 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Heaviside Low-Rank Support Matrix Machine
Feb 28, 2026Support matrix machine (SMM) is an emerging classification framework that directly handles matrix-structured observations, thereby avoiding the spatial correlations destroyed by vectorization. However, most existing SMM variants rely on convex or nonconvex surrogate loss functions, which may lead to high sensitivity to noise. To address this issue, we propose a novel Heaviside low-rank SMM model called HL-SMM, which leverages the Heaviside loss instead of the common hinge or ramp losses for robustness. Moreover, the low-rank constraint is adopted to accurately characterize the inherent global structure. In theory, we analyze the Karush-Kuhn-Tucker (KKT) points and rigorously prove the sufficient and necessary conditions. In algorithms, we develop an effective proximal alternating minimization (PAM) scheme, where all subproblems have closed-form solutions. Extensive experiments on benchmark datasets validate that the proposed HL-SMM achieves superior classification accuracy and robustness compared to state-of-the-art methods.
Federated Structured Sparse PCA for Anomaly Detection in IoT Networks
Mar 31, 2025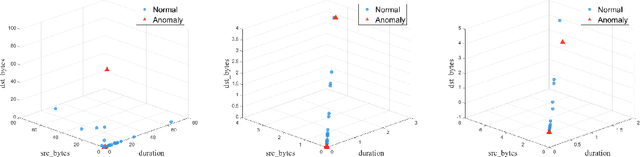
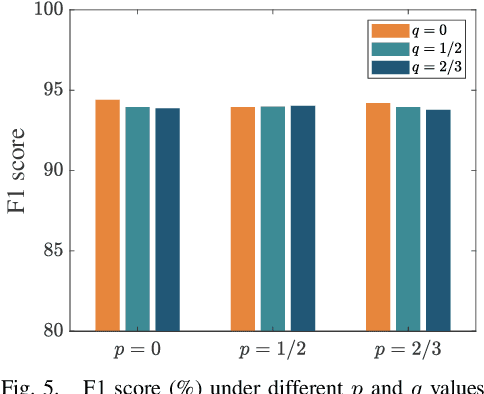
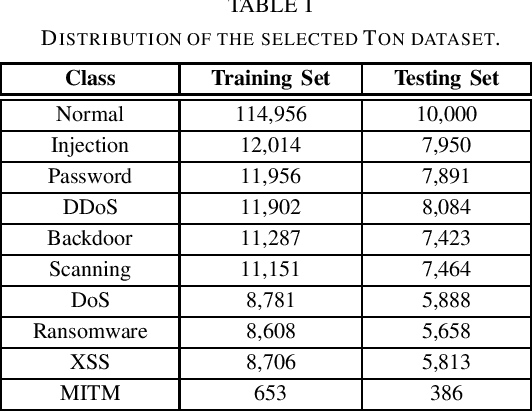
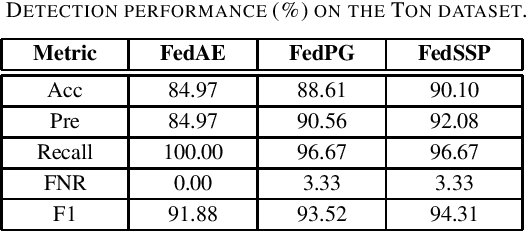
Although federated learning has gained prominence as a privacy-preserving framework tailored for distributed Internet of Things (IoT) environments, current federated principal component analysis (PCA) methods lack integration of sparsity, a critical feature for robust anomaly detection. To address this limitation, we propose a novel federated structured sparse PCA (FedSSP) approach for anomaly detection in IoT networks. The proposed model uniquely integrates double sparsity regularization: (1) row-wise sparsity governed by $\ell_{2,p}$-norm with $p\in[0,1)$ to eliminate redundant feature dimensions, and (2) element-wise sparsity via $\ell_{q}$-norm with $q\in[0,1)$ to suppress noise-sensitive components. To efficiently solve this non-convex optimization problem in a distributed setting, we devise a proximal alternating minimization (PAM) algorithm with rigorous theoretical proofs establishing its convergence guarantees. Experiments on real datasets validate that incorporating structured sparsity enhances both model interpretability and detection accuracy.
Enhancing Unsupervised Feature Selection via Double Sparsity Constrained Optimization
Jan 01, 2025



Unsupervised feature selection (UFS) is widely applied in machine learning and pattern recognition. However, most of the existing methods only consider a single sparsity, which makes it difficult to select valuable and discriminative feature subsets from the original high-dimensional feature set. In this paper, we propose a new UFS method called DSCOFS via embedding double sparsity constrained optimization into the classical principal component analysis (PCA) framework. Double sparsity refers to using $\ell_{2,0}$-norm and $\ell_0$-norm to simultaneously constrain variables, by adding the sparsity of different types, to achieve the purpose of improving the accuracy of identifying differential features. The core is that $\ell_{2,0}$-norm can remove irrelevant and redundant features, while $\ell_0$-norm can filter out irregular noisy features, thereby complementing $\ell_{2,0}$-norm to improve discrimination. An effective proximal alternating minimization method is proposed to solve the resulting nonconvex nonsmooth model. Theoretically, we rigorously prove that the sequence generated by our method globally converges to a stationary point. Numerical experiments on three synthetic datasets and eight real-world datasets demonstrate the effectiveness, stability, and convergence of the proposed method. In particular, the average clustering accuracy (ACC) and normalized mutual information (NMI) are improved by at least 3.34% and 3.02%, respectively, compared with the state-of-the-art methods. More importantly, two common statistical tests and a new feature similarity metric verify the advantages of double sparsity. All results suggest that our proposed DSCOFS provides a new perspective for feature selection.