 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Bayesian Optimization with $φ$-divergences
Mar 04, 2022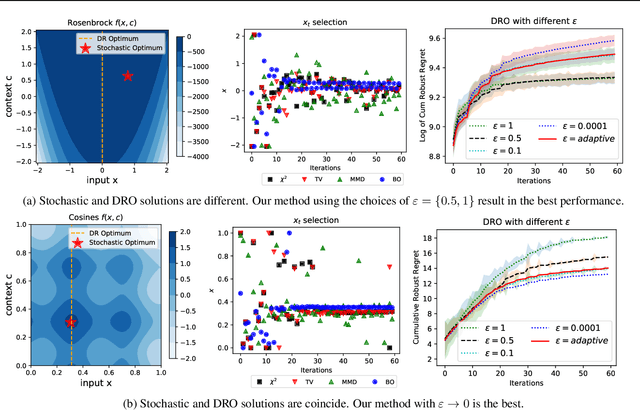
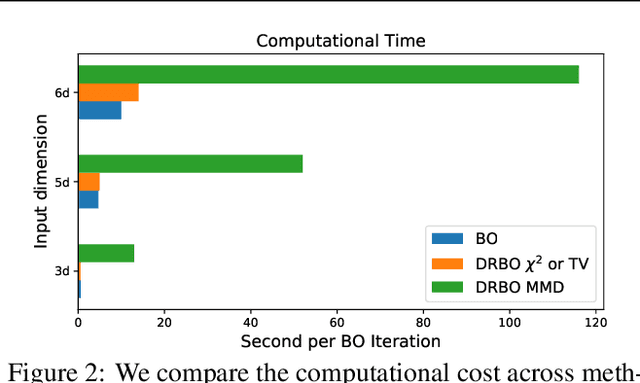
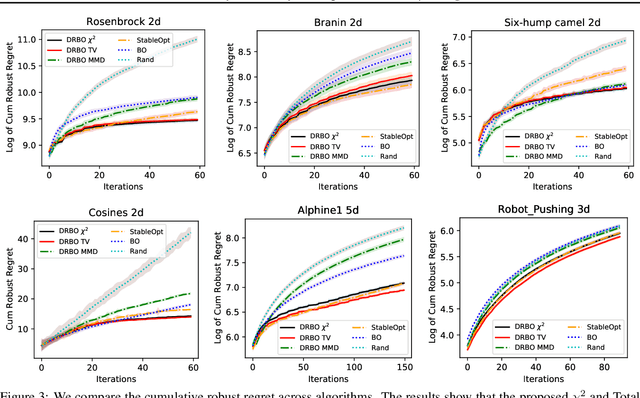
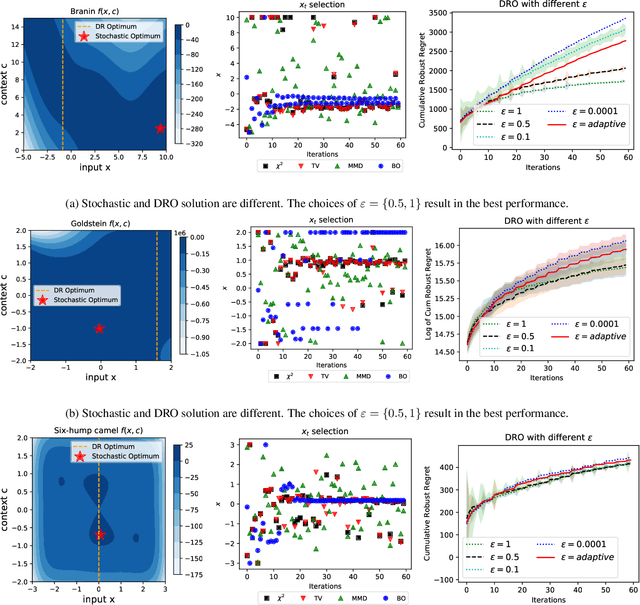
The study of robustness has received much attention due to its inevitability in data-driven settings where many systems face uncertainty. One such example of concern is Bayesian Optimization (BO), where uncertainty is multi-faceted, yet there only exists a limited number of works dedicated to this direction. In particular, there is the work of Kirschner et al. (2020), which bridges the existing literature of Distributionally Robust Optimization (DRO) by casting the BO problem from the lens of DRO. While this work is pioneering, it admittedly suffers from various practical shortcomings such as finite contexts assumptions, leaving behind the main question Can one devise a computationally tractable algorithm for solving this DRO-BO problem? In this work, we tackle this question to a large degree of generality by considering robustness against data-shift in $\phi$-divergences, which subsumes many popular choices, such as the $\chi^2$-divergence, Total Variation, and the extant Kullback-Leibler (KL) divergence. We show that the DRO-BO problem in this setting is equivalent to a finite-dimensional optimization problem which, even in the continuous context setting, can be easily implemented with provable sublinear regret bounds. We then show experimentally that our method surpasses existing methods, attesting to the theoretical results
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022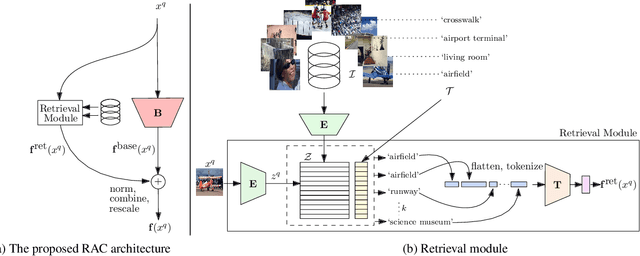
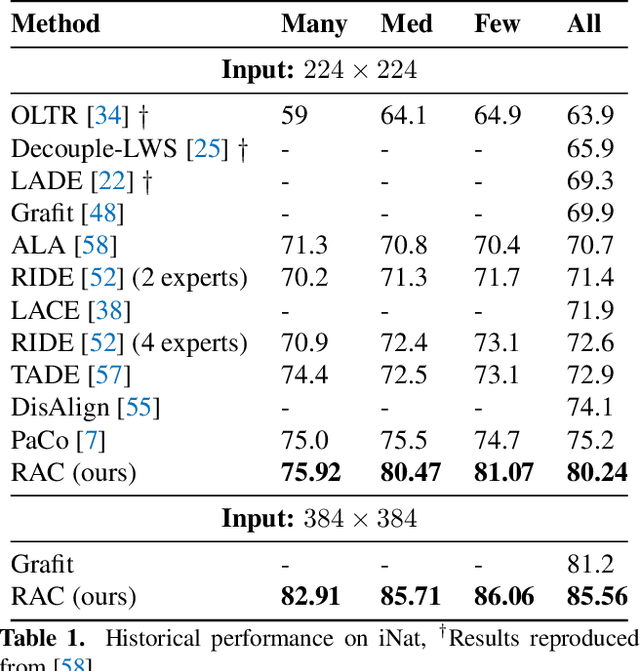
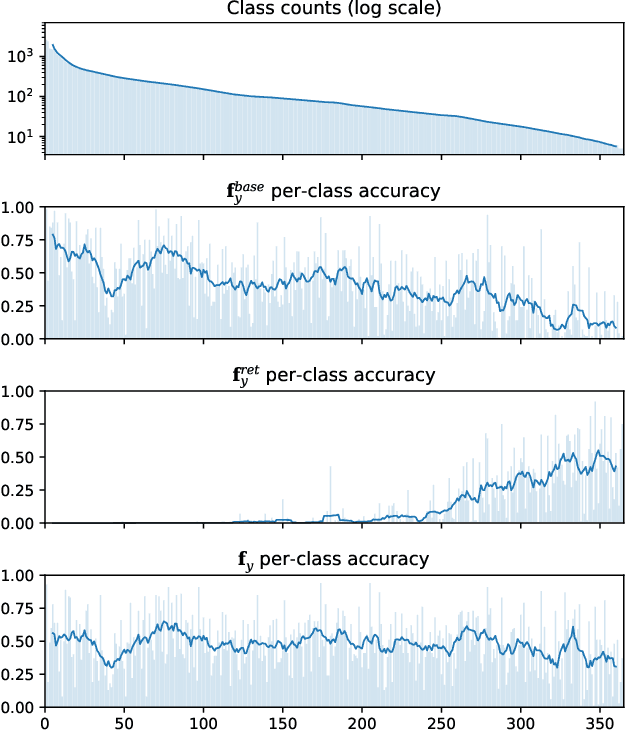
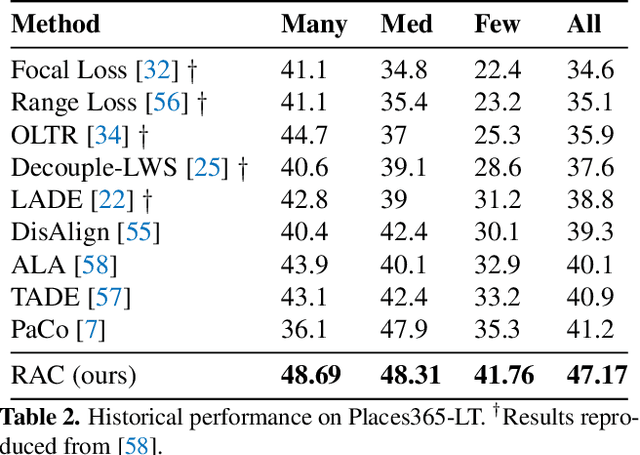
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.
Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
Jan 11, 2022
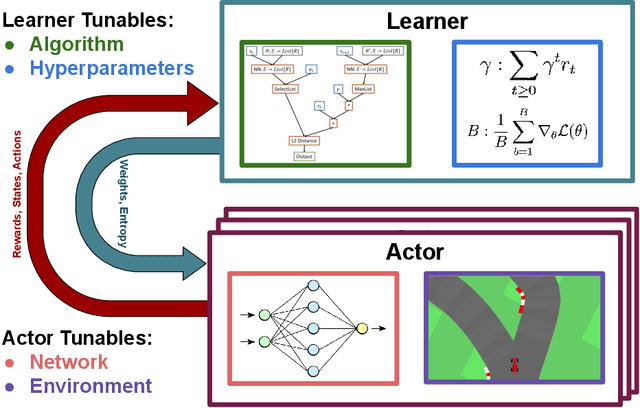
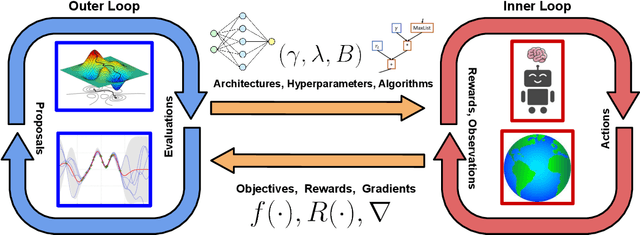

The combination of Reinforcement Learning (RL) with deep learning has led to a series of impressive feats, with many believing (deep) RL provides a path towards generally capable agents. However, the success of RL agents is often highly sensitive to design choices in the training process, which may require tedious and error-prone manual tuning. This makes it challenging to use RL for new problems, while also limits its full potential. In many other areas of machine learning, AutoML has shown it is possible to automate such design choices and has also yielded promising initial results when applied to RL. However, Automated Reinforcement Learning (AutoRL) involves not only standard applications of AutoML but also includes additional challenges unique to RL, that naturally produce a different set of methods. As such, AutoRL has been emerging as an important area of research in RL, providing promise in a variety of applications from RNA design to playing games such as Go. Given the diversity of methods and environments considered in RL, much of the research has been conducted in distinct subfields, ranging from meta-learning to evolution. In this survey we seek to unify the field of AutoRL, we provide a common taxonomy, discuss each area in detail and pose open problems which would be of interest to researchers going forward.
Gaussian Process Sampling and Optimization with Approximate Upper and Lower Bounds
Oct 22, 2021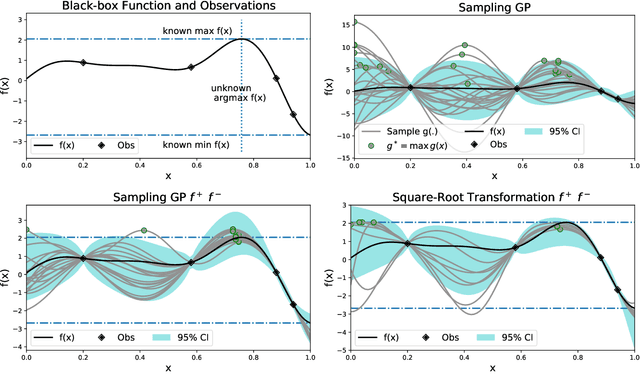
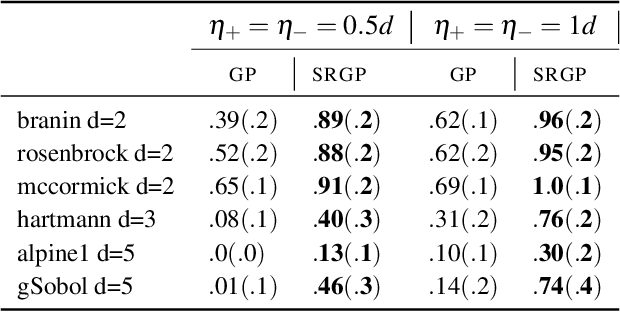
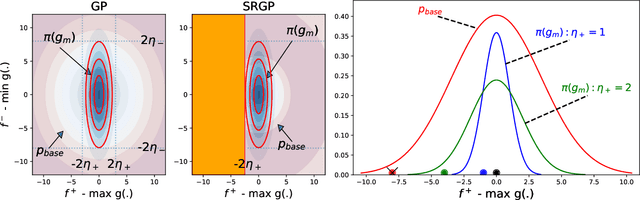
Many functions have approximately-known upper and/or lower bounds, potentially aiding the modeling of such functions. In this paper, we introduce Gaussian process models for functions where such bounds are (approximately) known. More specifically, we propose the first use of such bounds to improve Gaussian process (GP) posterior sampling and Bayesian optimization (BO). That is, we transform a GP model satisfying the given bounds, and then sample and weight functions from its posterior. To further exploit these bounds in BO settings, we present bounded entropy search (BES) to select the point gaining the most information about the underlying function, estimated by the GP samples, while satisfying the output constraints. We characterize the sample variance bounds and show that the decision made by BES is explainable. Our proposed approach is conceptually straightforward and can be used as a plug in extension to existing methods for GP posterior sampling and Bayesian optimization.
Bayesian Topic Regression for Causal Inference
Sep 11, 2021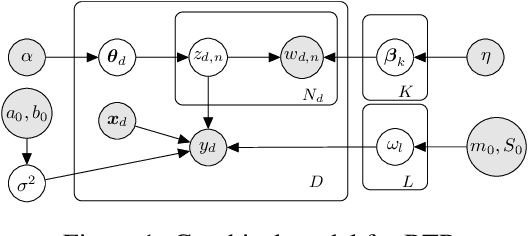
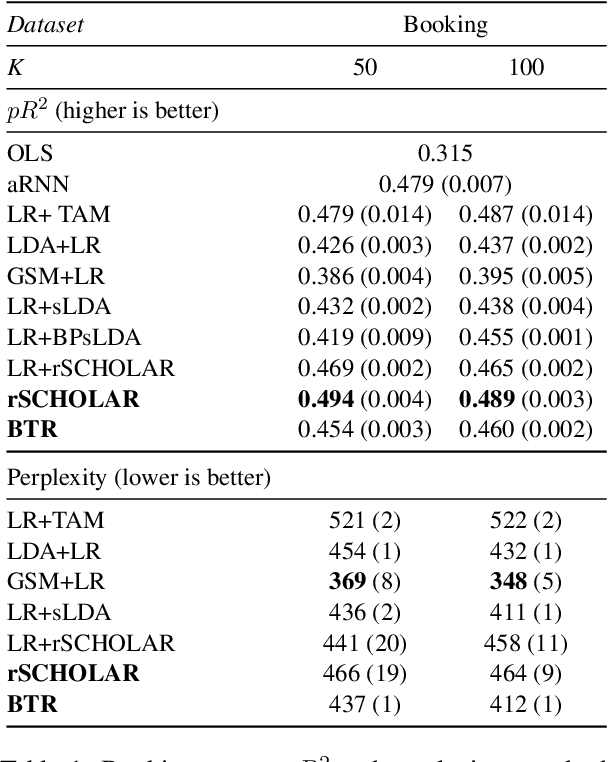
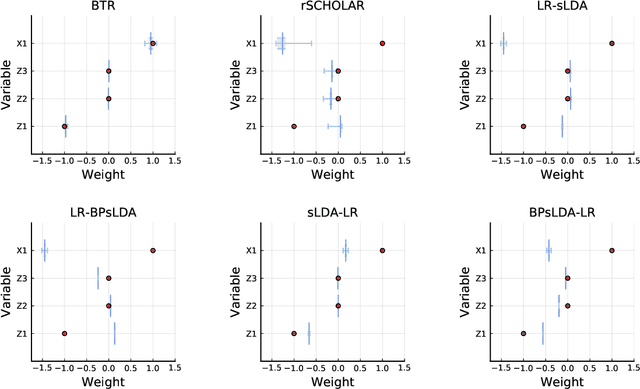
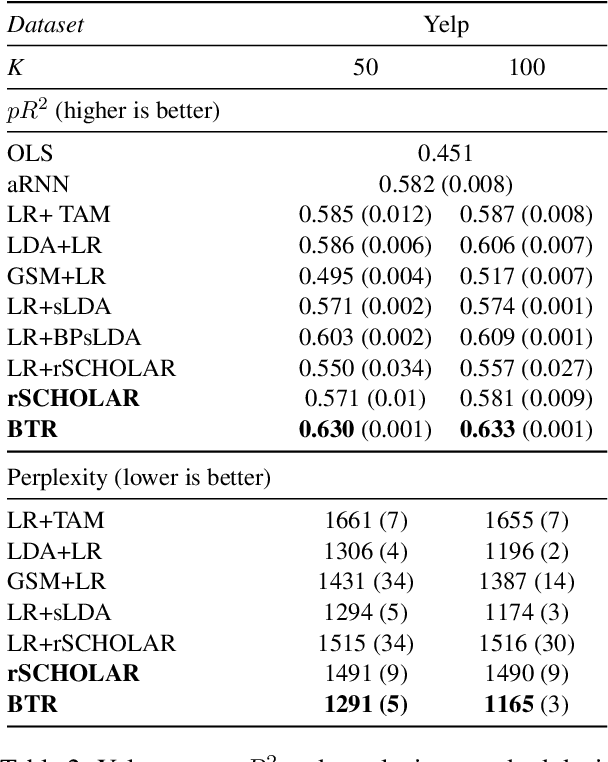
Causal inference using observational text data is becoming increasingly popular in many research areas. This paper presents the Bayesian Topic Regression (BTR) model that uses both text and numerical information to model an outcome variable. It allows estimation of both discrete and continuous treatment effects. Furthermore, it allows for the inclusion of additional numerical confounding factors next to text data. To this end, we combine a supervised Bayesian topic model with a Bayesian regression framework and perform supervised representation learning for the text features jointly with the regression parameter training, respecting the Frisch-Waugh-Lovell theorem. Our paper makes two main contributions. First, we provide a regression framework that allows causal inference in settings when both text and numerical confounders are of relevance. We show with synthetic and semi-synthetic datasets that our joint approach recovers ground truth with lower bias than any benchmark model, when text and numerical features are correlated. Second, experiments on two real-world datasets demonstrate that a joint and supervised learning strategy also yields superior prediction results compared to strategies that estimate regression weights for text and non-text features separately, being even competitive with more complex deep neural networks.
Tuning Mixed Input Hyperparameters on the Fly for Efficient Population Based AutoRL
Jun 30, 2021
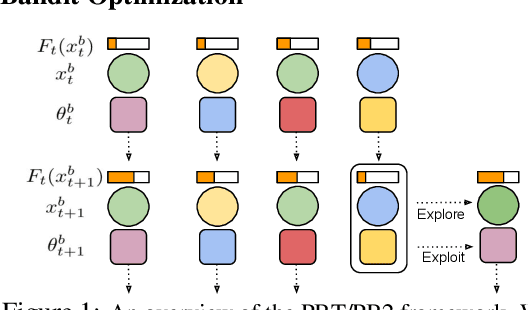
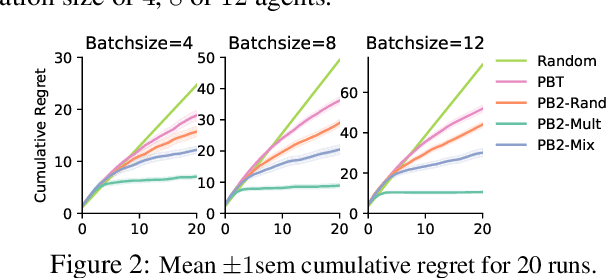
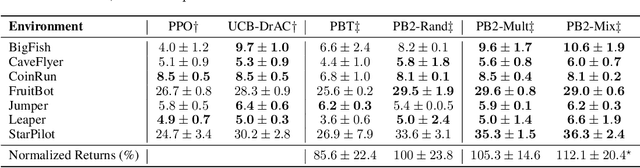
Despite a series of recent successes in reinforcement learning (RL), many RL algorithms remain sensitive to hyperparameters. As such, there has recently been interest in the field of AutoRL, which seeks to automate design decisions to create more general algorithms. Recent work suggests that population based approaches may be effective AutoRL algorithms, by learning hyperparameter schedules on the fly. In particular, the PB2 algorithm is able to achieve strong performance in RL tasks by formulating online hyperparameter optimization as time varying GP-bandit problem, while also providing theoretical guarantees. However, PB2 is only designed to work for continuous hyperparameters, which severely limits its utility in practice. In this paper we introduce a new (provably) efficient hierarchical approach for optimizing both continuous and categorical variables, using a new time-varying bandit algorithm specifically designed for the population based training regime. We evaluate our approach on the challenging Procgen benchmark, where we show that explicitly modelling dependence between data augmentation and other hyperparameters improves generalization.
Think Global and Act Local: Bayesian Optimisation over High-Dimensional Categorical and Mixed Search Spaces
Feb 14, 2021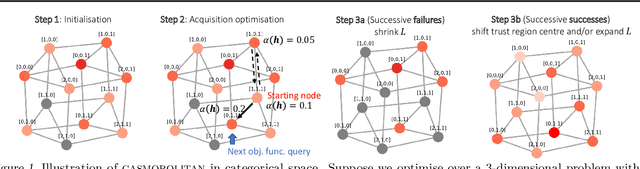

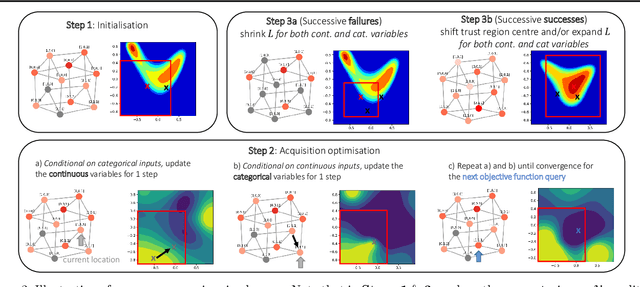
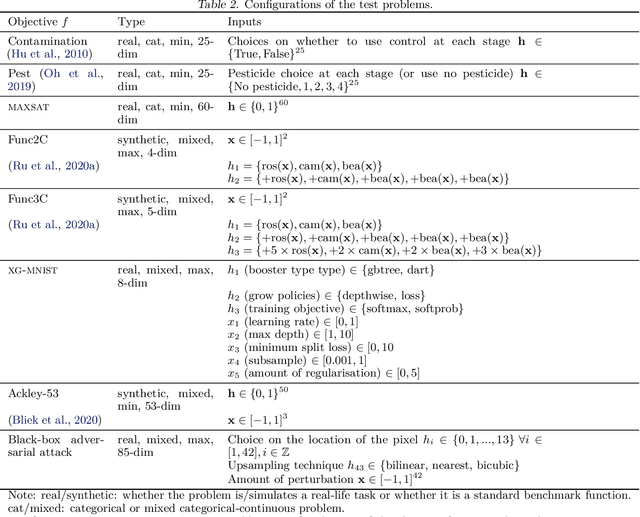
High-dimensional black-box optimisation remains an important yet notoriously challenging problem. Despite the success of Bayesian optimisation methods on continuous domains, domains that are categorical, or that mix continuous and categorical variables, remain challenging. We propose a novel solution -- we combine local optimisation with a tailored kernel design, effectively handling high-dimensional categorical and mixed search spaces, whilst retaining sample efficiency. We further derive convergence guarantee for the proposed approach. Finally, we demonstrate empirically that our method outperforms the current baselines on a variety of synthetic and real-world tasks in terms of performance, computational costs, or both.
Gaussian Process Bandit Optimization of the Thermodynamic Variational Objective
Oct 31, 2020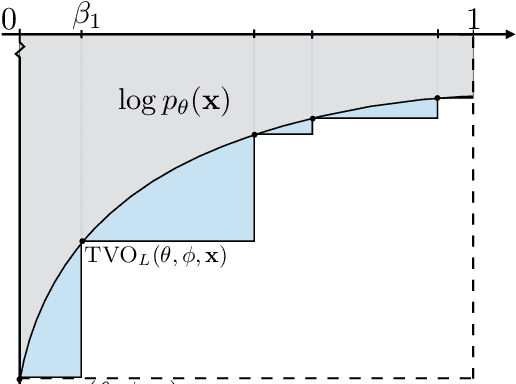

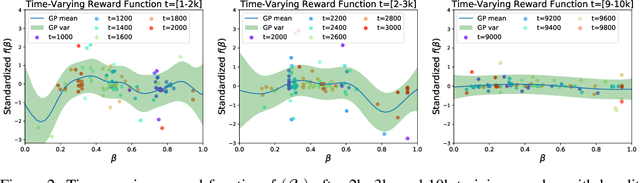

Achieving the full promise of the Thermodynamic Variational Objective (TVO), a recently proposed variational lower bound on the log evidence involving a one-dimensional Riemann integral approximation, requires choosing a "schedule" of sorted discretization points. This paper introduces a bespoke Gaussian process bandit optimization method for automatically choosing these points. Our approach not only automates their one-time selection, but also dynamically adapts their positions over the course of optimization, leading to improved model learning and inference. We provide theoretical guarantees that our bandit optimization converges to the regret-minimizing choice of integration points. Empirical validation of our algorithm is provided in terms of improved learning and inference in Variational Autoencoders and Sigmoid Belief Networks.
Optimal Transport Kernels for Sequential and Parallel Neural Architecture Search
Jun 13, 2020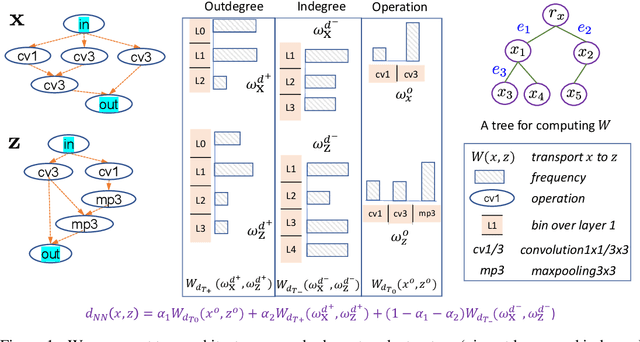
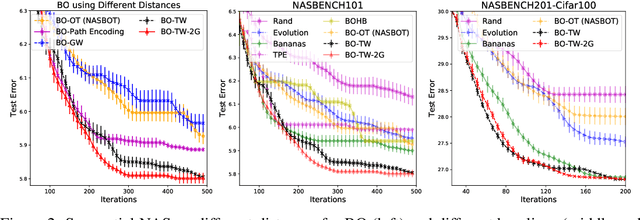

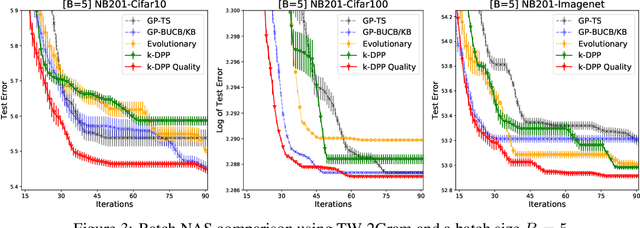
Neural architecture search (NAS) automates the design of deep neural networks. One of the main challenges in searching complex and non-continuous architectures is to compare the similarity of networks that the conventional Euclidean metric may fail to capture. Optimal transport (OT) is resilient to such complex structure by considering the minimal cost for transporting a network into another. However, the OT is generally not negative definite which may limit its ability to build the positive-definite kernels required in many kernel-dependent frameworks. Building upon tree-Wasserstein (TW), which is a negative definite variant of OT, we develop a novel discrepancy for neural architectures, and demonstrate it within a Gaussian process surrogate model for the sequential NAS settings. Furthermore, we derive a novel parallel NAS, using quality k-determinantal point process on the GP posterior, to select diverse and high-performing architectures from a discrete set of candidates. Empirically, we demonstrate that our TW-based approaches outperform other baselines in both sequential and parallel NAS.
Incorporating Expert Prior Knowledge into Experimental Design via Posterior Sampling
Feb 26, 2020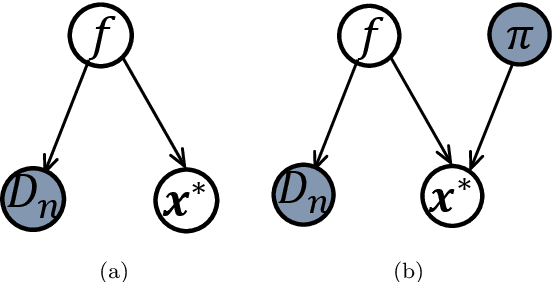
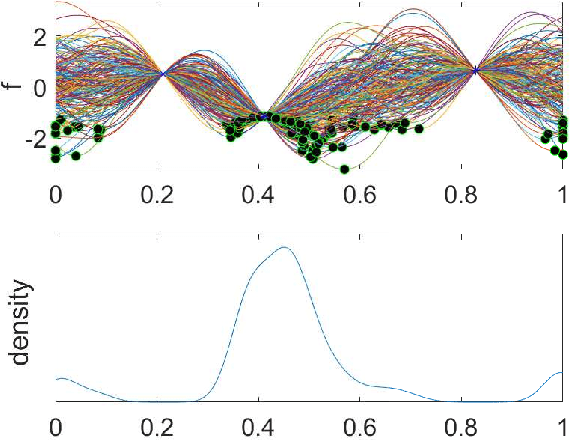
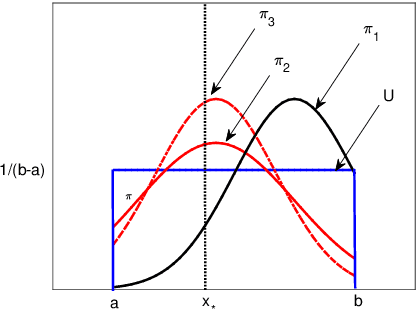
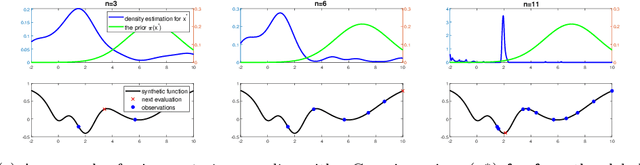
Scientific experiments are usually expensive due to complex experimental preparation and processing. Experimental design is therefore involved with the task of finding the optimal experimental input that results in the desirable output by using as few experiments as possible. Experimenters can often acquire the knowledge about the location of the global optimum. However, they do not know how to exploit this knowledge to accelerate experimental design. In this paper, we adopt the technique of Bayesian optimization for experimental design since Bayesian optimization has established itself as an efficient tool for optimizing expensive black-box functions. Again, it is unknown how to incorporate the expert prior knowledge about the global optimum into Bayesian optimization process. To address it, we represent the expert knowledge about the global optimum via placing a prior distribution on it and we then derive its posterior distribution. An efficient Bayesian optimization approach has been proposed via posterior sampling on the posterior distribution of the global optimum. We theoretically analyze the convergence of the proposed algorithm and discuss the robustness of incorporating expert prior. We evaluate the efficiency of our algorithm by optimizing synthetic functions and tuning hyperparameters of classifiers along with a real-world experiment on the synthesis of short polymer fiber. The results clearly demonstrate the advantages of our proposed method.