 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMNESIA: A Large Scale Medical Unlearning Benchmark Suite with Disease-Informed Analysis
May 28, 2026Medical knowledge is continuously evolving. This creates a need to update or selectively forget information encoded in already-trained medical LLMs. Machine unlearning aims to remove the influence of specific training data from a model without full retraining. Yet, existing unlearning benchmarks rely on synthetic or small-scale general data, leaving clinical unlearning understudied. We introduce AMNESIA, the first large-scale, open source benchmark for medical unlearning, with 70,560 question-answer pairs from 8,820 patient notes across 11 disease categories. AMNESIA includes both factual questions testing direct recall and reasoning questions testing clinical inference. We use it to evaluate four widely used unlearning methods at both random patient and disease-level, and introduce a new metric for detecting leakage of medical terminology. We show that unlearning individual patients erodes knowledge of others with the same condition, calling for methods that can better separate patients from shared clinical knowledge.
TARAZ: Persian Short-Answer Question Benchmark for Cultural Evaluation of Language Models
Feb 26, 2026This paper presents a comprehensive evaluation framework for assessing the cultural competence of large language models (LLMs) in Persian. Existing Persian cultural benchmarks rely predominantly on multiple-choice formats and English-centric metrics that fail to capture Persian's morphological complexity and semantic nuance. Our framework introduces a Persian-specific short-answer evaluation that combines rule-based morphological normalization with a hybrid syntactic and semantic similarity module, enabling robust soft-match scoring beyond exact string overlap. Through systematic evaluation of 15 state-of-the-art open- and closed-source models, we demonstrate that our hybrid evaluation improves scoring consistency by +10% compared to exact-match baselines by capturing meaning that surface-level methods cannot detect. We publicly release our evaluation framework, providing the first standardized benchmark for measuring cultural understanding in Persian and establishing a reproducible foundation for cross-cultural LLM evaluation research.
A Picture of Agentic Search
Feb 19, 2026With automated systems increasingly issuing search queries alongside humans, Information Retrieval (IR) faces a major shift. Yet IR remains human-centred, with systems, evaluation metrics, user models, and datasets designed around human queries and behaviours. Consequently, IR operates under assumptions that no longer hold in practice, with changes to workload volumes, predictability, and querying behaviours. This misalignment affects system performance and optimisation: caching may lose effectiveness, query pre-processing may add overhead without improving results, and standard metrics may mismeasure satisfaction. Without adaptation, retrieval models risk satisfying neither humans, nor the emerging user segment of agents. However, datasets capturing agent search behaviour are lacking, which is a critical gap given IR's historical reliance on data-driven evaluation and optimisation. We develop a methodology for collecting all the data produced and consumed by agentic retrieval-augmented systems when answering queries, and we release the Agentic Search Queryset (ASQ) dataset. ASQ contains reasoning-induced queries, retrieved documents, and thoughts for queries in HotpotQA, Researchy Questions, and MS MARCO, for 3 diverse agents and 2 retrieval pipelines. The accompanying toolkit enables ASQ to be extended to new agents, retrievers, and datasets.
DRAMA: Domain Retrieval using Adaptive Module Allocation
Feb 16, 2026Neural models are increasingly used in Web-scale Information Retrieval (IR). However, relying on these models introduces substantial computational and energy requirements, leading to increasing attention toward their environmental cost and the sustainability of large-scale deployments. While neural IR models deliver high retrieval effectiveness, their scalability is constrained in multi-domain scenarios, where training and maintaining domain-specific models is inefficient and achieving robust cross-domain generalisation within a unified model remains difficult. This paper introduces DRAMA (Domain Retrieval using Adaptive Module Allocation), an energy- and parameter-efficient framework designed to reduce the environmental footprint of neural retrieval. DRAMA integrates domain-specific adapter modules with a dynamic gating mechanism that selects the most relevant domain knowledge for each query. New domains can be added efficiently through lightweight adapter training, avoiding full model retraining. We evaluate DRAMA on multiple Web retrieval benchmarks covering different domains. Our extensive evaluation shows that DRAMA achieves comparable effectiveness to domain-specific models while using only a fraction of their parameters and computational resources. These findings show that energy-aware model design can significantly improve scalability and sustainability in neural IR.
Lexically-Accelerated Dense Retrieval
Jul 31, 2023Retrieval approaches that score documents based on learned dense vectors (i.e., dense retrieval) rather than lexical signals (i.e., conventional retrieval) are increasingly popular. Their ability to identify related documents that do not necessarily contain the same terms as those appearing in the user's query (thereby improving recall) is one of their key advantages. However, to actually achieve these gains, dense retrieval approaches typically require an exhaustive search over the document collection, making them considerably more expensive at query-time than conventional lexical approaches. Several techniques aim to reduce this computational overhead by approximating the results of a full dense retriever. Although these approaches reasonably approximate the top results, they suffer in terms of recall -- one of the key advantages of dense retrieval. We introduce 'LADR' (Lexically-Accelerated Dense Retrieval), a simple-yet-effective approach that improves the efficiency of existing dense retrieval models without compromising on retrieval effectiveness. LADR uses lexical retrieval techniques to seed a dense retrieval exploration that uses a document proximity graph. We explore two variants of LADR: a proactive approach that expands the search space to the neighbors of all seed documents, and an adaptive approach that selectively searches the documents with the highest estimated relevance in an iterative fashion. Through extensive experiments across a variety of dense retrieval models, we find that LADR establishes a new dense retrieval effectiveness-efficiency Pareto frontier among approximate k nearest neighbor techniques. Further, we find that when tuned to take around 8ms per query in retrieval latency on our hardware, LADR consistently achieves both precision and recall that are on par with an exhaustive search on standard benchmarks.
Caching Historical Embeddings in Conversational Search
Nov 25, 2022



Rapid response, namely low latency, is fundamental in search applications; it is particularly so in interactive search sessions, such as those encountered in conversational settings. An observation with a potential to reduce latency asserts that conversational queries exhibit a temporal locality in the lists of documents retrieved. Motivated by this observation, we propose and evaluate a client-side document embedding cache, improving the responsiveness of conversational search systems. By leveraging state-of-the-art dense retrieval models to abstract document and query semantics, we cache the embeddings of documents retrieved for a topic introduced in the conversation, as they are likely relevant to successive queries. Our document embedding cache implements an efficient metric index, answering nearest-neighbor similarity queries by estimating the approximate result sets returned. We demonstrate the efficiency achieved using our cache via reproducible experiments based on TREC CAsT datasets, achieving a hit rate of up to 75% without degrading answer quality. Our achieved high cache hit rates significantly improve the responsiveness of conversational systems while likewise reducing the number of queries managed on the search back-end.
Self-supervised Representation Learning on Electronic Health Records with Graph Kernel Infomax
Sep 01, 2022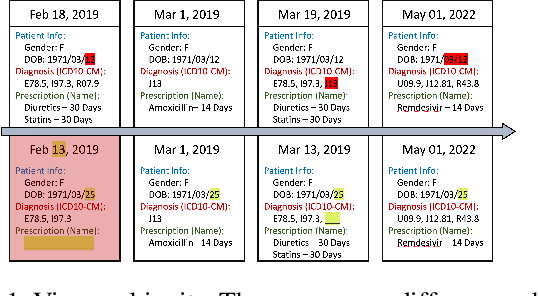
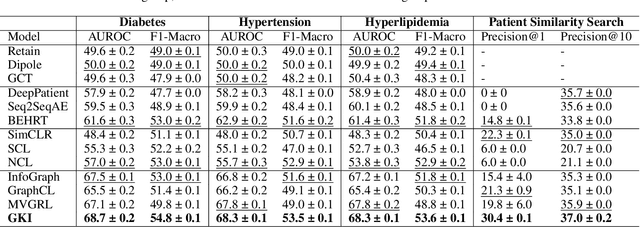
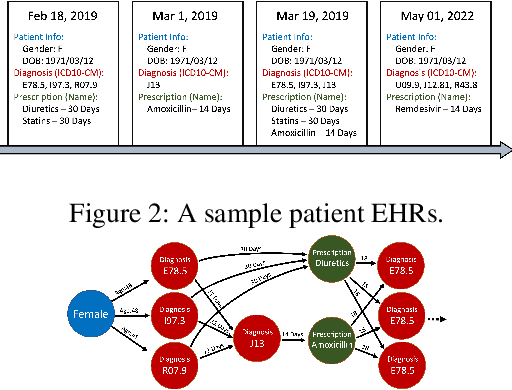

Learning Electronic Health Records (EHRs) representation is a preeminent yet under-discovered research topic. It benefits various clinical decision support applications, e.g., medication outcome prediction or patient similarity search. Current approaches focus on task-specific label supervision on vectorized sequential EHR, which is not applicable to large-scale unsupervised scenarios. Recently, contrastive learning shows great success on self-supervised representation learning problems. However, complex temporality often degrades the performance. We propose Graph Kernel Infomax, a self-supervised graph kernel learning approach on the graphical representation of EHR, to overcome the previous problems. Unlike the state-of-the-art, we do not change the graph structure to construct augmented views. Instead, we use Kernel Subspace Augmentation to embed nodes into two geometrically different manifold views. The entire framework is trained by contrasting nodes and graph representations on those two manifold views through the commonly used contrastive objectives. Empirically, using publicly available benchmark EHR datasets, our approach yields performance on clinical downstream tasks that exceeds the state-of-the-art. Theoretically, the variation on distance metrics naturally creates different views as data augmentation without changing graph structures.
TAR on Social Media: A Framework for Online Content Moderation
Aug 29, 2021
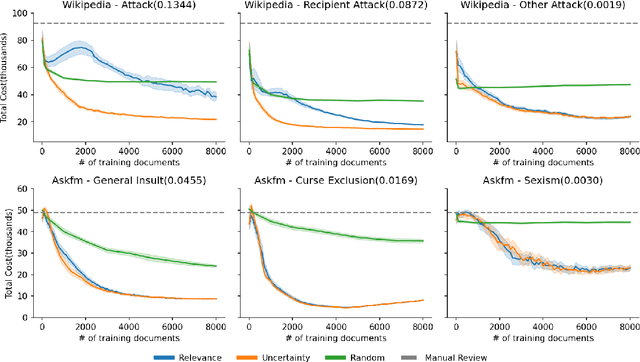
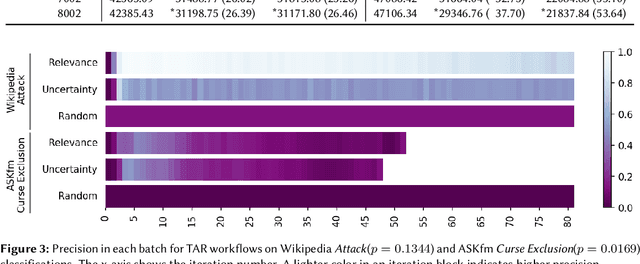
Content moderation (removing or limiting the distribution of posts based on their contents) is one tool social networks use to fight problems such as harassment and disinformation. Manually screening all content is usually impractical given the scale of social media data, and the need for nuanced human interpretations makes fully automated approaches infeasible. We consider content moderation from the perspective of technology-assisted review (TAR): a human-in-the-loop active learning approach developed for high recall retrieval problems in civil litigation and other fields. We show how TAR workflows, and a TAR cost model, can be adapted to the content moderation problem. We then demonstrate on two publicly available content moderation data sets that a TAR workflow can reduce moderation costs by 20% to 55% across a variety of conditions.
Certifying One-Phase Technology-Assisted Reviews
Aug 29, 2021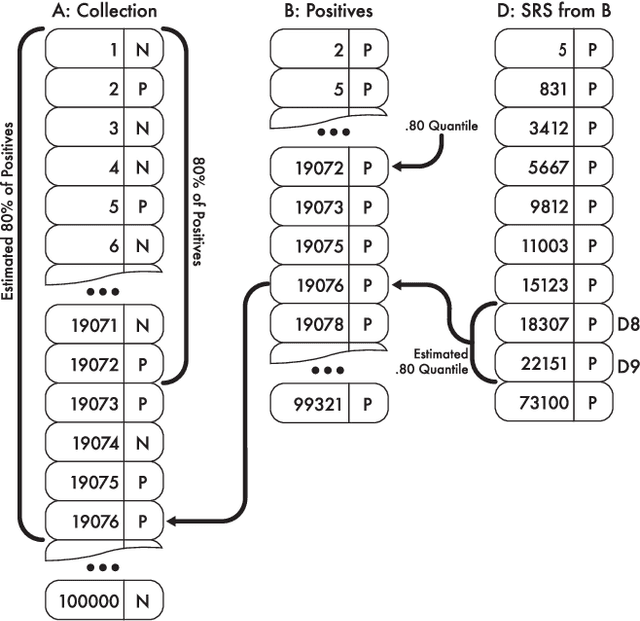
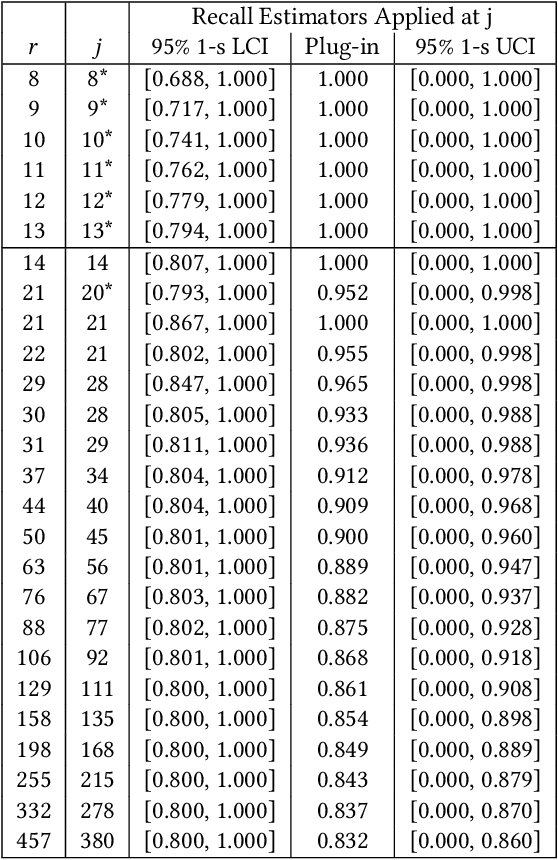
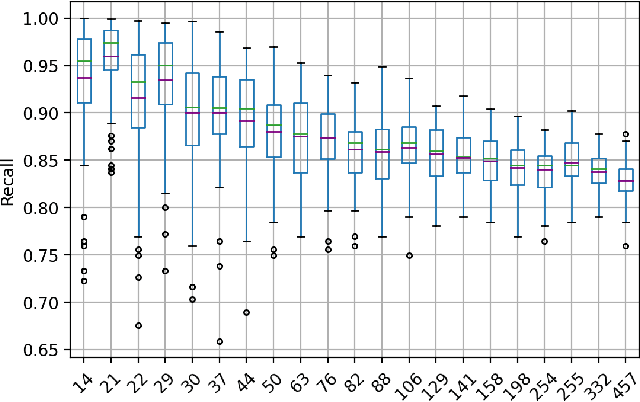
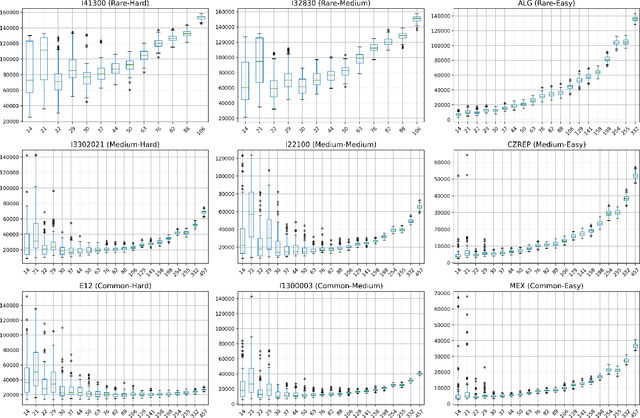
Technology-assisted review (TAR) workflows based on iterative active learning are widely used in document review applications. Most stopping rules for one-phase TAR workflows lack valid statistical guarantees, which has discouraged their use in some legal contexts. Drawing on the theory of quantile estimation, we provide the first broadly applicable and statistically valid sample-based stopping rules for one-phase TAR. We further show theoretically and empirically that overshooting a recall target, which has been treated as innocuous or desirable in past evaluations of stopping rules, is a major source of excess cost in one-phase TAR workflows. Counterintuitively, incurring a larger sampling cost to reduce excess recall leads to lower total cost in almost all scenarios.
Heuristic Stopping Rules For Technology-Assisted Review
Jun 18, 2021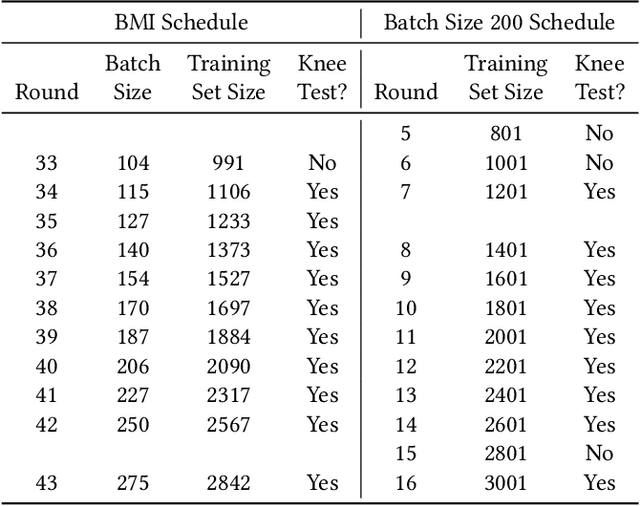
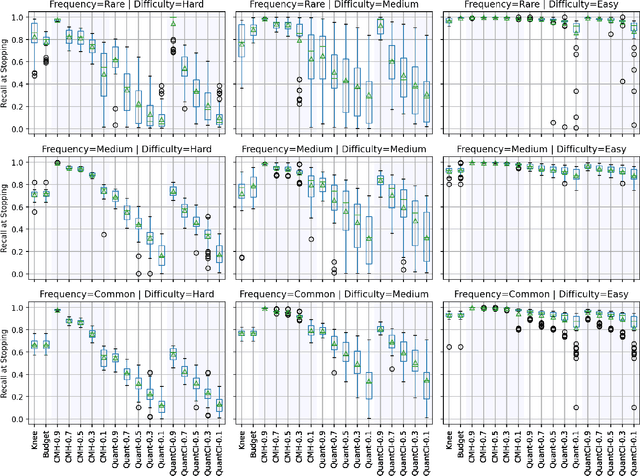
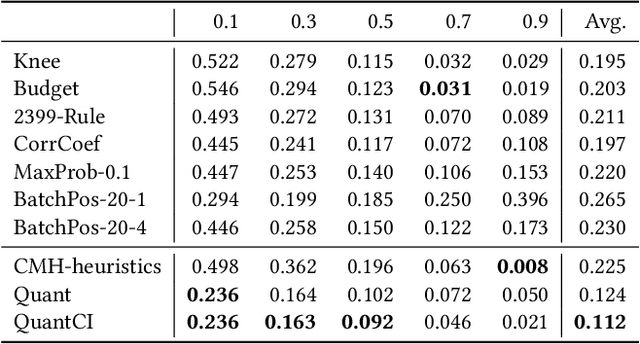
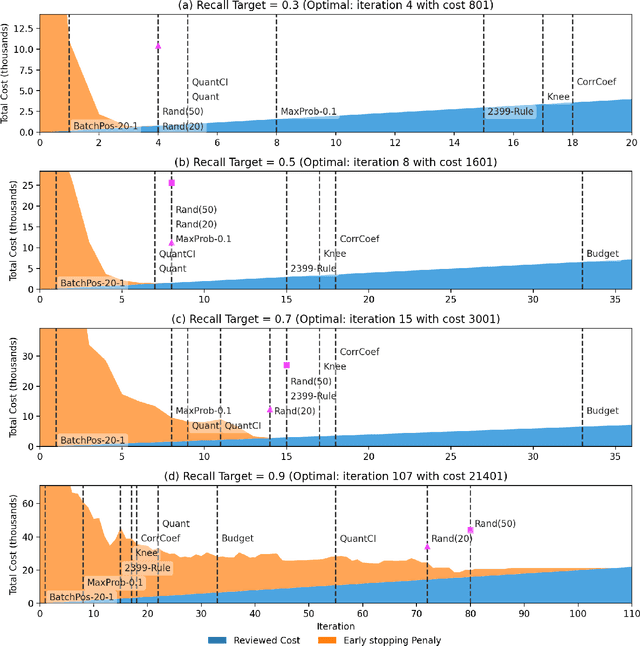
Technology-assisted review (TAR) refers to human-in-the-loop active learning workflows for finding relevant documents in large collections. These workflows often must meet a target for the proportion of relevant documents found (i.e. recall) while also holding down costs. A variety of heuristic stopping rules have been suggested for striking this tradeoff in particular settings, but none have been tested against a range of recall targets and tasks. We propose two new heuristic stopping rules, Quant and QuantCI based on model-based estimation techniques from survey research. We compare them against a range of proposed heuristics and find they are accurate at hitting a range of recall targets while substantially reducing review costs.