 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier neural operator for real-time simulation of 3D dynamic urban microclimate
Aug 08, 2023



Global urbanization has underscored the significance of urban microclimates for human comfort, health, and building/urban energy efficiency. They profoundly influence building design and urban planning as major environmental impacts. Understanding local microclimates is essential for cities to prepare for climate change and effectively implement resilience measures. However, analyzing urban microclimates requires considering a complex array of outdoor parameters within computational domains at the city scale over a longer period than indoors. As a result, numerical methods like Computational Fluid Dynamics (CFD) become computationally expensive when evaluating the impact of urban microclimates. The rise of deep learning techniques has opened new opportunities for accelerating the modeling of complex non-linear interactions and system dynamics. Recently, the Fourier Neural Operator (FNO) has been shown to be very promising in accelerating solving the Partial Differential Equations (PDEs) and modeling fluid dynamic systems. In this work, we apply the FNO network for real-time three-dimensional (3D) urban wind field simulation. The training and testing data are generated from CFD simulation of the urban area, based on the semi-Lagrangian approach and fractional stepping method to simulate urban microclimate features for modeling large-scale urban problems. Numerical experiments show that the FNO model can accurately reconstruct the instantaneous spatial velocity field. We further evaluate the trained FNO model on unseen data with different wind directions, and the results show that the FNO model can generalize well on different wind directions. More importantly, the FNO approach can make predictions within milliseconds on the graphics processing unit, making real-time simulation of 3D dynamic urban microclimate possible.
Towards Enabling Cardiac Digital Twins of Myocardial Infarction Using Deep Computational Models for Inverse Inference
Jul 13, 2023



Myocardial infarction (MI) demands precise and swift diagnosis. Cardiac digital twins (CDTs) have the potential to offer individualized evaluation of cardiac function in a non-invasive manner, making them a promising approach for personalized diagnosis and treatment planning of MI. The inference of accurate myocardial tissue properties is crucial in creating a reliable CDT platform, and particularly in the context of studying MI. In this work, we investigate the feasibility of inferring myocardial tissue properties from the electrocardiogram (ECG), focusing on the development of a comprehensive CDT platform specifically designed for MI. The platform integrates multi-modal data, such as cardiac MRI and ECG, to enhance the accuracy and reliability of the inferred tissue properties. We perform a sensitivity analysis based on computer simulations, systematically exploring the effects of infarct location, size, degree of transmurality, and electrical activity alteration on the simulated QRS complex of ECG, to establish the limits of the approach. We subsequently propose a deep computational model to infer infarct location and distribution from the simulated QRS. The in silico experimental results show that our model can effectively capture the complex relationships between the QRS signals and the corresponding infarct regions, with promising potential for clinical application in the future. The code will be released publicly once the manuscript is accepted for publication.
MOPO-LSI: A User Guide
Jul 12, 2023MOPO-LSI is an open-source Multi-Objective Portfolio Optimization Library for Sustainable Investments. This document provides a user guide for MOPO-LSI version 1.0, including problem setup, workflow and the hyper-parameters in configurations.
A Cross-direction Task Decoupling Network for Small Logo Detection
May 04, 2023



Logo detection plays an integral role in many applications. However, handling small logos is still difficult since they occupy too few pixels in the image, which burdens the extraction of discriminative features. The aggregation of small logos also brings a great challenge to the classification and localization of logos. To solve these problems, we creatively propose Cross-direction Task Decoupling Network (CTDNet) for small logo detection. We first introduce Cross-direction Feature Pyramid (CFP) to realize cross-direction feature fusion by adopting horizontal transmission and vertical transmission. In addition, Multi-frequency Task Decoupling Head (MTDH) decouples the classification and localization tasks into two branches. A multi frequency attention convolution branch is designed to achieve more accurate regression by combining discrete cosine transform and convolution creatively. Comprehensive experiments on four logo datasets demonstrate the effectiveness and efficiency of the proposed method.
Influence of Myocardial Infarction on QRS Properties: A Simulation Study
Apr 21, 2023



The interplay between structural and electrical changes in the heart after myocardial infarction (MI) plays a key role in the initiation and maintenance of arrhythmia. The anatomical and electrophysiological properties of scar, border zone, and normal myocardium modify the electrocardiographic morphology, which is routinely analysed in clinical settings. However, the influence of various MI properties on the QRS is not intuitively predictable.In this work, we have systematically investigated the effects of 17 post-MI scenarios, varying the location, size, transmural extent, and conductive level of scarring and border zone area, on the forward-calculated QRS. Additionally, we have compared the contributions of different QRS score criteria for quantifying post-MI pathophysiology.The propagation of electrical activity in the ventricles is simulated via a Eikonal model on a unified coordinate system.The analysis has been performed on 49 subjects, and the results imply that the QRS is capable of identifying MI, suggesting the feasibility of inversely reconstructing infarct regions from QRS.There exist sensitivity variations of different QRS criteria for identifying 17 MI scenarios, which is informative for solving the inverse problem.
The Best of Both Worlds: Accurate Global and Personalized Models through Federated Learning with Data-Free Hyper-Knowledge Distillation
Jan 21, 2023



Heterogeneity of data distributed across clients limits the performance of global models trained through federated learning, especially in the settings with highly imbalanced class distributions of local datasets. In recent years, personalized federated learning (pFL) has emerged as a potential solution to the challenges presented by heterogeneous data. However, existing pFL methods typically enhance performance of local models at the expense of the global model's accuracy. We propose FedHKD (Federated Hyper-Knowledge Distillation), a novel FL algorithm in which clients rely on knowledge distillation (KD) to train local models. In particular, each client extracts and sends to the server the means of local data representations and the corresponding soft predictions -- information that we refer to as ``hyper-knowledge". The server aggregates this information and broadcasts it to the clients in support of local training. Notably, unlike other KD-based pFL methods, FedHKD does not rely on a public dataset nor it deploys a generative model at the server. We analyze convergence of FedHKD and conduct extensive experiments on visual datasets in a variety of scenarios, demonstrating that FedHKD provides significant improvement in both personalized as well as global model performance compared to state-of-the-art FL methods designed for heterogeneous data settings.
Modeling Human Eye Movements with Neural Networks in a Maze-Solving Task
Dec 20, 2022



From smoothly pursuing moving objects to rapidly shifting gazes during visual search, humans employ a wide variety of eye movement strategies in different contexts. While eye movements provide a rich window into mental processes, building generative models of eye movements is notoriously difficult, and to date the computational objectives guiding eye movements remain largely a mystery. In this work, we tackled these problems in the context of a canonical spatial planning task, maze-solving. We collected eye movement data from human subjects and built deep generative models of eye movements using a novel differentiable architecture for gaze fixations and gaze shifts. We found that human eye movements are best predicted by a model that is optimized not to perform the task as efficiently as possible but instead to run an internal simulation of an object traversing the maze. This not only provides a generative model of eye movements in this task but also suggests a computational theory for how humans solve the task, namely that humans use mental simulation.
Adversarial Bi-Regressor Network for Domain Adaptive Regression
Sep 20, 2022
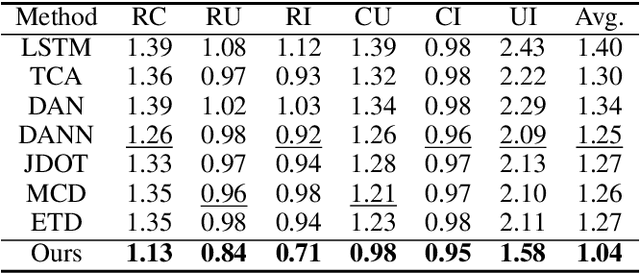
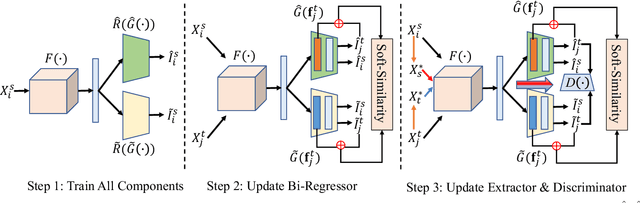
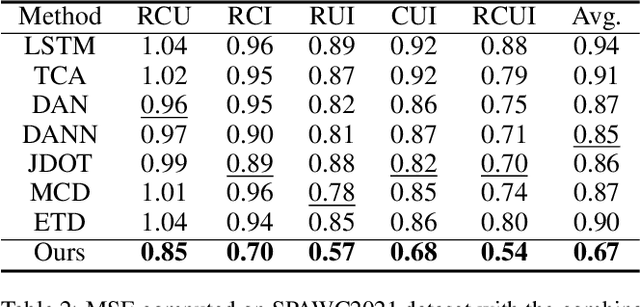
Domain adaptation (DA) aims to transfer the knowledge of a well-labeled source domain to facilitate unlabeled target learning. When turning to specific tasks such as indoor (Wi-Fi) localization, it is essential to learn a cross-domain regressor to mitigate the domain shift. This paper proposes a novel method Adversarial Bi-Regressor Network (ABRNet) to seek more effective cross-domain regression model. Specifically, a discrepant bi-regressor architecture is developed to maximize the difference of bi-regressor to discover uncertain target instances far from the source distribution, and then an adversarial training mechanism is adopted between feature extractor and dual regressors to produce domain-invariant representations. To further bridge the large domain gap, a domain-specific augmentation module is designed to synthesize two source-similar and target-similar intermediate domains to gradually eliminate the original domain mismatch. The empirical studies on two cross-domain regressive benchmarks illustrate the power of our method on solving the domain adaptive regression (DAR) problem.
Balanced Contrastive Learning for Long-Tailed Visual Recognition
Jul 19, 2022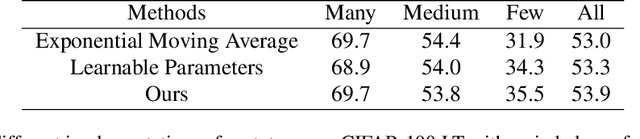
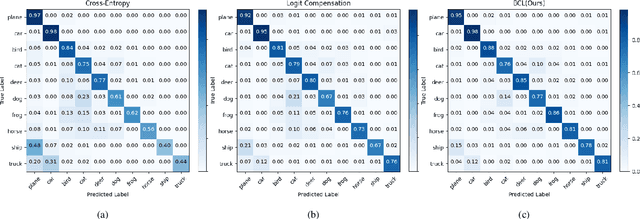
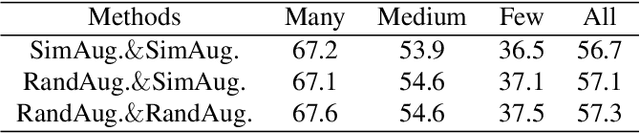
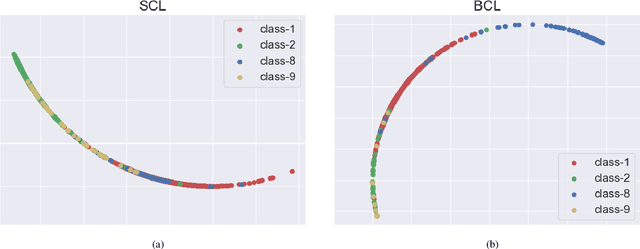
Real-world data typically follow a long-tailed distribution, where a few majority categories occupy most of the data while most minority categories contain a limited number of samples. Classification models minimizing cross-entropy struggle to represent and classify the tail classes. Although the problem of learning unbiased classifiers has been well studied, methods for representing imbalanced data are under-explored. In this paper, we focus on representation learning for imbalanced data. Recently, supervised contrastive learning has shown promising performance on balanced data recently. However, through our theoretical analysis, we find that for long-tailed data, it fails to form a regular simplex which is an ideal geometric configuration for representation learning. To correct the optimization behavior of SCL and further improve the performance of long-tailed visual recognition, we propose a novel loss for balanced contrastive learning (BCL). Compared with SCL, we have two improvements in BCL: class-averaging, which balances the gradient contribution of negative classes; class-complement, which allows all classes to appear in every mini-batch. The proposed balanced contrastive learning (BCL) method satisfies the condition of forming a regular simplex and assists the optimization of cross-entropy. Equipped with BCL, the proposed two-branch framework can obtain a stronger feature representation and achieve competitive performance on long-tailed benchmark datasets such as CIFAR-10-LT, CIFAR-100-LT, ImageNet-LT, and iNaturalist2018. Our code is available at \href{https://github.com/FlamieZhu/BCL}{this URL}.
Masked Co-attentional Transformer reconstructs 100x ultra-fast/low-dose whole-body PET from longitudinal images and anatomically guided MRI
May 09, 2022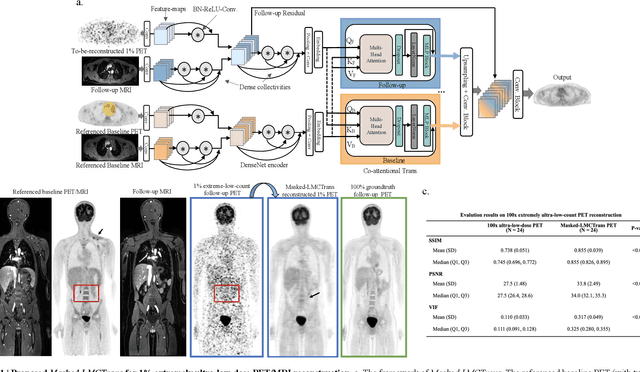
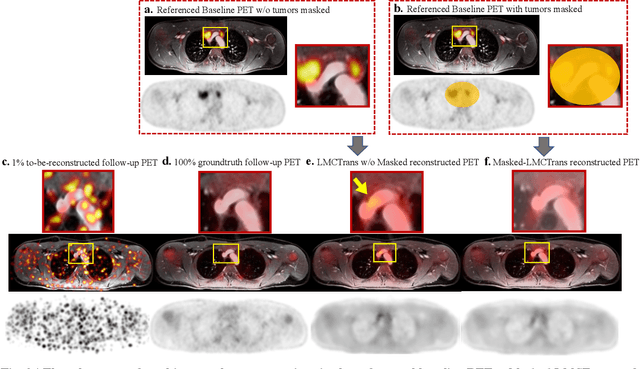
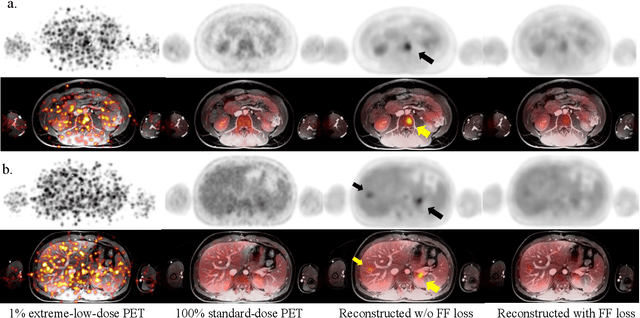
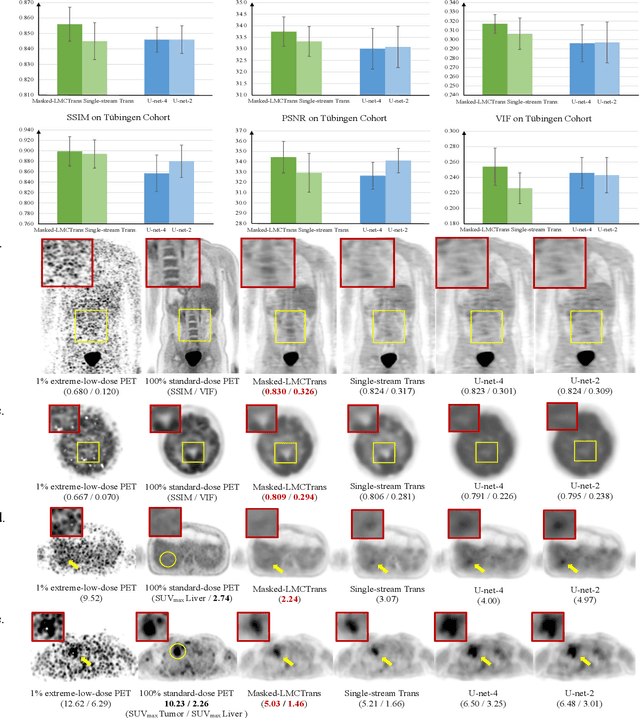
Despite its tremendous value for the diagnosis, treatment monitoring and surveillance of children with cancer, whole body staging with positron emission tomography (PET) is time consuming and associated with considerable radiation exposure. 100x (1% of the standard clinical dosage) ultra-low-dose/ultra-fast whole-body PET reconstruction has the potential for cancer imaging with unprecedented speed and improved safety, but it cannot be achieved by the naive use of machine learning techniques. In this study, we utilize the global similarity between baseline and follow-up PET and magnetic resonance (MR) images to develop Masked-LMCTrans, a longitudinal multi-modality co-attentional CNN-Transformer that provides interaction and joint reasoning between serial PET/MRs of the same patient. We mask the tumor area in the referenced baseline PET and reconstruct the follow-up PET scans. In this manner, Masked-LMCTrans reconstructs 100x almost-zero radio-exposure whole-body PET that was not possible before. The technique also opens a new pathway for longitudinal radiology imaging reconstruction, a significantly under-explored area to date. Our model was trained and tested with Stanford PET/MRI scans of pediatric lymphoma patients and evaluated externally on PET/MRI images from T\"ubingen University. The high image quality of the reconstructed 100x whole-body PET images resulting from the application of Masked-LMCTrans will substantially advance the development of safer imaging approaches and shorter exam-durations for pediatric patients, as well as expand the possibilities for frequent longitudinal monitoring of these patients by PET.