 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Matching for Long-Tail Multi-Label Classification
May 18, 2020
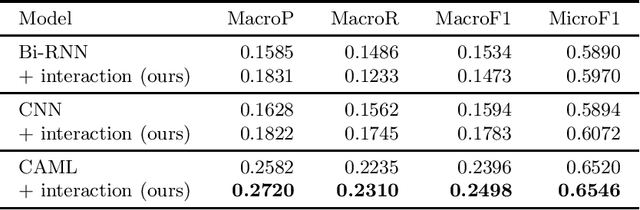
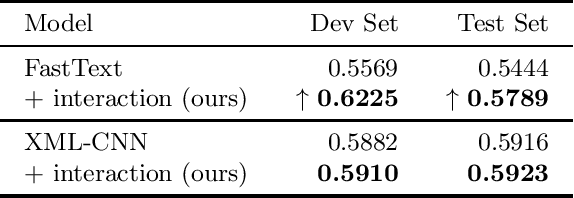
We present an elegant and effective approach for addressing limitations in existing multi-label classification models by incorporating interaction matching, a concept shown to be useful for ad-hoc search result ranking. By performing soft n-gram interaction matching, we match labels with natural language descriptions (which are common to have in most multi-labeling tasks). Our approach can be used to enhance existing multi-label classification approaches, which are biased toward frequently-occurring labels. We evaluate our approach on two challenging tasks: automatic medical coding of clinical notes and automatic labeling of entities from software tutorial text. Our results show that our method can yield up to an 11% relative improvement in macro performance, with most of the gains stemming labels that appear infrequently in the training set (i.e., the long tail of labels).
Variational Hierarchical Dialog Autoencoder for Dialog State Tracking Data Augmentation
Feb 07, 2020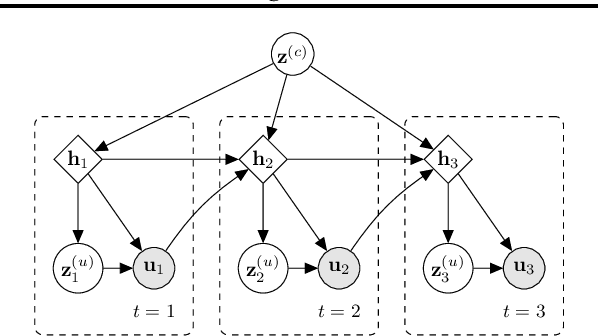
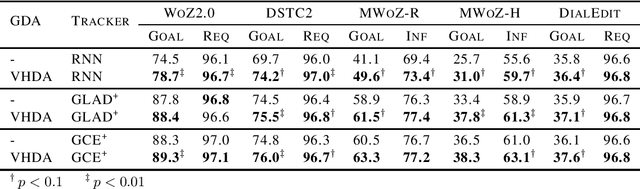
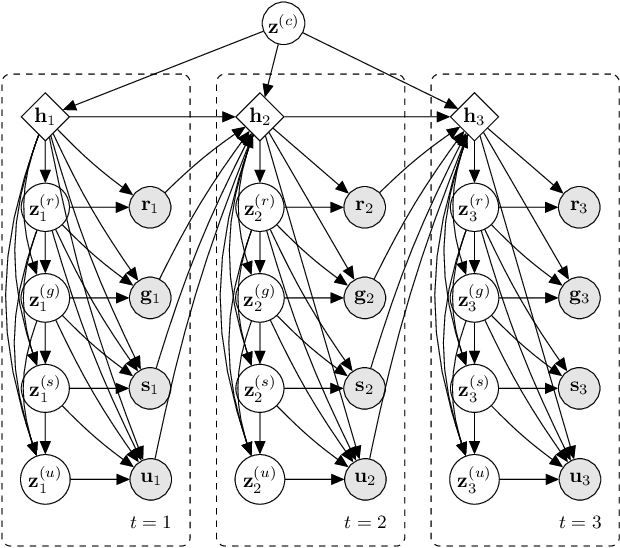
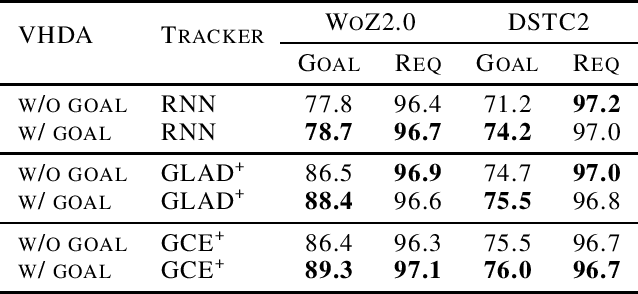
Recent works have shown that generative data augmentation, where synthetic samples generated from deep generative models are used to augment the training dataset, benefit certain NLP tasks. In this work, we extend this approach to the task of dialog state tracking for goal-oriented dialogs. Since, goal-oriented dialogs naturally exhibit a hierarchical structure over utterances and related annotations, deep generative data augmentation for the task requires the generative model to be aware of the hierarchical nature. We propose the Variational Hierarchical Dialog Autoencoder (VHDA) for modeling complete aspects of goal-oriented dialogs, including linguistic features and underlying structured annotations, namely dialog acts and goals. We also propose two training policies to mitigate issues that arise with training VAE-based models. Experiments show that our hierarchical model is able to generate realistic and novel samples that improve the robustness of state-of-the-art dialog state trackers, ultimately improving the dialog state tracking performances on various dialog domains. Surprisingly, the ability to jointly generate dialog features enables our model to outperform previous state-of-the-arts in related subtasks, such as language generation and user simulation.
Rethinking Self-Attention: An Interpretable Self-Attentive Encoder-Decoder Parser
Nov 10, 2019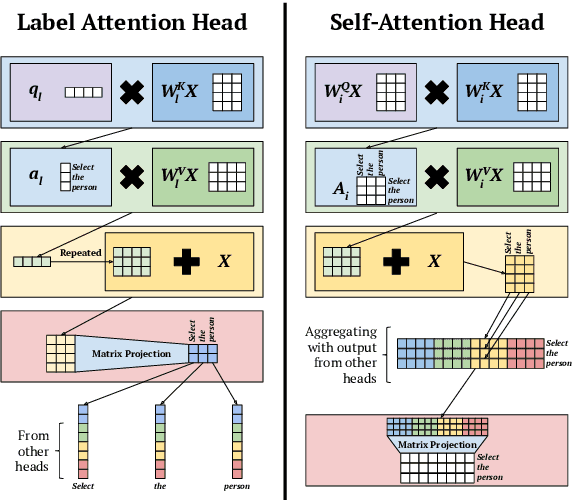
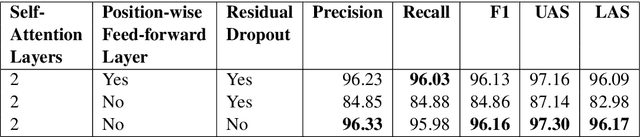
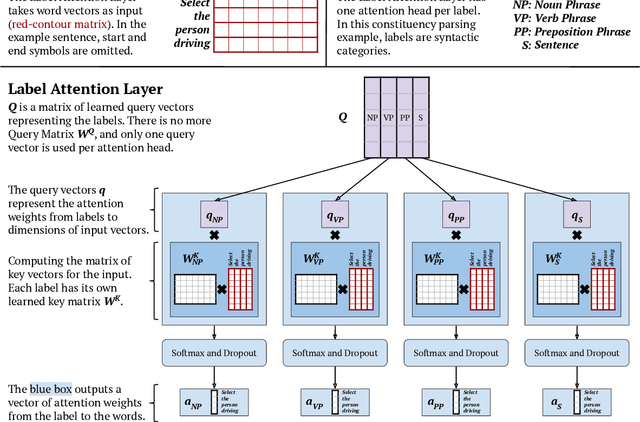
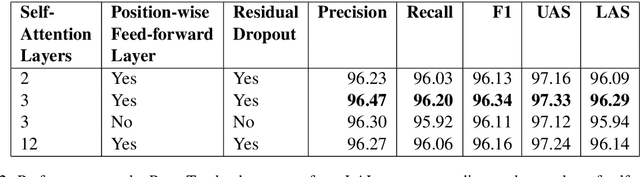
Attention mechanisms have improved the performance of NLP tasks while providing for appearance of model interpretability. Self-attention is currently widely used in NLP models, however it is difficult to interpret due to the numerous attention distributions. We hypothesize that model representations can benefit from label-specific information, while facilitating interpretation of predictions. We introduce the Label Attention Layer: a new form of self-attention where attention heads represent labels. We validate our hypothesis by running experiments in constituency and dependency parsing and show our new model obtains new state-of-the-art results for both tasks on the English Penn Treebank. Our neural parser obtains 96.34 F1 score for constituency parsing, and 97.33 UAS and 96.29 LAS for dependency parsing. Additionally, our model requires fewer layers, therefore, fewer parameters compared to existing work.
Analyzing Sentence Fusion in Abstractive Summarization
Oct 01, 2019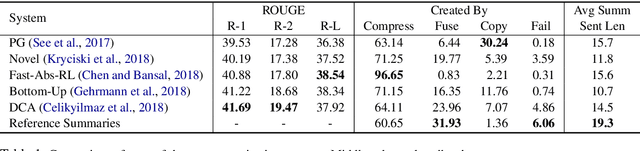
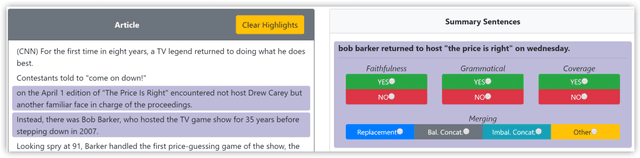
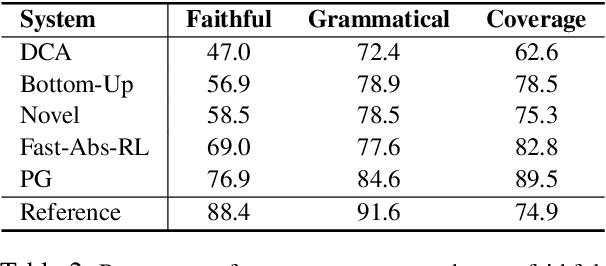
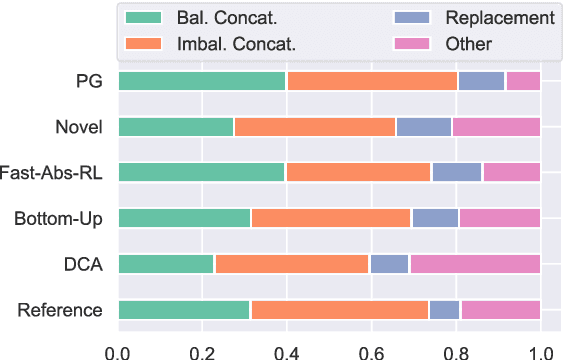
While recent work in abstractive summarization has resulted in higher scores in automatic metrics, there is little understanding on how these systems combine information taken from multiple document sentences. In this paper, we analyze the outputs of five state-of-the-art abstractive summarizers, focusing on summary sentences that are formed by sentence fusion. We ask assessors to judge the grammaticality, faithfulness, and method of fusion for summary sentences. Our analysis reveals that system sentences are mostly grammatical, but often fail to remain faithful to the original article.
Scoring Sentence Singletons and Pairs for Abstractive Summarization
May 31, 2019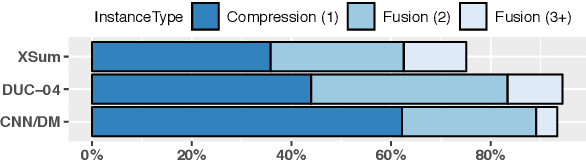

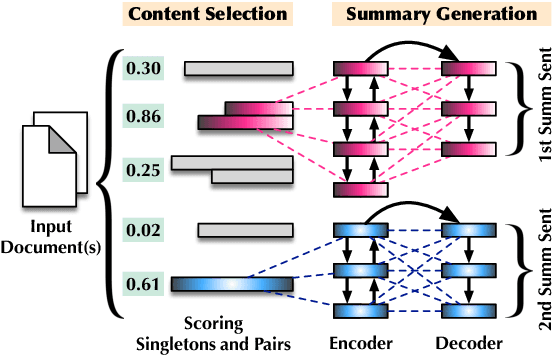
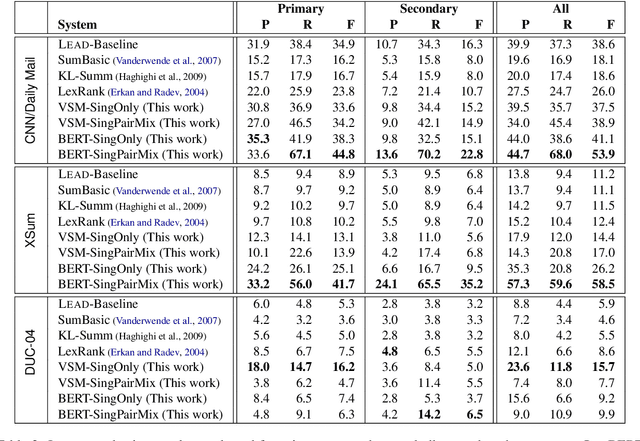
When writing a summary, humans tend to choose content from one or two sentences and merge them into a single summary sentence. However, the mechanisms behind the selection of one or multiple source sentences remain poorly understood. Sentence fusion assumes multi-sentence input; yet sentence selection methods only work with single sentences and not combinations of them. There is thus a crucial gap between sentence selection and fusion to support summarizing by both compressing single sentences and fusing pairs. This paper attempts to bridge the gap by ranking sentence singletons and pairs together in a unified space. Our proposed framework attempts to model human methodology by selecting either a single sentence or a pair of sentences, then compressing or fusing the sentence(s) to produce a summary sentence. We conduct extensive experiments on both single- and multi-document summarization datasets and report findings on sentence selection and abstraction.
Creative Procedural-Knowledge Extraction From Web Design Tutorials
Apr 18, 2019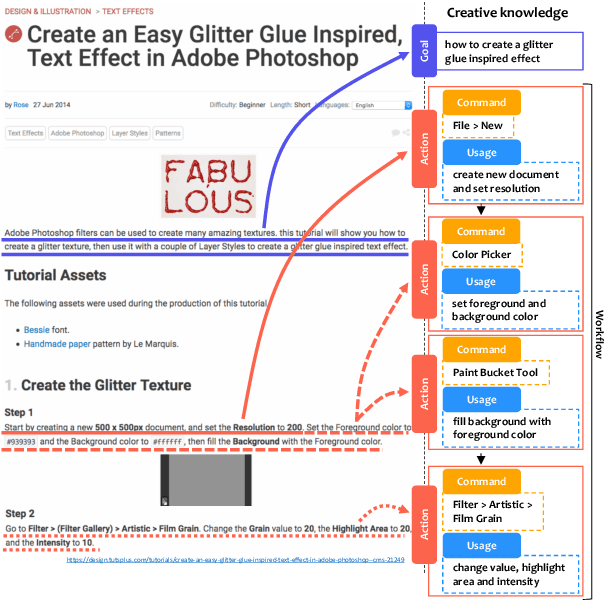

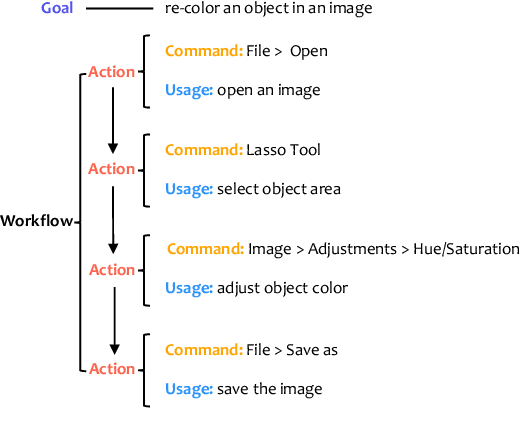
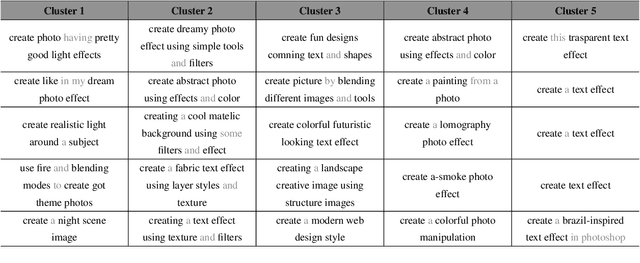
Complex design tasks often require performing diverse actions in a specific order. To (semi-)autonomously accomplish these tasks, applications need to understand and learn a wide range of design procedures, i.e., Creative Procedural-Knowledge (CPK). Prior knowledge base construction and mining have not typically addressed the creative fields, such as design and arts. In this paper, we formalize an ontology of CPK using five components: goal, workflow, action, command and usage; and extract components' values from online design tutorials. We scraped 19.6K tutorial-related webpages and built a web application for professional designers to identify and summarize CPK components. The annotated dataset consists of 819 unique commands, 47,491 actions, and 2,022 workflows and goals. Based on this dataset, we propose a general CPK extraction pipeline and demonstrate that existing text classification and sequence-to-sequence models are limited in identifying, predicting and summarizing complex operations described in heterogeneous styles. Through quantitative and qualitative error analysis, we discuss CPK extraction challenges that need to be addressed by future research.
A System for Automated Image Editing from Natural Language Commands
Dec 03, 2018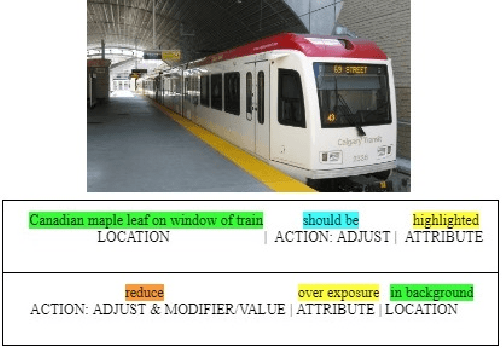
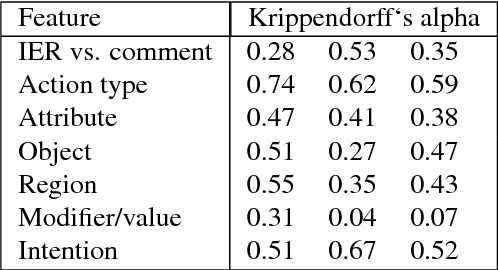
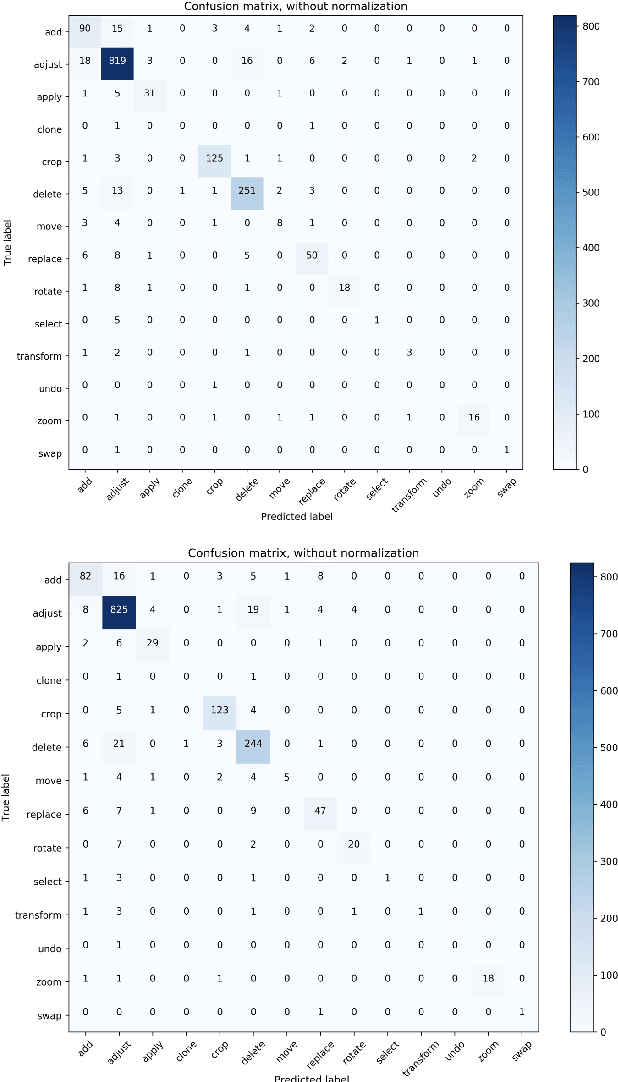
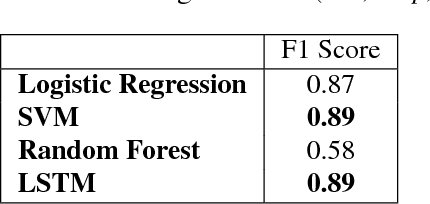
This work presents the task of modifying images in an image editing program using natural language written commands. We utilize a corpus of over 6000 image edit text requests to alter real world images collected via crowdsourcing. A novel framework composed of actions and entities to map a user's natural language request to executable commands in an image editing program is described. We resolve previously labeled annotator disagreement through a voting process and complete annotation of the corpus. We experimented with different machine learning models and found that the LSTM, the SVM, and the bidirectional LSTM-CRF joint models are the best to detect image editing actions and associated entities in a given utterance.
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents
May 22, 2018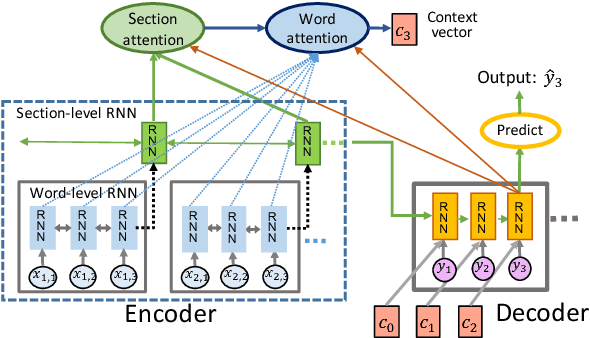
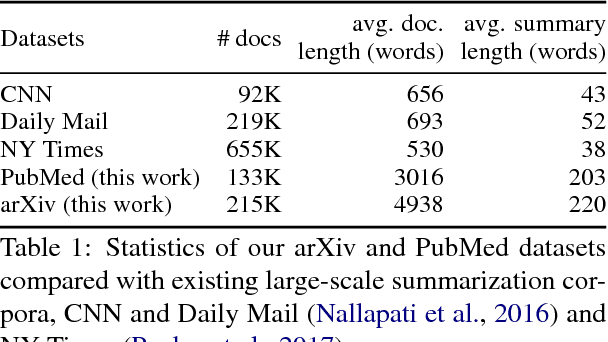
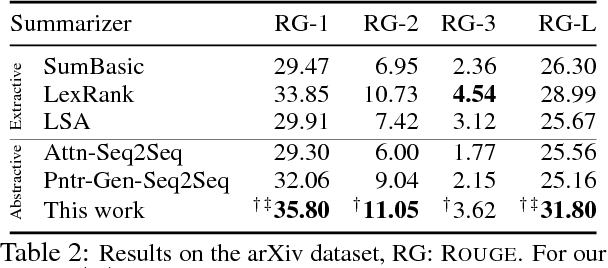
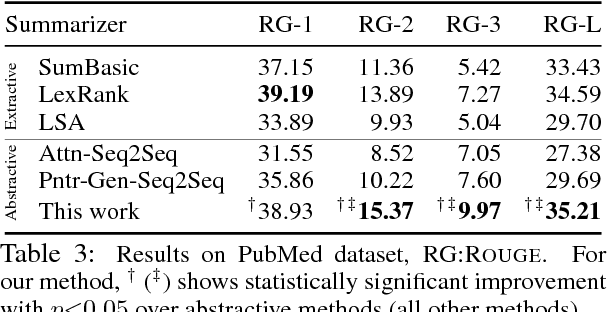
Neural abstractive summarization models have led to promising results in summarizing relatively short documents. We propose the first model for abstractive summarization of single, longer-form documents (e.g., research papers). Our approach consists of a new hierarchical encoder that models the discourse structure of a document, and an attentive discourse-aware decoder to generate the summary. Empirical results on two large-scale datasets of scientific papers show that our model significantly outperforms state-of-the-art models.
Proposing Plausible Answers for Open-ended Visual Question Answering
Oct 24, 2016
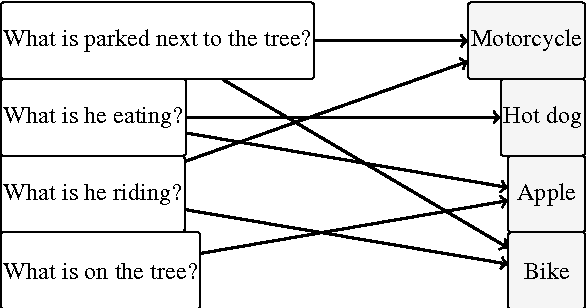
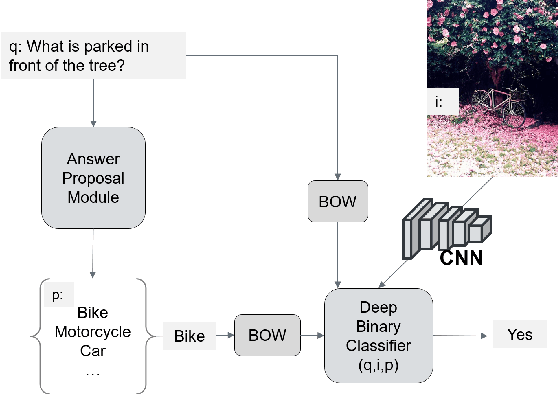

Answering open-ended questions is an essential capability for any intelligent agent. One of the most interesting recent open-ended question answering challenges is Visual Question Answering (VQA) which attempts to evaluate a system's visual understanding through its answers to natural language questions about images. There exist many approaches to VQA, the majority of which do not exhibit deeper semantic understanding of the candidate answers they produce. We study the importance of generating plausible answers to a given question by introducing the novel task of `Answer Proposal': for a given open-ended question, a system should generate a ranked list of candidate answers informed by the semantics of the question. We experiment with various models including a neural generative model as well as a semantic graph matching one. We provide both intrinsic and extrinsic evaluations for the task of Answer Proposal, showing that our best model learns to propose plausible answers with a high recall and performs competitively with some other solutions to VQA.
Automatic Annotation of Structured Facts in Images
Apr 08, 2016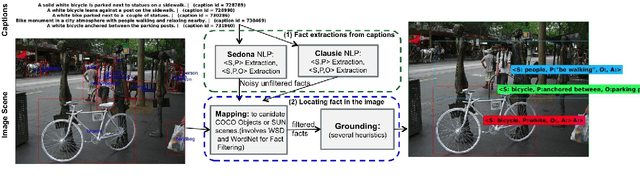

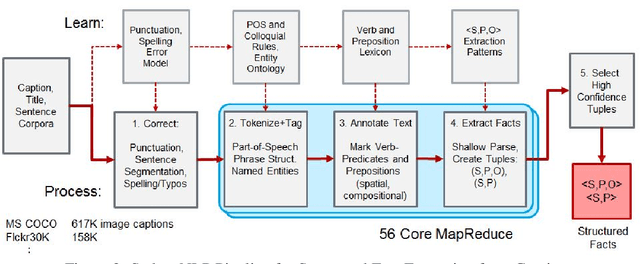

Motivated by the application of fact-level image understanding, we present an automatic method for data collection of structured visual facts from images with captions. Example structured facts include attributed objects (e.g., <flower, red>), actions (e.g., <baby, smile>), interactions (e.g., <man, walking, dog>), and positional information (e.g., <vase, on, table>). The collected annotations are in the form of fact-image pairs (e.g.,<man, walking, dog> and an image region containing this fact). With a language approach, the proposed method is able to collect hundreds of thousands of visual fact annotations with accuracy of 83% according to human judgment. Our method automatically collected more than 380,000 visual fact annotations and more than 110,000 unique visual facts from images with captions and localized them in images in less than one day of processing time on standard CPU platforms.