 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThoughts without Thinking: Reconsidering the Explanatory Value of Chain-of-Thought Reasoning in LLMs through Agentic Pipelines
May 01, 2025



Agentic pipelines present novel challenges and opportunities for human-centered explainability. The HCXAI community is still grappling with how best to make the inner workings of LLMs transparent in actionable ways. Agentic pipelines consist of multiple LLMs working in cooperation with minimal human control. In this research paper, we present early findings from an agentic pipeline implementation of a perceptive task guidance system. Through quantitative and qualitative analysis, we analyze how Chain-of-Thought (CoT) reasoning, a common vehicle for explainability in LLMs, operates within agentic pipelines. We demonstrate that CoT reasoning alone does not lead to better outputs, nor does it offer explainability, as it tends to produce explanations without explainability, in that they do not improve the ability of end users to better understand systems or achieve their goals.
QPM: Discrete Optimization for Globally Interpretable Image Classification
Feb 27, 2025



Understanding the classifications of deep neural networks, e.g. used in safety-critical situations, is becoming increasingly important. While recent models can locally explain a single decision, to provide a faithful global explanation about an accurate model's general behavior is a more challenging open task. Towards that goal, we introduce the Quadratic Programming Enhanced Model (QPM), which learns globally interpretable class representations. QPM represents every class with a binary assignment of very few, typically 5, features, that are also assigned to other classes, ensuring easily comparable contrastive class representations. This compact binary assignment is found using discrete optimization based on predefined similarity measures and interpretability constraints. The resulting optimal assignment is used to fine-tune the diverse features, so that each of them becomes the shared general concept between the assigned classes. Extensive evaluations show that QPM delivers unprecedented global interpretability across small and large-scale datasets while setting the state of the art for the accuracy of interpretable models.
QA-TOOLBOX: Conversational Question-Answering for process task guidance in manufacturing
Dec 03, 2024



In this work we explore utilizing LLMs for data augmentation for manufacturing task guidance system. The dataset consists of representative samples of interactions with technicians working in an advanced manufacturing setting. The purpose of this work to explore the task, data augmentation for the supported tasks and evaluating the performance of the existing LLMs. We observe that that task is complex requiring understanding from procedure specification documents, actions and objects sequenced temporally. The dataset consists of 200,000+ question/answer pairs that refer to the spec document and are grounded in narrations and/or video demonstrations. We compared the performance of several popular open-sourced LLMs by developing a baseline using each LLM and then compared the responses in a reference-free setting using LLM-as-a-judge and compared the ratings with crowd-workers whilst validating the ratings with experts.
Decoding Biases: Automated Methods and LLM Judges for Gender Bias Detection in Language Models
Aug 07, 2024



Large Language Models (LLMs) have excelled at language understanding and generating human-level text. However, even with supervised training and human alignment, these LLMs are susceptible to adversarial attacks where malicious users can prompt the model to generate undesirable text. LLMs also inherently encode potential biases that can cause various harmful effects during interactions. Bias evaluation metrics lack standards as well as consensus and existing methods often rely on human-generated templates and annotations which are expensive and labor intensive. In this work, we train models to automatically create adversarial prompts to elicit biased responses from target LLMs. We present LLM- based bias evaluation metrics and also analyze several existing automatic evaluation methods and metrics. We analyze the various nuances of model responses, identify the strengths and weaknesses of model families, and assess where evaluation methods fall short. We compare these metrics to human evaluation and validate that the LLM-as-a-Judge metric aligns with human judgement on bias in response generation.
Zero-shot Conversational Summarization Evaluations with small Large Language Models
Nov 29, 2023



Large Language Models (LLMs) exhibit powerful summarization abilities. However, their capabilities on conversational summarization remains under explored. In this work we evaluate LLMs (approx. 10 billion parameters) on conversational summarization and showcase their performance on various prompts. We show that the summaries generated by models depend on the instructions and the performance of LLMs vary with different instructions sometimes resulting steep drop in ROUGE scores if prompts are not selected carefully. We also evaluate the models with human evaluations and discuss the limitations of the models on conversational summarization
Sample Efficient Multimodal Semantic Augmentation for Incremental Summarization
Mar 08, 2023



In this work, we develop a prompting approach for incremental summarization of task videos. We develop a sample-efficient few-shot approach for extracting semantic concepts as an intermediate step. We leverage an existing model for extracting the concepts from the images and extend it to videos and introduce a clustering and querying approach for sample efficiency, motivated by the recent advances in perceiver-based architectures. Our work provides further evidence that an approach with richer input context with relevant entities and actions from the videos and using these as prompts could enhance the summaries generated by the model. We show the results on a relevant dataset and discuss possible directions for the work.
Position Matters! Empirical Study of Order Effect in Knowledge-grounded Dialogue
Feb 12, 2023



With the power of large pretrained language models, various research works have integrated knowledge into dialogue systems. The traditional techniques treat knowledge as part of the input sequence for the dialogue system, prepending a set of knowledge statements in front of dialogue history. However, such a mechanism forces knowledge sets to be concatenated in an ordered manner, making models implicitly pay imbalanced attention to the sets during training. In this paper, we first investigate how the order of the knowledge set can influence autoregressive dialogue systems' responses. We conduct experiments on two commonly used dialogue datasets with two types of transformer-based models and find that models view the input knowledge unequally. To this end, we propose a simple and novel technique to alleviate the order effect by modifying the position embeddings of knowledge input in these models. With the proposed position embedding method, the experimental results show that each knowledge statement is uniformly considered to generate responses.
Human in the loop approaches in multi-modal conversational task guidance system development
Nov 03, 2022



Development of task guidance systems for aiding humans in a situated task remains a challenging problem. The role of search (information retrieval) and conversational systems for task guidance has immense potential to help the task performers achieve various goals. However, there are several technical challenges that need to be addressed to deliver such conversational systems, where common supervised approaches fail to deliver the expected results in terms of overall performance, user experience and adaptation to realistic conditions. In this preliminary work we first highlight some of the challenges involved during the development of such systems. We then provide an overview of existing datasets available and highlight their limitations. We finally develop a model-in-the-loop wizard-of-oz based data collection tool and perform a pilot experiment.
Distill and Collect for Semi-Supervised Temporal Action Segmentation
Nov 03, 2022



Recent temporal action segmentation approaches need frame annotations during training to be effective. These annotations are very expensive and time-consuming to obtain. This limits their performances when only limited annotated data is available. In contrast, we can easily collect a large corpus of in-domain unannotated videos by scavenging through the internet. Thus, this paper proposes an approach for the temporal action segmentation task that can simultaneously leverage knowledge from annotated and unannotated video sequences. Our approach uses multi-stream distillation that repeatedly refines and finally combines their frame predictions. Our model also predicts the action order, which is later used as a temporal constraint while estimating frames labels to counter the lack of supervision for unannotated videos. In the end, our evaluation of the proposed approach on two different datasets demonstrates its capability to achieve comparable performance to the full supervision despite limited annotation.
Controllable Response Generation for Assistive Use-cases
Dec 04, 2021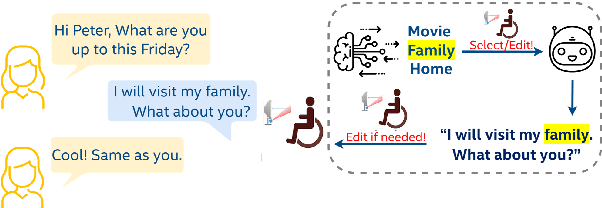
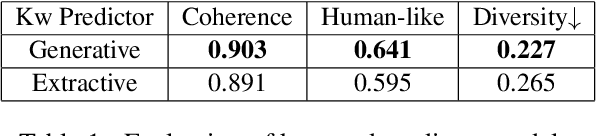
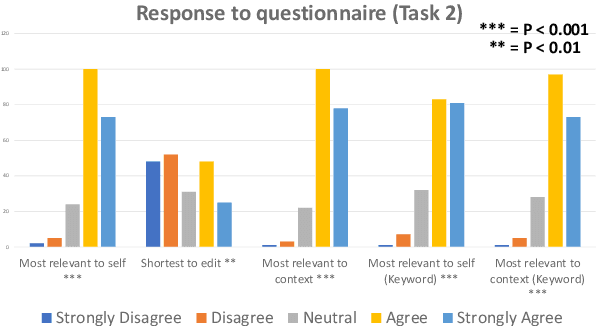
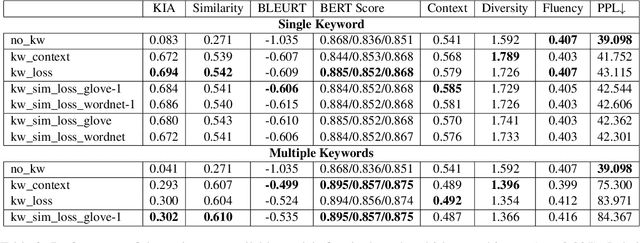
Conversational agents have become an integral part of the general population for simple task enabling situations. However, these systems are yet to have any social impact on the diverse and minority population, for example, helping people with neurological disorders, for example ALS, and people with speech, language and social communication disorders. Language model technology can play a huge role to help these users carry out daily communication and social interactions. To enable this population, we build a dialog system that can be controlled by users using cues or keywords. We build models that can suggest relevant cues in the dialog response context which is used to control response generation and can speed up communication. We also introduce a keyword loss to lexically constrain the model output. We show both qualitatively and quantitatively that our models can effectively induce the keyword into the model response without degrading the quality of response. In the context of usage of such systems for people with degenerative disorders, we present human evaluation of our cue or keyword predictor and the controllable dialog system and show that our models perform significantly better than models without control. Our study shows that keyword control on end to end response generation models is powerful and can enable and empower users with degenerative disorders to carry out their day to day communication.