied in the middle of the encoder, which result in significant speed up for the training and inference in RNN-T. We further show that the CTC alignment, a by-product of the CTC decoder, can also be used to perform lattice reduction for RNN-T during training. Our method is evaluated on the Librispeech and SpeechStew tasks. We demonstrate that the proposed method is able to accelerate the RNN-T inference by 2.2 times with similar or slightly better word error rates (WER).
MM-Align: Learning Optimal Transport-based Alignment Dynamics for Fast and Accurate Inference on Missing Modality Sequences
Oct 23, 2022Existing multimodal tasks mostly target at the complete input modality setting, i.e., each modality is either complete or completely missing in both training and test sets. However, the randomly missing situations have still been underexplored. In this paper, we present a novel approach named MM-Align to address the missing-modality inference problem. Concretely, we propose 1) an alignment dynamics learning module based on the theory of optimal transport (OT) for indirect missing data imputation; 2) a denoising training algorithm to simultaneously enhance the imputation results and backbone network performance. Compared with previous methods which devote to reconstructing the missing inputs, MM-Align learns to capture and imitate the alignment dynamics between modality sequences. Results of comprehensive experiments on three datasets covering two multimodal tasks empirically demonstrate that our method can perform more accurate and faster inference and relieve overfitting under various missing conditions.
SAT: Improving Semi-Supervised Text Classification with Simple Instance-Adaptive Self-Training
Oct 23, 2022Self-training methods have been explored in recent years and have exhibited great performance in improving semi-supervised learning. This work presents a Simple instance-Adaptive self-Training method (SAT) for semi-supervised text classification. SAT first generates two augmented views for each unlabeled data and then trains a meta-learner to automatically identify the relative strength of augmentations based on the similarity between the original view and the augmented views. The weakly-augmented view is fed to the model to produce a pseudo-label and the strongly-augmented view is used to train the model to predict the same pseudo-label. We conducted extensive experiments and analyses on three text classification datasets and found that with varying sizes of labeled training data, SAT consistently shows competitive performance compared to existing semi-supervised learning methods. Our code can be found at \url{https://github.com/declare-lab/SAT.git}.
SANCL: Multimodal Review Helpfulness Prediction with Selective Attention and Natural Contrastive Learning
Sep 16, 2022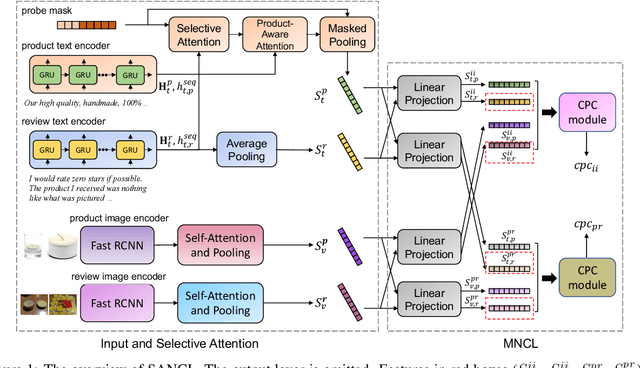
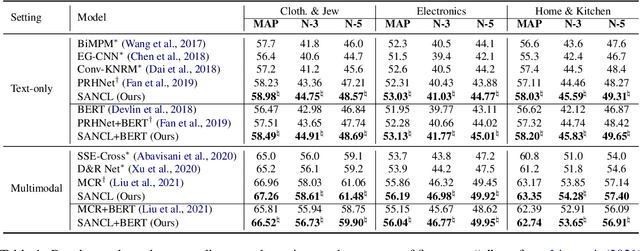
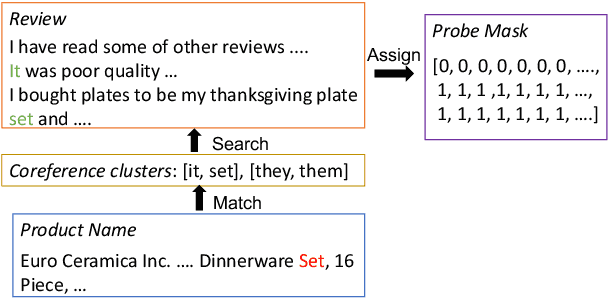
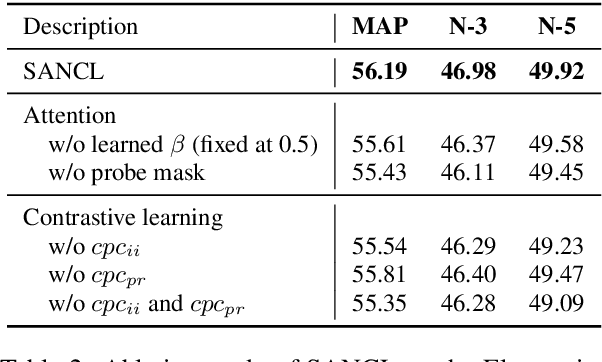
With the boom of e-commerce, Multimodal Review Helpfulness Prediction (MRHP), which aims to sort product reviews according to the predicted helpfulness scores has become a research hotspot. Previous work on this task focuses on attention-based modality fusion, information integration, and relation modeling, which primarily exposes the following drawbacks: 1) the model may fail to capture the really essential information due to its indiscriminate attention formulation; 2) lack appropriate modeling methods that take full advantage of correlation among provided data. In this paper, we propose SANCL: Selective Attention and Natural Contrastive Learning for MRHP. SANCL adopts a probe-based strategy to enforce high attention weights on the regions of greater significance. It also constructs a contrastive learning framework based on natural matching properties in the dataset. Experimental results on two benchmark datasets with three categories show that SANCL achieves state-of-the-art baseline performance with lower memory consumption.
DoubleMix: Simple Interpolation-Based Data Augmentation for Text Classification
Sep 12, 2022
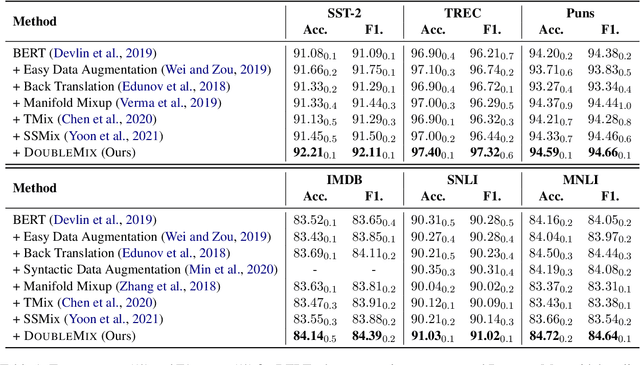
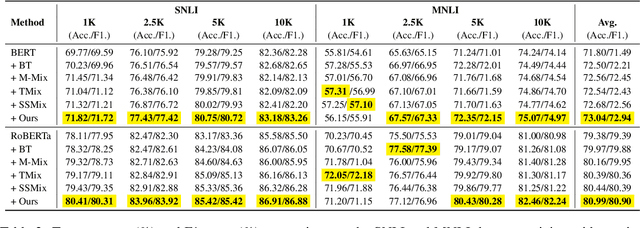
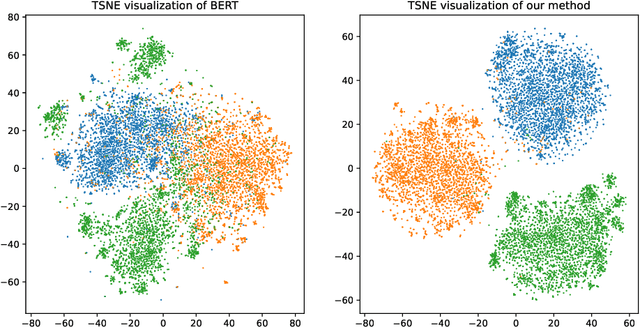
This paper proposes a simple yet effective interpolation-based data augmentation approach termed DoubleMix, to improve the robustness of models in text classification. DoubleMix first leverages a couple of simple augmentation operations to generate several perturbed samples for each training data, and then uses the perturbed data and original data to carry out a two-step interpolation in the hidden space of neural models. Concretely, it first mixes up the perturbed data to a synthetic sample and then mixes up the original data and the synthetic perturbed data. DoubleMix enhances models' robustness by learning the "shifted" features in hidden space. On six text classification benchmark datasets, our approach outperforms several popular text augmentation methods including token-level, sentence-level, and hidden-level data augmentation techniques. Also, experiments in low-resource settings show our approach consistently improves models' performance when the training data is scarce. Extensive ablation studies and case studies confirm that each component of our approach contributes to the final performance and show that our approach exhibits superior performance on challenging counterexamples. Additionally, visual analysis shows that text features generated by our approach are highly interpretable. Our code for this paper can be found at https://github.com/declare-lab/DoubleMix.git.
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jun 22, 2022

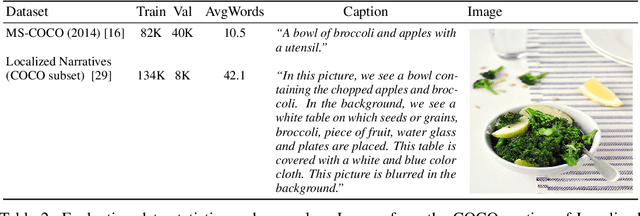
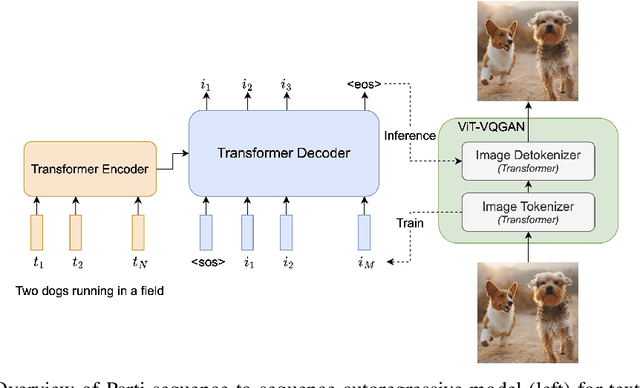
We present the Pathways Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge. Parti treats text-to-image generation as a sequence-to-sequence modeling problem, akin to machine translation, with sequences of image tokens as the target outputs rather than text tokens in another language. This strategy can naturally tap into the rich body of prior work on large language models, which have seen continued advances in capabilities and performance through scaling data and model sizes. Our approach is simple: First, Parti uses a Transformer-based image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens. Second, we achieve consistent quality improvements by scaling the encoder-decoder Transformer model up to 20B parameters, with a new state-of-the-art zero-shot FID score of 7.23 and finetuned FID score of 3.22 on MS-COCO. Our detailed analysis on Localized Narratives as well as PartiPrompts (P2), a new holistic benchmark of over 1600 English prompts, demonstrate the effectiveness of Parti across a wide variety of categories and difficulty aspects. We also explore and highlight limitations of our models in order to define and exemplify key areas of focus for further improvements. See https://parti.research.google/ for high-resolution images.
Accented Speech Recognition: Benchmarking, Pre-training, and Diverse Data
May 16, 2022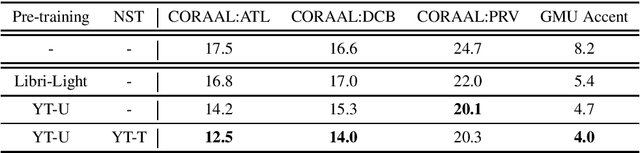

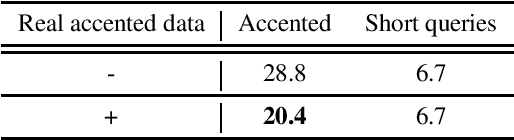
Building inclusive speech recognition systems is a crucial step towards developing technologies that speakers of all language varieties can use. Therefore, ASR systems must work for everybody independently of the way they speak. To accomplish this goal, there should be available data sets representing language varieties, and also an understanding of model configuration that is the most helpful in achieving robust understanding of all types of speech. However, there are not enough data sets for accented speech, and for the ones that are already available, more training approaches need to be explored to improve the quality of accented speech recognition. In this paper, we discuss recent progress towards developing more inclusive ASR systems, namely, the importance of building new data sets representing linguistic diversity, and exploring novel training approaches to improve performance for all users. We address recent directions within benchmarking ASR systems for accented speech, measure the effects of wav2vec 2.0 pre-training on accented speech recognition, and highlight corpora relevant for diverse ASR evaluations.
Unsupervised Data Selection via Discrete Speech Representation for ASR
Apr 05, 2022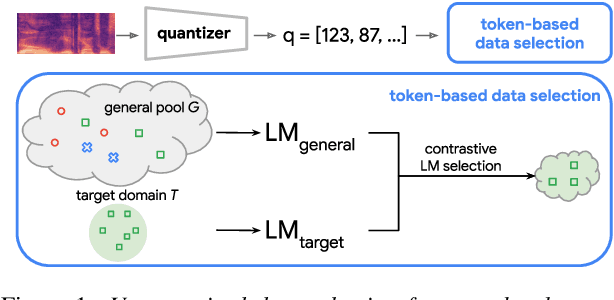


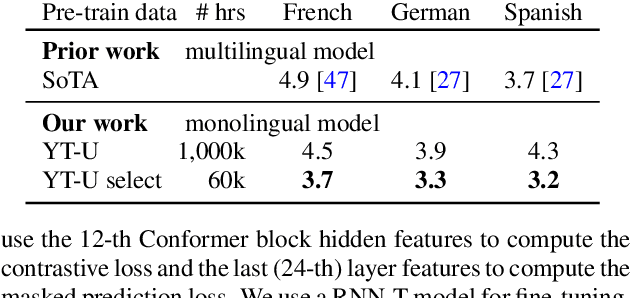
Self-supervised learning of speech representations has achieved impressive results in improving automatic speech recognition (ASR). In this paper, we show that data selection is important for self-supervised learning. We propose a simple and effective unsupervised data selection method which selects acoustically similar speech to a target domain. It takes the discrete speech representation available in common self-supervised learning frameworks as input, and applies a contrastive data selection method on the discrete tokens. Through extensive empirical studies we show that our proposed method reduces the amount of required pre-training data and improves the downstream ASR performance. Pre-training on a selected subset of 6% of the general data pool results in 11.8% relative improvements in LibriSpeech test-other compared to pre-training on the full set. On Multilingual LibriSpeech French, German, and Spanish test sets, selecting 6% data for pre-training reduces word error rate by more than 15% relatively compared to the full set, and achieves competitive results compared to current state-of-the-art performances.