 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the Prompt Becomes Visual: Vision-Centric Jailbreak Attacks for Large Image Editing Models
Feb 10, 2026Recent advances in large image editing models have shifted the paradigm from text-driven instructions to vision-prompt editing, where user intent is inferred directly from visual inputs such as marks, arrows, and visual-text prompts. While this paradigm greatly expands usability, it also introduces a critical and underexplored safety risk: the attack surface itself becomes visual. In this work, we propose Vision-Centric Jailbreak Attack (VJA), the first visual-to-visual jailbreak attack that conveys malicious instructions purely through visual inputs. To systematically study this emerging threat, we introduce IESBench, a safety-oriented benchmark for image editing models. Extensive experiments on IESBench demonstrate that VJA effectively compromises state-of-the-art commercial models, achieving attack success rates of up to 80.9% on Nano Banana Pro and 70.1% on GPT-Image-1.5. To mitigate this vulnerability, we propose a training-free defense based on introspective multimodal reasoning, which substantially improves the safety of poorly aligned models to a level comparable with commercial systems, without auxiliary guard models and with negligible computational overhead. Our findings expose new vulnerabilities, provide both a benchmark and practical defense to advance safe and trustworthy modern image editing systems. Warning: This paper contains offensive images created by large image editing models.
CDR-Adapter: Learning Adapters to Dig Out More Transferring Ability for Cross-Domain Recommendation Models
Nov 04, 2023



Data sparsity and cold-start problems are persistent challenges in recommendation systems. Cross-domain recommendation (CDR) is a promising solution that utilizes knowledge from the source domain to improve the recommendation performance in the target domain. Previous CDR approaches have mainly followed the Embedding and Mapping (EMCDR) framework, which involves learning a mapping function to facilitate knowledge transfer. However, these approaches necessitate re-engineering and re-training the network structure to incorporate transferrable knowledge, which can be computationally expensive and may result in catastrophic forgetting of the original knowledge. In this paper, we present a scalable and efficient paradigm to address data sparsity and cold-start issues in CDR, named CDR-Adapter, by decoupling the original recommendation model from the mapping function, without requiring re-engineering the network structure. Specifically, CDR-Adapter is a novel plug-and-play module that employs adapter modules to align feature representations, allowing for flexible knowledge transfer across different domains and efficient fine-tuning with minimal training costs. We conducted extensive experiments on the benchmark dataset, which demonstrated the effectiveness of our approach over several state-of-the-art CDR approaches.
Reinforcement learning for multi-item retrieval in the puzzle-based storage system
Feb 05, 2022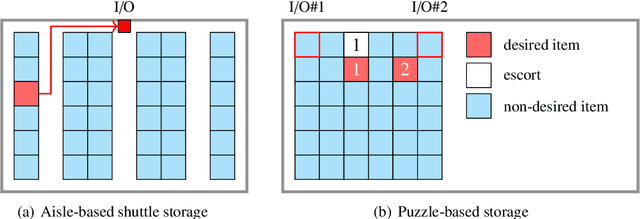
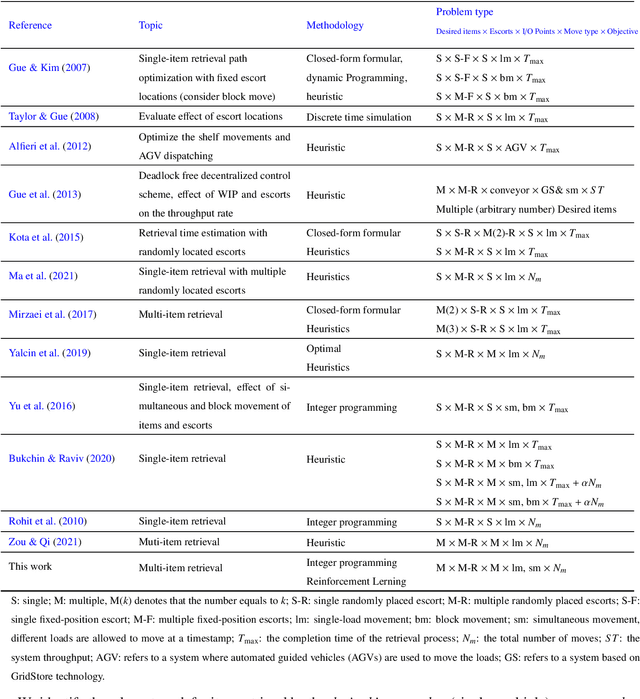
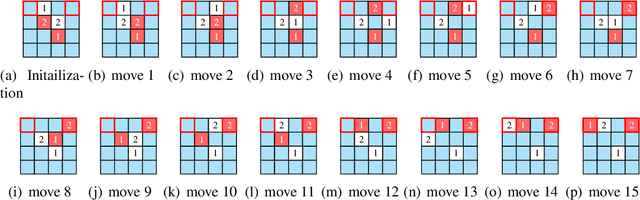
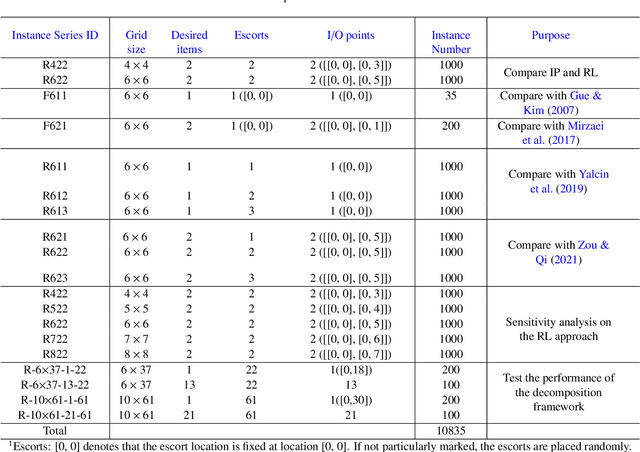
Nowadays, fast delivery services have created the need for high-density warehouses. The puzzle-based storage system is a practical way to enhance the storage density, however, facing difficulties in the retrieval process. In this work, a deep reinforcement learning algorithm, specifically the Double&Dueling Deep Q Network, is developed to solve the multi-item retrieval problem in the system with general settings, where multiple desired items, escorts, and I/O points are placed randomly. Additionally, we propose a general compact integer programming model to evaluate the solution quality. Extensive numerical experiments demonstrate that the reinforcement learning approach can yield high-quality solutions and outperforms three related state-of-the-art heuristic algorithms. Furthermore, a conversion algorithm and a decomposition framework are proposed to handle simultaneous movement and large-scale instances respectively, thus improving the applicability of the PBS system.